Quando falamos de Machine Learning, estamos falando de “máquinas que aprendem”, como o próprio nome já diz. Porém, há várias formas das máquinas aprenderem, diversos tipos de algoritmo. Fazemos essa distinção através do que chamamos de tipos de aprendizado em Machine Learning. O aprendizado pode ser supervisionado, não-supervisionado e semi-supervisionado. Abaixo, as explicações de cada um deles.
APRENDIZADO SUPERVISIONADO
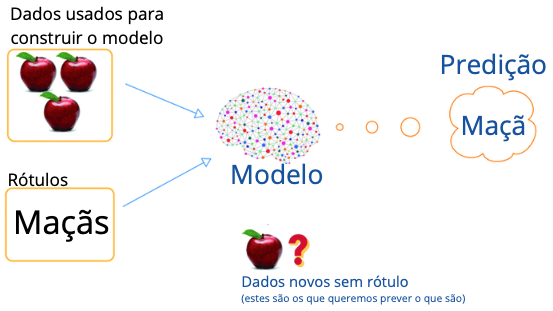
No Aprendizado Supervisionado, os dados utilizados na construção do algoritmo possuem rótulos. Aqui, chamamos de rótulo a definição que desejamos fazer a predição, a solução que desejamos no modelo. Ou seja, você vai construir o algoritmo com dados que já possuem uma definição. Se fizer um modelo de crédito, você tem dados históricos marcados como pagou ou não a dívida; se fizer um modelo de churn, dados já marcados se o indivíduo virou ou não churn.
EXEMPLO: Imagine que você tenha um grupo de e-mails classificados entre spam e não spam. Com base no conteúdo destes e-mails, você cria um classificador que vai decidir se um e-mail que chegou na caixa do usuário é ou não spam. Este problema é um clássico no aprendizado supervisionado. O rótulo aqui é a definição de spam ou não spam dos e-mails.
Regressão Linear, Regressão Logística, Árvore de Decisão, CatBoost, XGBoost, são todos algoritmos de aprendizado supervisionado.
APRENDIZADO NÃO-SUPERVISIONADO
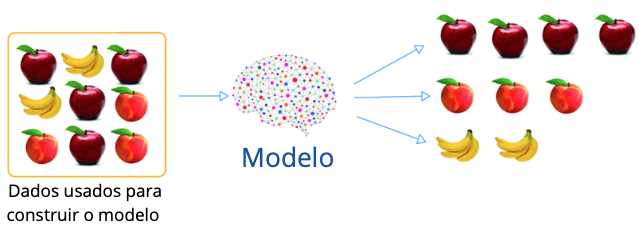
No Aprendizado Não-Supervisionado, os dados utilizados na construção do algoritmo não possuem rótulos. Novamente, chamamos de rótulo a definição do que desejamos fazer a predição. Aqui, o que vai acontecer é que chegarão dados sem marcação alguma, somente um monte de informações, mas não existe a variável-alvo.
EXEMPLO: Imagine que você possui dados dos clientes que entram no seu blog. Você sabe quais os links eles acessam e também características pessoais. Com base nisso, você entende que é importante dividir os clientes em alguns grupos distintos de acordo com os semelhantes. I.e., você cria alguns grupos, onde dentro de cada um deles, os clientes são muito parecidos entre si.
K-Means, HCA, PCA, t-SNE são todos algoritmos de aprendizado não-supervisionado.
APRENDIZADO SEMI-SUPERVISIONADO
Como você deve imaginar, aqui temos uma situação em que temos alguns dados com rótulos e outros não. Pode ser interessante trabalhar com este tipo de modelo, pois não há a necessidade de ter rótulos em todas as informações. Ou seja, você provavelmente estará aumentando sua amostra para construir um modelo.
EXEMPLO: Você possui uma área de atendimento ao cliente, onde são analisadas as reclamações da Play Store. Um analista classifica as reclamações em categorias (preço, bug, usabilidade, etc). Porém, ele faz isso manualmente e acaba que isso é feito somente para uma amostra, já que seria inviável fazer para todas. Você pode pegar as reclamações que ele já classificou, juntar com as não classificadas e trabalhar com um modelo semi-supervisionado.
Este método é muito menos popular e pouco utilizado ainda, mas isso deve mudar. No Scikit-Learn, já temos, por exemplo, o SelfTraining e o Label Propagation. Vocês encontram mais exemplos no livro Semi-Supervised Learning (Adaptive Computation and Machine Learning series) 1st Edition, do Olivier Chapelle, Bernhard Scholkopf (Editor) e Alexander Zien (Editor).
OUTROS EXEMPLOS
EXEMPLO 1: Você é cientista de dados de um centro de pesquisa medicinal. Você possui um conjunto de dados de diversas pessoas. Cada linha da sua tabela é uma pessoa e cada coluna é um hábito dela (fumante, pratica esportes, etc). Você possui também uma marcação sendo que 1 é a pessoa que teve câncer e 0 é a pessoa que não teve câncer. Com base nestes dados, você precisa criar um algoritmo que prevê se uma pessoa terá câncer com base nos seus hábitos. O que você tem é um problema de APRENDIZADO SUPERVISIONADO.
EXEMPLO 2: O time de marketing da sua empresa coletou e rotulou diversos tweets de pessoas falando sobre o filme que vocês acabaram de lançar. Eles classificaram os tweets em 3 tipos: elogio, crítica, neutro. Seu chefe gostaria de criar um algoritmo que rotulasse futuros tweets, para que vocês saibam quantas pessoas estão falando mal de outros lançamentos. Como marketing não rotulou tantos tweets assim, você talvez devesse incrementar dados não rotulados na construção do modelo. O que você tem aqui é um problema de APRENDIZADO SEMI-SUPERVISIONADO.
E aí, curtiu o post?
E aí? Gostou do conteúdo? Agora, imagine estudar análise e ciência de dados com trilhas estruturadas e projetos práticos, com direcionamento claro do que aprender e em que ordem. No nosso Clube de Assinaturas, você encontra desde o essencial para entrar na área de dados, até temas que diferenciam profissionais mais seniores no mercado, como inferência causal, engenharia de software e álgebra linear aplicada a ML.
Conheça: www.universidadedosdados.com
BONS ESTUDOS!