Todo mundo já se complicou tentando fazer uma tabela dinâmica (pivot table) fora do Excel. No Python, você não precisa criar uma função ou fazer algum tipo de manipulação com a tabela para chegar numa visão semelhante ao que fazemos nas tabelas dinâmicas do Excel. Vamos entender então como utilizar a função pivot_table – se você estiver iniciando e não sabe ainda o que é uma tabela dinâmica, recomendo que vá ao Youtube, faça uma pesquisa rápida e volte em seguida.
Ao invés de construirmos um conjunto de dados para trabalharmos em cima, vamos utilizar os dados de uma base com o desempenho dos estudantes (aka suas notas). A base pode ser baixada clicando aqui. Primeiro, vamos importar a base já no formato de um DataFrame:
# carrega biblioteca
import pandas as pd
# carrega os dados
StudentsPerformance = pd.read_csv('StudentsPerformance.csv')
# verifica algumas linhas
StudentsPerformance.head()
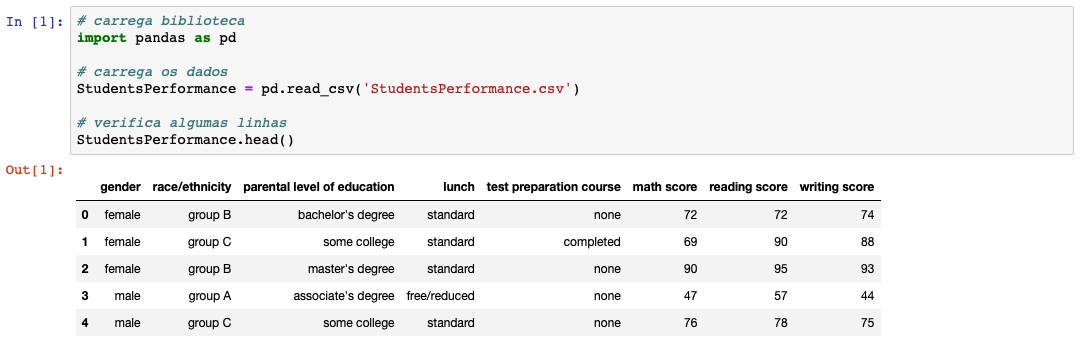
Temos varias variáveis aí, como: gênero (feminino / masculino), raça (grupos A, B, C, …), nível de educação dos pais, almoço (padrão, reduzido), curso preparatório para o teste (completou ou não), etc. Primeiro, somente para que o leitor saiba como fazer, é possível obter algumas descritivas deste data frame de diferentes maneiras, aqui vai uma forma:
# estatistica descritiva das notas print(StudentsPerformance.describe()) # frequencia das variaveis categoricas print(StudentsPerformance[['gender','race/ethnicity','parental level of education','lunch','test preparation course']].apply(lambda x: x.value_counts()).T.stack())
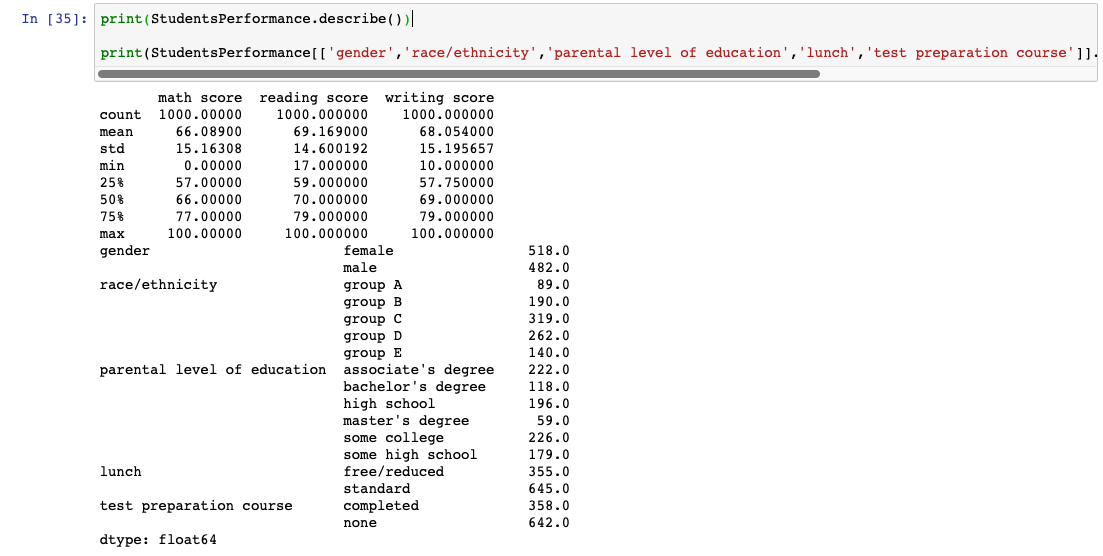
Novamente, o print() serve somente para que a saída das duas linhas apareça. Não é necessário usá-lo sempre.
Agora, vamos pensar numa análise univariada, bem simples. Por exemplo, você quer saber se a nota média de matemática varia de acordo com o gênero. Isto é, testar a máxima de que meninos possuem notas melhores em matemática do que meninas. Para isso, você pode fazer a pivot table (ou tabela dinâmica) mais simples que existe:
pd.pivot_table(StudentsPerformance,index=["gender"])

Claro, aos que estão acostumados com o groupby, sim, também é possível utilizá-lo e obter o mesmo resultado:
StudentsPerformance.groupby('gender').mean()
Para ambos os casos, é possível obter somente a média das notas de matemática:
# so math score na pivot table
pd.pivot_table(StudentsPerformance, index=["gender"], values = ['math score'])
# so math score no group by
StudentsPerformance.groupby('gender').mean()['math score']
Note que agora você já sabe que o argumento index da função pivot_table serve para se referir aos índices e o values os valores para cada índice. Se você quiser, você pode incluir quantas variáveis quiser para qualquer um dos dois na sua pivot table, basta acrescentar uma vírgula e o nome da variável.
Mas e se você quiser trazer a soma ao invés da média? Bom, para o groupby você só precisa trocar o sum por mean. Na pivot table, você pode fazer uso das funções do pacote Numpy:
import numpy as np pd.pivot_table(StudentsPerformance, index=["gender"], values=['math score'], aggfunc=[np.sum])

Pelos valores da média, você inicialmente acreditaria que os meninos vão melhores em matemática. Claro, deveríamos fazer outros testes estatísticos para verificar se a diferença é significativa, mas sigamos.
Imagine agora que você não acredita neste resultado, poderia muito bem ser algo como o Paradoxo de Simpson. Por isso, agora resolve fazer uma análise bivariada (ou multivariada) e, além de querer saber a média por gênero, você quer ver a média por nível de educação dos pais. Você quer organizar sua tabela de forma que fique uma matriz cruzada onde os gêneros formam os índices das linhas e o nível de educação dos pais os das colunas. Agora sim, o legal é utilizar uma pivot table. A sintaxe da Pivot Table parece confusa no começo, mas logo você se acostuma. Veja no nosso exemplo:
import pandas as pd import numpy as np pd.pivot_table(StudentsPerformance,index=['gender'],values=['math score'], columns=['parental level of education'],aggfunc=[np.mean])
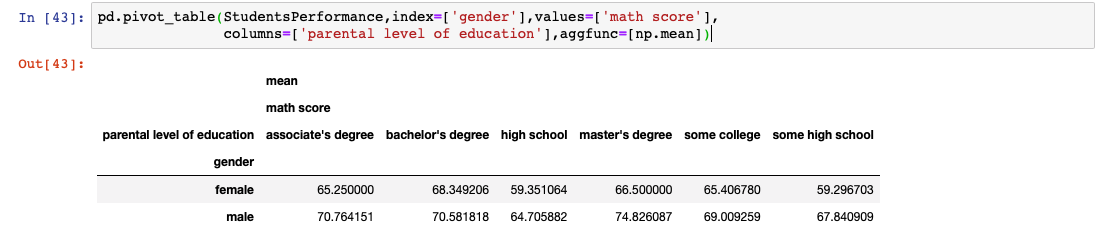
Agora, você tem uma matriz cruzada formada pelo gênero x nível de educação dos pais. Essa visibilidade é muito mais completa e coerente com a realidade, onde temos várias variáveis causando algum fenômeno.
Eu gostei bastante desta base, por ser bastante similar ao que vemos em microeconomia/microeconometria. Sugiro fortemente que o leitor faça alguns testes incluindo mais variáveis e tentando entender a saída. É possível fazer mais coisas com a base, regressões e outras coisas mais. Fica como lição de casa.
E se você gostou do post, não vá embora sem deixar uma curtida ou um comentário. Dá bastante trabalho fazer o conteúdo do blog e o feedback de quem lê é muito motivador. Se encontrou algum erro ou tem alguma sugestão, dúvida, elogio ou crítica, pode escrever nos comentários ou me enviar uma mensagem diretamente em Sobre o Estatsite. E visite também a conta do Twitter @EstatSite.
Forte abraço e bons estudos!
Boa Noite. Percebi que quando cria um pivot_table, a média que aparece é diferente da média dos valores individuais na tabela.
Boa noite,
Que estranho. Vou refazer os exemplos amanhã cedo para validar.
Abraços
Olá, testei aqui no Numbers e deu certo. De qual média você está falando?