group by
PROC SQL; CREATE TABLE VENDAS_P_MARCA AS SELECT MARCA, SUM(VENDAS) AS VENDAS FROM TABELA_VENDAS GROUP BY 1; RUN;

PROC SQL; CREATE TABLE VENDAS_P_ESTADO AS SELECT ESTADO, SUM(VENDAS) AS VENDAS FROM TABELA_VENDAS GROUP BY 1; RUN;

PROC SQL; CREATE TABLE VENDAS_P_ESTADO_MARCA AS SELECT MARCA, ESTADO, SUM(VENDAS) AS VENDAS FROM TABELA_VENDAS GROUP BY 1,2; RUN;
group by, case when. case when if… then…
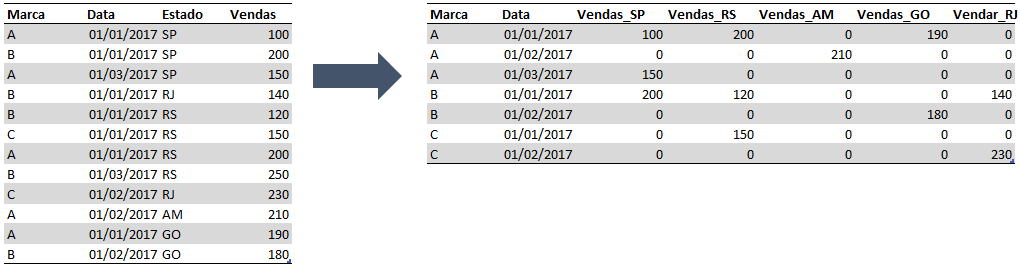
**** SOMA COM CONDICAO E AGRUPA *****; PROC SQL; CREATE TABLE VENDAS_MARCA_FINAL AS SELECT MARCA, DATA SUM (CASE WHEN ESTADO = "SP" THEN VENDAS ELSE 0 END) AS VENDAS_SP, SUM (CASE WHEN ESTADO = "RS" THEN VENDAS ELSE 0 END) AS VENDAS_RS, SUM (CASE WHEN ESTADO = "AM" THEN VENDAS ELSE 0 END) AS VENDAS_AM, SUM (CASE WHEN ESTADO = "GO" THEN VENDAS ELSE 0 END) AS VENDAS_GO, SUM (CASE WHEN ESTADO = "RJ" THEN VENDAS ELSE 0 END) AS VENDAS_RJ FROM TABELA_VENDAS GROUP BY 1,2; QUIT;
Existe equivalente dessa função no R?
Fala, Fernando! Desculpe a demora, mas existe sim.
Se liga nesse link: https://dplyr.tidyverse.org/reference/group_by.html