Regressão linear foi um assunto bastante comentado quando eu criei este blog. Agora, vamos ver como é fácil rodá-la no SAS e, no mesmo código, fazer uma análise visual dos resíduos.
Neste post, vamos trabalhar com os dados de GPA2 (você pode baixar aqui GPA2). Esta tabela contém dados de 4.137 alunos do ensino superior, com as informações de notas, sexo, se o aluno é ou não atleta, etc. Agora, vamos rodar uma regressão com a variável resposta sendo colgpa e as variáveis explicativas sendo hsperc e sat. Hsperc diz respeito ao percentil em que o aluno estava quando graduou na escola, i.e., se o aluno tiver um hsperc = 10, ele estava entre os 10% melhores alunos. Já o sat é uma espécie de ENEM que os americanos fazem. A variável colgpa se refere à nota do aluno. O comando para executar uma regressão linear no SAS é o PROC REG:
PROC REG DATA = GPA2; MODEL COLGPA = HSPERC SAT ; RUN;
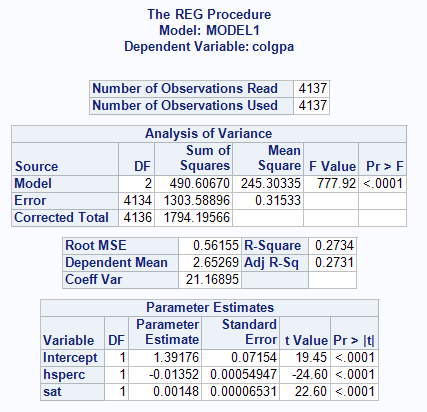
Note que basta você utilizar a subcláusula MODEL e escrever exatamente a equação que você quer ver. Agora, como interpretar estes resultados?
Bom, começamos pelo termo que todo mundo sempre quer ver: o p-valor. O p-valor aqui testa a hipótese nula de que o coeficiente é igual a zero, ou seja, não tem efeito. O resultado nos indica que podemos rejeitar a hipótese nula. Em outras palavras, a variável explicativa tem efeito na variável resposta.
Outros dois valores que sempre chamam atenção são o r-quadrado e o r-quadrado ajustado. Como podemos ver, nosso r-quadrado é 0.2734 e nosso r-quadrado ajustado é 0.2731. O r-quadrado indica o quanto da variância na variável resposta é explicada pelas variáveis independentes. É uma mediade de associação. O r-quadrado ajustado é uma medida de associação, tal como o r-quadrado, porém ele leva em consideração as variáveis que vão sendo adicionadas. Se uma pessoa for inserindo variáveis no modelo, ela vai sempre conseguir um r-quadrado maior, só pelo fato de incluir mais variáveis. O r-quadrado ajustado leva em consideração os números de preditores. Quando tivermos um número pequeno de observações e um número alto de preditores, a diferença entre essas duas medidas ficará mais clara.
As outras variáveis são um pouco mais intutivas, e geralmente causam menor preocupação. Root MSE é a raiz do quadrado médio do erro e servirá para saber o quão próximos estão os pontos estimados dos pontos observados. Dependent mean, como a tradução direta já indica, é a média da variável dependente (colgpa). Já a medida Coeff Var é o coeficiente de variação, uma medida de variação dos seus dados, seu cálculo é dado a seguir:
Coeff Var = 100 * (Root MSE / Dependent Mean)
Já sabendo todas essas informações, podemos escrever o resultado acima na forma de equação*:
colgpa = 1,39176 – 0,01352 * hsperc + 0,00148 * sat
O que isso quer dizer?
Quer dizer que quanto maior hsperc, menor colgpa. Além disso, também nos diz que quanto maior sat, maior colgpa. Bem, parece fazer sentido. Quanto menor hsperc, melhor posicionado está o aluno. Um aluno com hsperc = 10, estava entre os top 10% da sua escola. Já um com hsperc = 5, estava entre os top 5%. Então, quanto menor, melhor é o aluno, logo, esperamos uma nota maior, um gpa maior. Para o sat é o contrário. Quanto maior o sat, melhor é o aluno. Logo, faz sentido seu coeficiente ser positivo, indicando que quanto maior o sat, maior o colgpa. Lembrando que estamos sempre pensando na média. E que há o termo de erro. Ou seja, é óbvio que você pode encontrar um aluno com hsperc = 5 e um colgpa maior que outro aluno que tem hsperc = 1.
E se quisermos estimar o colgpa de um aluno com hsperc = 100 e sat = 50?
Apenas insira estes valores na equação:
colgpa = 1,39176 – 0,01352*100 + 0,00148*1350
colgpa = 2,03776
Agora já sabemos como interpretar o resultado da regressão e como utilizá-lo para fazer estimativas futuras.
ANÁLISE DOS RESÍDUOS
Após rodar a regressão, é importante atentar-se para uma premissa da OLS, que é a normalidade dos resíduos. No SAS, é possível fazer o gráfico do resíduo vs. valores estimados no mesmo PROC REG que gera os resultados da regressão, veja o exemplo abaixo:
PROC REG DATA =STDY.GPA2; MODEL COLGPA = HSPERC SAT ; PLOT RESIDUAL. * PREDICTED. ; RUN;
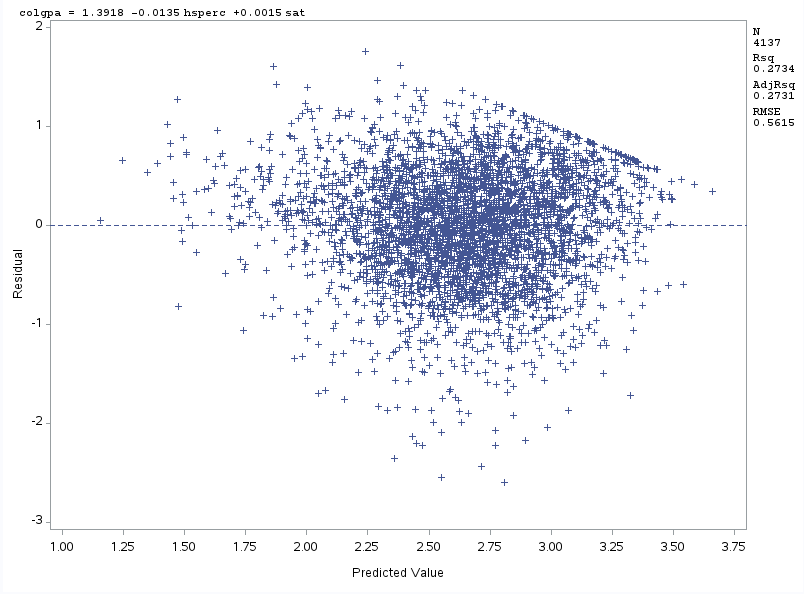
Há ainda outras formas de se analisar a normalidade dos resíduos. Veja, por exemplo, que podemos traçar um QQPLOT para os resíduos e ainda obter alguns testes de normalidade. Primeiro, rodamos a regressão e salvamos uma tabela com as variáveis da regressão e os resíduos e valores projetados para cada indivíduo:
PROC REG DATA = STDY.GPA2; MODEL COLGPA = HSPERC SAT; OUTPUT OUT=OUT_GPA2 (KEEP= COLGPA HSPERC SAT RES PRED) RESIDUAL=RES PREDICTED=PRED; RUN; QUIT;
Na sequência, usamos essa tabela gerada para traçar o QQPLOT e fazer alguns testes de normalidade:
PROC UNIVARIATE DATA =OUT_GPA2 NORMAL ; VAR RES; QQPLOT RES / NORMAL (MU =EST SIGMA =EST ); RUN;
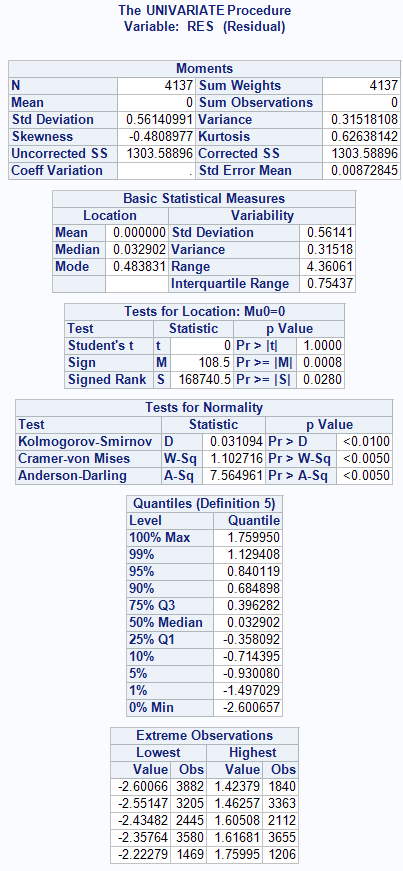
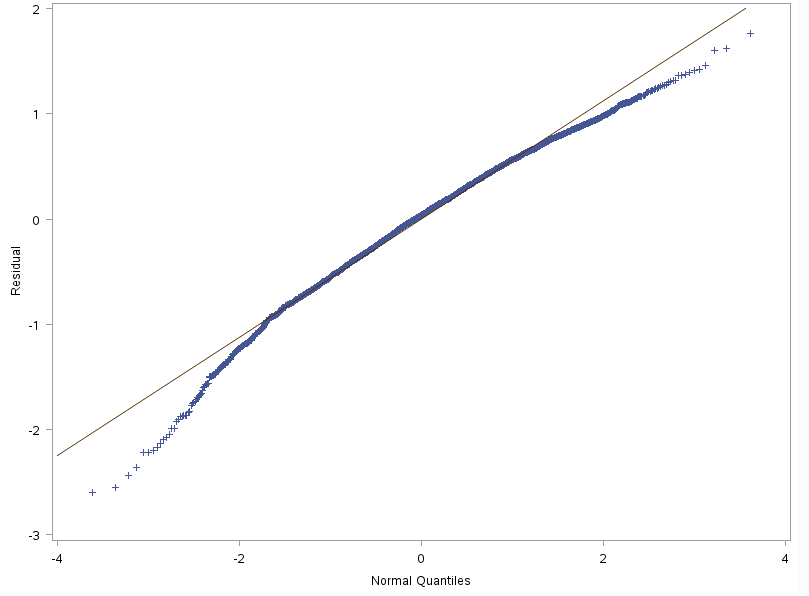
Graficamente, nossos resíduos não parecem normais. Entretanto, os testes feitos indicam normalidade. A partir daí, há algumas medidas que o leitor pode tentar para garantir que os resíduos são normais, como aplicar a transformação logarítmica na variável, ou trabalhar com outras variáveis e transformações.
Espero que o post tenha sido útil. Se você gostou, compartilhe com seus amigos que também trabalham nessa área.
Bons estudos!
*Atenção: Para a notação ser mais correta, a equação deveria ter o símbolo ‘^’ em cima do nome das variáveis. Isso não foi feito aqui, por conta da formatação do WordPress.