Machine Learning, como o próprio nome diz, é sobre aprendizado de máquinas. Mas a máquina não aprende sempre do mesmo jeito. Tal como um ser humano, há formas dela aprender. Aqui, vamos falar dos três tipos de aprendizados existentes: supervisionado, não-supervisionado e semi-supervisionado.
O aprendizado supervisionado ainda é o mais comum de se ver. Isso porque não só as áreas de Data Science utilizam, mas as áreas de negócio também. Na verdade, em áreas de negócio esse ainda toma 100% do espaço (ou pelo menos 95% que seja). Quando digo áreas de negócio, entenda como a área de Crédito, de Cobrança, de Políticas de Crédito, de Qualidade do Atendimento, etc. Essas áreas costumam ser um híbrido entre negócio e dados. É comum ver pessoas que sequer encostam em códigos e outras que passam o dia fazendo tratamentos de bases.
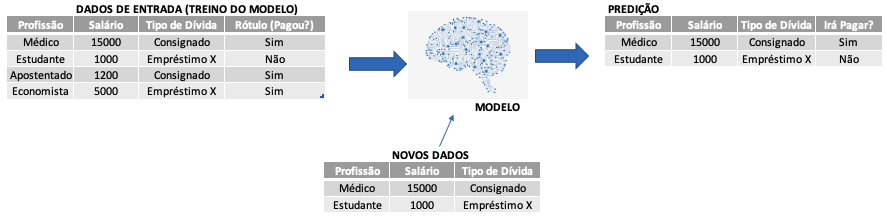
No aprendizado supervisionado, quando você alimenta o seu programa – o seu algoritmo – com dados, você inclui o rótulo dos dados. Você aponta para o seu algoritmo o que você está buscando. Exemplo: imagine que você está criando um algoritmo para predizer se o cliente do banco é bom ou mau pagador. Quando você passar os dados de treino para seu programa, esses dados vão ter o rótulo de se o cliente é bom ou mau. Ou seja, no algoritmo supervisionado, o programa vai ler os dados que você passou, vai verificar quem é bom e quem é mau pagador ali e, a partir disso, dividir quais características tornam aquele cliente bom ou mau pagador. Você está passando o histórico dos clientes para que assim seu algoritmo saiba identificar no futuro quem é bom e quem é mau.
São exemplos de algoritmos de aprendizado supervisionado: KNN, Regressão Linear, Regressão Logística, Árvore de Decisão, Random Forest, SVMs.
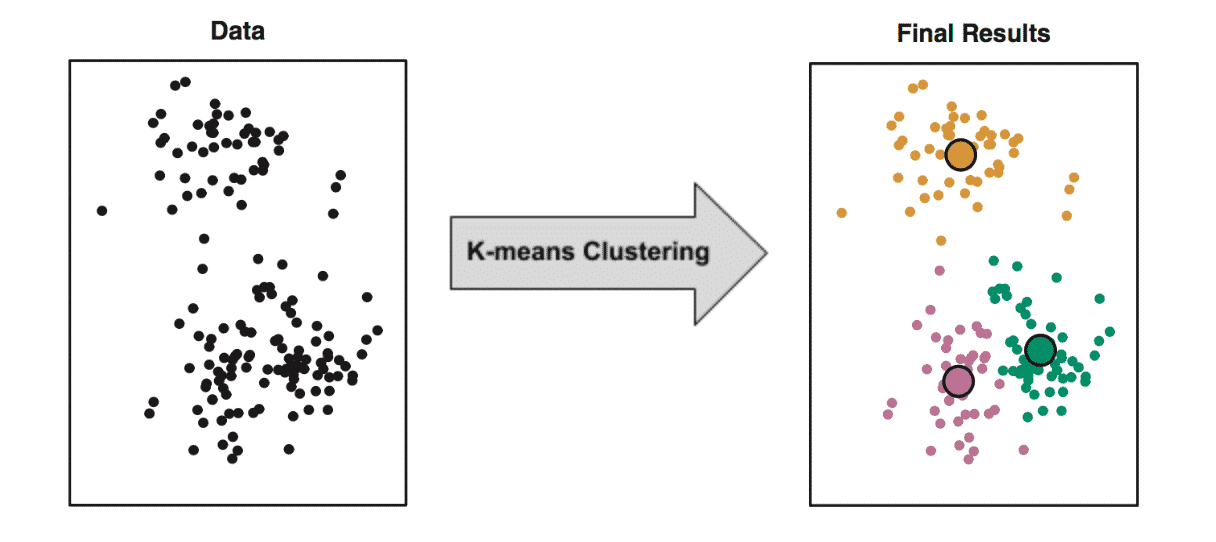
Outro tipo de aprendizado que você verá muito, mas que nem é tão raro assim, só menos comum, é o aprendizado não-supervisionado. Como você talvez já esteja imaginando, neste tipo de algoritmo, você não passa o rótulo dos indivíduos – e aqui não entenda indivíduo como ser-humano, mas como um elemento dos seus dados. Neste caso, o sistema vai tentar aprender sozinho. Ele irá receber os dados e criar rótulos ou divisões de acordo com o que ele está vendo.
Exemplo: imagine que você envie para o programa dados sobre diversos tipos de plantas. Nos dados, você incluiu o comprimento do caule, largura da folha, cores, dentre outras características. Porém, você não identificou os nomes das espécies de cada planta. O que seu programa vai fazer é separar os indivíduos em grupos de características semelhantes. Mas veja que ele não tem o nome das espécies, apenas está separando o que ele entende que são plantas parecidas – masé claro, possivelmente são de espécies semelhantes.
São exemplos de algoritmos de aprendizado não-supervisionado: K-Means, Apriori, Eclat, Hierachical Cluster Analysis (HCA), Expectation Maximization, PCA, Kernel PCA.
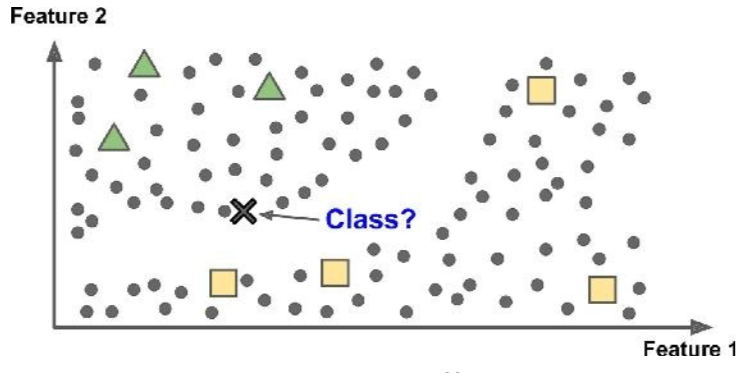
Por fim, o menos utilizado, é o algoritmo de aprendizado semi-supervisionado. Neste caso, creio que você já adivinhou, são os algoritmos que vão lidar com dados parcialmente rotulados. Um exemplo clássico é o sistema de fotos do Google, o Google Photos. Note que ele recebe as fotos e, após verificar algumas das que você ‘taggeou’ pessoas, passa a identificar quem é quem em novas fotos.
Nesse caso, os algoritmos costumam ser combinações dos outros dois tipos de aprendizado. Alguns métodos estatísticos utilizados*: Generative Models, Low-Density Separation, Deep Belief Networks.
* Não conheci nenhum material de aprendizado semi-supervisionado em português, então peço desculpas pelo excesso do inglês aqui.
Gostou do conteúdo? Se inscreva para receber as novidades! Deixe seu e-mail em INSCREVA-SE na barra à direita, logo abaixo de pesquisar. E, por favor, não deixe de comentar, dar seu feedback e compartilhar com seus amigos. De verdade, isso faz toda a diferença. Você também pode acompanhar mais do meu trabalho seguindo a conta de Twitter @EstatSite ou por alguma das redes que você encontra em Sobre o Estatsite / Contato.
Bons estudos!