Eu já mostrei uma vez como testar diversos algoritmos numa tacada só no Python utilizando um simples loop e o pipeline do Scikit-Learn. Hoje, descobri outra coisa interessante, que já há um pacote que faz isso. É menos flexível do que a ideia que eu usava, mas é muito prático, afinal, você vai estar testando vários modelos numa tacada só – no Python, claro! Isso mesmo, mais de 20 modelos com somente 3 linhas de código. Bora aprender como fazer isso!
TESTANDO MODELOS COM LOOP + PIPELINE
Primeiramente, deixe eu mostrar para vocês como eu costumo testar diferentes algoritmos e tentar construir vários modelos de uma só vez. O contexto todo você pode verificar neste notebook aqui. A ideia é simples, criei uma lista com os algoritmos e inseri essa lista no pipeline:
from sklearn.metrics import accuracy_score, log_loss from sklearn.neighbors import KNeighborsClassifier from sklearn.svm import SVC, LinearSVC, NuSVC from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import ( RandomForestClassifier, AdaBoostClassifier, GradientBoostingClassifier, ) from sklearn.discriminant_analysis import LinearDiscriminantAnalysis from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis from sklearn.linear_model import LogisticRegression classifiers = [ KNeighborsClassifier(3), SVC(kernel="rbf", C=0.025, probability=True), SVC(), LogisticRegression(), DecisionTreeClassifier(), RandomForestClassifier(), AdaBoostClassifier(), GradientBoostingClassifier(), ] for classifier in classifiers: pipe = Pipeline(steps=[("preprocessor", preprocessor), ("classifier", classifier)]) pipe.fit(X_train, y_train) print(classifier) print("model score: %.3f" % pipe.score(X_test, y_test))
Obviamente, apesar de estar testando classificadores, você pode utilizar a mesma lógica para regressão. É possível também printar outras coisas que você queira saber, ou até criar uma lista para armazenar as informações. Eu optei por somente exibir algumas informações que eu precisava.
O PACOTE LAZY PREDICT
O exemplo acima é muito bom, mas eu descobri um pacote que faz algo muito próximo ao item anterior: o LAZY PREDICT. Ele é bem interessante e serve justamente para testar diferentes algoritmos nos seus datasets. Se quiser saber mais sobre ele, ir além do que vou mostrar a seguir, a página oficial é essa aqui. Em suma, você só precisa passar o seu treino e teste que o modelo irá “cuspir” as predições e cada um dos algoritmos testados.
EXEMPLO PRÁTICO
O exemplo aqui foi feito com um dataset bem popular, o german credit data. Neste problema, um banco nos passou as informações históricas dos clientes e se o cliente é de alto ou baixo risco (i.e., se ele pagou ou não suas dívidas – coluna Risk). A ideia é simples, você tem um histórico de pessoas com algumas características e sabe que umas pagam as dívidas e outras não. Seu modelo terá que identificar o padrão de quem é o mau pagador, para que assim o banco não leve muito prejuízo. Para baixar o dataset, acesse aqui.
Começamos carregando as bibliotecas necessárias e os dados:
# carrega as bibliotecas necessarias
import pandas as pd
import numpy as np
import lazypredict
from lazypredict.Supervised import LazyClassifier
from sklearn.model_selection import train_test_split
# carrega os dados
df = pd.read_csv('german_credit_data.csv')
df.head()

Em seguida, vamos trocar a coluna Risk por uma dummy:
df['Risk']=np.where(df['Risk']=='bad',1,0)
Agora, temos nossos dados já prontos. Não vou fazer muitas tratativas aqui, pois já fiz outras vezes e não é o foco do post. Se quiser saber como lidar com isso, você pode ir no vídeo Machine Learning do Zero em Python. Sendo assim, facilitamos filtrando só algumas colunas e, na sequência, dividimos em treino e teste:
# seleciona as features e variavel target X = df[['Age', 'Credit amount', 'Duration']] y = df['Risk'] # divide em treino e teste X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state=999)
Pronto, já temos nossos dados prontinhos para testar os algoritmos. Veja que simples é utilizar o Lazy Predict, só precisamos passar os datasets de treino e teste que a função LazyClassifier resolve o resto:
clf = LazyClassifier(verbose=0,ignore_warnings=True) models, predictions = clf.fit(X_train, X_test, y_train, y_test) models
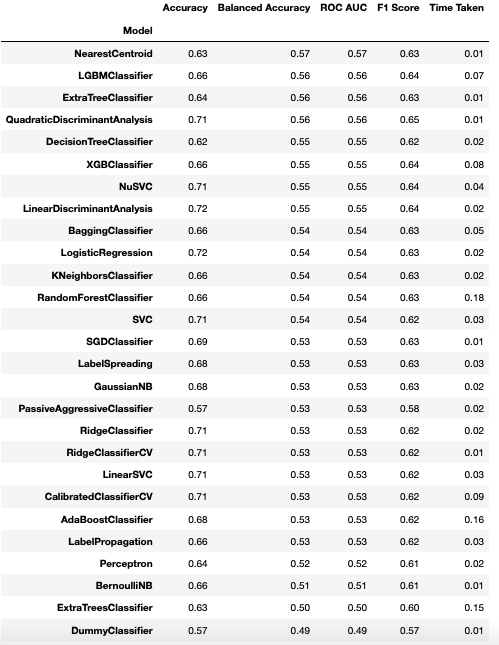
E se o problema for de regressão?
Dá na mesma, só muda a função. Veja o esqueleto do script:
from lazypredict.Supervised import LazyRegressor reg = LazyRegressor(verbose=0, ignore_warnings=False, custom_metric=None) models, predictions = reg.fit(X_train, X_test, y_train, y_test) models
Agora, o negócio é sair testando seus vários modelos com somente 3 linhas, numa tacada só, no Python!
GOSTOU? DÁ UMA MORAL PARA O BLOG!
E aí? Gostou do conteúdo? Se inscreva para receber todas as novidades. Deixe seu e-mail em INSCREVA-SE na barra à direita, logo abaixo de pesquisar. E, por favor, não deixe de comentar, dar seu feedback e, principalmente, compartilhar com seus amigos. De verdade, isso faz toda a diferença. Além disso, você também pode acompanhar mais do meu trabalho seguindo a conta de Twitter @UniDosDados ou por alguma das redes que você encontra em Sobre o Estatsite / Contato, como meu canal de Youtube Canal Universidade dos Dados. E se você gosta de tecnologia, escute o podcast Futuristando!
Bons estudos!