Assim como aprendemos no SQL, ou qualquer linguagem para manipulação de bases de dados, como unir bases de dados de diferentes maneiras, o Pandas nos permite fazer estas tratativas no Python. Abaixo, vamos aprender como fazer as uniões de tabelas e algumas táticas que podem facilitar sua vida.
INTRODUÇÃO
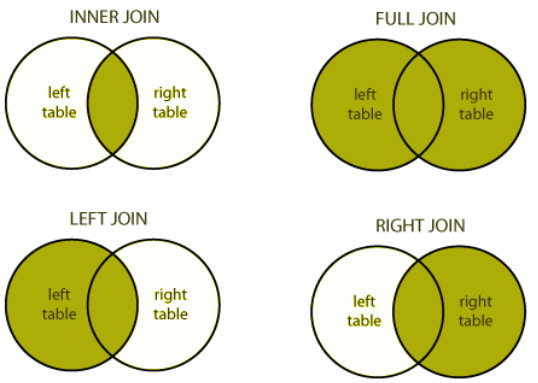
Para ajudar no entendimento do que será feito, veja a figura abaixo. Nela, você consegue visualizar o que significa cada um dos joins. Por exemplo, o full join é a união das duas tabelas. Já o left join, é quando você traz informações de algumas colunas de uma segunda tabela para a primeira tabela. Caso o desenho ainda não esclareça, não se preocupe, os exemplos práticos darão mais uma ajudinha.
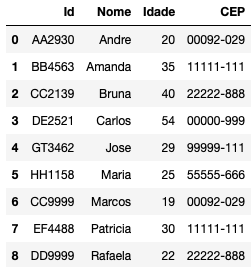
Antes de entrar nos joins, vamos construir alguns datasets para serem usados de exemplos. Vamos supor que você trabalhe numa companhia que vende eletrodomésticos. Você possui as informações de clientes que foram até a loja A e realizaram o cadastro em algum momento, também possui informações de clientes que se cadastraram na loja B e possui uma terceira base com todas informações de compras já feitas em qualquer uma das duas lojas:
import pandas as pd
# Cadastro da loja a
cadastro_a = {'Id': ['AA2930','BB4563','CC2139','DE2521','GT3462','HH1158'],
'Nome': ['Andre', 'Amanda', 'Bruna', 'Carlos', 'Jose', 'Maria'],
'Idade': [20,35,40,54,29,25],
'CEP': ['00092-029','11111-111','22222-888','00000-999','99999-111','55555-666']
}
cadastro_a = pd.DataFrame(cadastro_a, columns = ['Id','Nome','Idade','CEP'])
print(cadastro_a)
# Cadastro da loja b
cadastro_b = {'Id': ['CC9999','EF4488','DD9999','GT3462','HH1158'],
'Nome': ['Marcos', 'Patricia', 'Rafaela', 'Jose', 'Maria'],
'Idade': [19,30,22,29,25],
'CEP': ['00092-029','11111-111','22222-888','99999-111','55555-666']
}
cadastro_b = pd.DataFrame(cadastro_b, columns = ['Id','Nome','Idade','CEP'])
print(cadastro_b)
# Registro de compras de todas unidades
compras = {'Id': ['AA2930','EF4488','CC2139','EF4488','CC9999','AA2930','HH1158','HH1158'],
'Data': ['2019-01-01','2019-01-30','2019-01-30','2019-02-01','2019-02-20','2019-03-15','2019-04-01','2019-04-10'],
'Valor': [200,100,40,150,300,25,50,500]
}
compras = pd.DataFrame(compras, columns = ['Id','Data','Valor'])
print(compras)
As informações podem ser vistas abaixo:

Você vai ver que este tipo de arranjo é comum em qualquer empresa. A primeira tabela no canto superior esquerdo possui as informações cadastrais dos clientes que em algum momento foram até a loja A e fizeram seu cadastro; enquanto a segunda tabela, no canto superior direito, possui as informações de todos os clientes que já foram até a loja B e realizaram seu cadastro; já a terceira tabela, na parte inferior, é uma base com o histórico de todas as compras feitas em qualquer loja que faça parte da rede da companhia. Seja para fazer um modelo ou uma análise exploratória em que se busque entender como gastam os clientes de acordo com a localização ou a idade, unir as tabelas será essencial.
A SINTAXE DO MERGE
O merge da biblioteca Pandas é bem intuitivo. Em suma, você precisa fornecer as duas bases, indicar qual coluna deve ser utilizada para unir – i.e., qual coluna as duas tabelas possuem em comum – e qual o tipo de join a ser feito:
pd.merge(tabela_da_esquerda, tabela_da_direita, on="coluna_coincidente", how="left|right|inner|outer)
Havendo mais de uma coluna que você queira utilizar para unir as tabelas (veremos exemplos mais abaixo):
pd.merge(tabela_da_esquerda, tabela_da_direita, on=["coluna_1","coluna_2"], how="left|right|inner|outer")
Caso os nomes das colunas utilizadas para a união sejam diferentes, você pode indicar o nome que a coluna coincidente possui na tabela da esquerda com o LEFT_ON e o nome que ela possui na tabela da direita com o RIGHT_ON, ao invés de utilizar somente o ON.
pd.merge(tabela_da_esquerda, tabela_da_direita, right_on=["coluna_direita_1","coluna_direita_2"], left_on=["coluna_esquerda_1","coluna_esquerda_2"], how="left|right|inner|outer")
INNER JOIN (+ ALTERAÇÃO NOS NOMES DAS COLUNAS)
Suponha que a loja A e B sejam marcas diferentes dentro da rede de marcas da companhia. Você quer saber quais clientes frequentam tanto a loja A quanto a loja B. Ou seja, você quer a intersecção das duas tabelas de cadastro. Neste caso, você deve utilizar a função pd.merge() com o argumento how=’inner’. Como aqui não importa qual tabela recebe a informação, vamos colocar a tabela da direita como sendo o cadastro da loja A:
pd.merge(cadastro_a, cadastro_b, on=["Id"], how="inner")

Temos somente o José e a Maria cadastrados nas duas lojas. Veja que trouxemos todas as informações das duas tabelas. Vamos supor que você só estivesse fazendo isso para verificar se o cadastro dos dois estava igual. Ou seja, você quisesse trazer somente as informações de idade e CEP do cadastro da loja B. Neste caso, faça o join com a base de cadastro da loja B filtrada com as colunas que você quer:
pd.merge(cadastro_a, cadastro_b[['Id','Idade','CEP']], on=["Id"], how="inner")

Você pode também alterar o sufixo das colunas coincidentes. Veja que por padrão, a função altera os nomes para ‘_x’ e ‘_y’. Mas existe o argumento suffixes para a função merge que faz as alterações que você deseja:
pd.merge(cadastro_a, cadastro_b[['Id','Idade','CEP']], on=["Id"], how="inner", suffixes=('_A','_B'))

E existe, é claro, a opção de renomear toda a tabela:
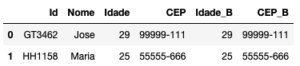
inner_join = pd.merge(cadastro_a, cadastro_b[['Id','Idade','CEP']], on=["Id"], how="inner") inner_join.columns = ['Id', 'Nome', 'Idade', 'CEP', 'Idade_B', 'CEP_B'] inner_join
FULL JOIN
Agora, seu empregador pode querer ter uma base com todos os clientes de todas as lojas da companhia. Ou seja, você vai precisar unir as tabelas de cadastro da loja A e da loja B. Isso se resolve com um full join do nosso diagrama. Porém, note que não há nada de full join na sintaxe. O outer é parecido, mas não exatamente isso. O que podemos fazer aqui é usar a função concat:
pd.concat([cadastro_a,cadastro_b],ignore_index=True)
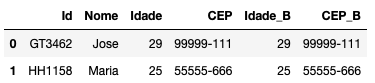
Note que José e Maria foram duplicados. Você pode resolver isso tirando a duplicidade com a função drop_duplicates:
empilhado = pd.concat([cadastro_a,cadastro_b],ignore_index=True) empilhado.drop_duplicates(subset="Id")
LEFT JOIN
Agora, uma outra pedida – talvez a que eu mais tenha observado ao longo do tempo – é a de trazer informação de uma tabela para outra. Por exemplo, o gerente da loja A quer saber quais os clientes que fizeram compras na loja e o valor gasto. Para isso, você precisa trazer as informações da terceira tabela do nosso exemplo para a primeira, utilizando o left join:
pd.merge(cadastro_a, compras, how="left", on=["Id"])
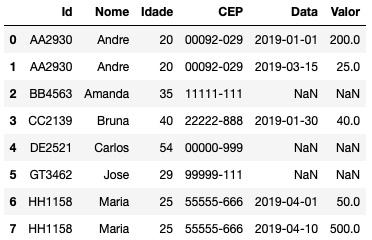
Agora temos as informações das compras feitas e quais os valores gastos em cada uma. Caso você queira saber o total gasto, você pode aplicar o groupby (use a função pd.DataFrame se quiser o resultado no formato inicial das tabelas):
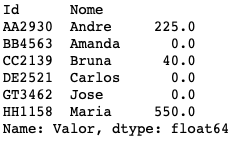
left=pd.merge(cadastro_a, compras, how="left", on=["Id"]) left.groupby(['Id','Nome'])['Valor'].sum()
O caso do right_join é análogo ao left_join, então vou fazer como os livros de Cálculo e deixar a cargo do leitor.
MAS E O OUTER?
O outer join é bem semelhante ao que fizemos no full join. Porém, não me agrada tanto quando queremos somente empilhar as colunas porque ele acaba tratando colunas de mesmo nome como sendo diferentes só pelo fato de vir de tabelas diferentes. Veja o que acontece com um outer join para as tabelas A e B:
pd.merge(cadastro_a, cadastro_b, how="outer", on=["Id"])
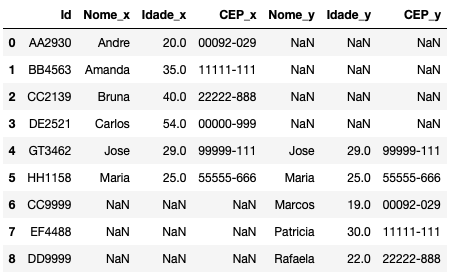
O ideal seria utilizar o outer para colunas distintas. Quando temos colunas idênticas, o concat é melhor – ao menos é o que me parece até o momento.
Há um argumento interessante para saber se foi utilizado somente a coluna da esquerda ou direita, que é o indicator:
pd.merge(cadastro_a, cadastro_b, how="outer", on=["Id"], indicator=True)
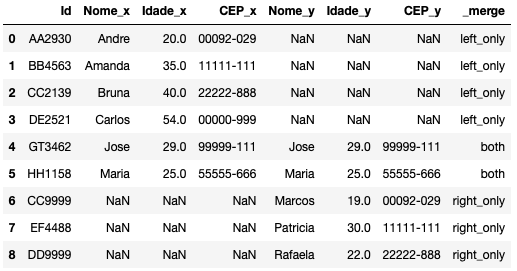
join
E aí? Gostou do conteúdo? Se inscreva para receber todas as novidades. Deixe seu e-mail em INSCREVA-SE na barra à direita, logo abaixo de pesquisar. E, por favor, não deixe de comentar, dar seu feedback e, principalmente, compartilhar com seus amigos. De verdade, isso faz toda a diferença. Além disso, você também pode acompanhar mais do meu trabalho seguindo a conta de Twitter @UniDosDados ou por alguma das redes que você encontra em Sobre o Estatsite / Contato, como meu canal de Youtube Canal Universidade dos Dados. E se você gosta de tecnologia, escute o podcast Futuristando!
Bons estudos!
Parabéns pelo conteúdo! Muito didático e me ajudou bastante.
Valeu, Thiago! Muito legal receber esse tipo de feedback!!!! Espero continuar ajudando 🙂
Excelente material. Muito bem explicado. Show! Obrigado por compartilhar seu conhecimento!
Obrigado, Celso!!!
Eu usei oque ensinou e foi realmente bem explicativo e muito intuitivo! PARABENS PELO BLOG.
Se eu quiser fazer um inner, mas ao invés de devolver oque pedi, quiser voltar todo o DF da esquerda mas com um novo campo que seria esse inner, como poderia fazer ?
cara, que material de qualidade!!!!
gratidão pelo tempo que tu dispende para ajudar
Valeu, Roberto!!!!
Parabéns pela aula! Me ajudou demai
Apesar de já usar o Python há um tempo razoável, aqui encontrei uma forma bastante didática de apresentar o JOIN. Parabéns!