Como sempre digo, aprender SQL é fundamental para um cientista de dados. Apesar de focarmos muito em Python, R e SAS, nenhuma linguagem é tão comum às empresas quanto SQL. Então não deixe de estudá-la. Abaixo, vou te introduzir à linguagem, ensinar como unir tabelas da mesma forma que você faria com o PROCV no Excel, e ensinar a utilizar condicionais. Bora! Continuar a ler “Introdução ao SQL + Left Join + Case When”
Etiqueta: group by
Como Agrupar os Dados por Semana no SQL
Agora que já mostramos como agrupar os dados por um determinado grupo utilizando o group by, vamos ver como fazer um agrupamento para mostrar os dados semana a semana. Continuar a ler “Como Agrupar os Dados por Semana no SQL”
Group By no SQL
Imagine que você tenha a informação de renda dos clientes das suas lojas ao redor do Brasil. Seria interessante saber qual a renda média da sua base de clientes, claro. Mas talvez fosse mais interessante ainda saber a renda média de clientes por estado. Para fazer isso, sumarização da informação por um determinado grupo, você precisa conhecer o famoso GROUP BY. O Group By serve para fazer exatamente o que o nome diz: “agrupar por” algum campo. Imagine que você tenha uma coluna com valores de alguma variável. Você quer agrupar essa variável de alguma forma, seja fazendo uma soma ou calculando a média. Porém, você tem a necessidade de agrupar por alguma outra variável. É aí que entra o group by. Vamos ver um exemplo para facilitar. Primeiro, criamos uma tabela para trabalharmos o exemplo. Vamos criar uma tabela já bastante manjada por quem acompanha o site, as compras que os clientes fizeram em uma determinada loja:
-- exclui tabela caso ela exista
drop table base_compras;
-- cria os campos da tabela
CREATE TABLE base_compras (
Id int,
Nome varchar(50),
Sobrenome varchar(50),
Estado varchar(2),
Gastos decimal,
Data_Compra date
);
-- insere valores na tabela
INSERT INTO base_compras
VALUES
(152, 'Andre', 'Silva', 'MG', 351.50, '2018-01-22'),
(222, 'Barbara', 'Toledo', 'SP', 250.10, '2018-05-15'),
(451, 'Carlos', 'Pinheiro', 'MG', 455.00, '2017-02-05'),
(754, 'Eduardo', 'Silva', 'SP', 390.10, '2018-04-10'),
(897, 'Juliana', 'Oliveira', 'MG', 150.50, '2017-03-01'),
(852, 'Maria', 'Lima', 'MG', 325.90, '2018-05-30'),
(997, 'Ricardo', 'Pereira', 'MG', 332.59, '2018-05-25'),
(535, 'Vanessa', 'Costa', 'SP', 241.57, '2017-04-30');
-- visualiza tabela
select * from base_compras;
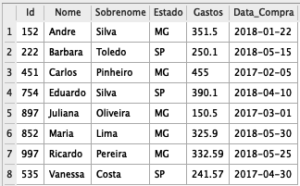 Primeiro, eu coloco um drop table no início do código, pois sempre que ele for rodar, ele exclui a tabela antiga que possui o nome base_compras. No SQL, se você tentar criar uma tabela e já existir outra com mesmo nome, ele retorna um erro. Por esse motivo, eu costumo adicionar um drop table antes de um create table.
Primeiro, eu coloco um drop table no início do código, pois sempre que ele for rodar, ele exclui a tabela antiga que possui o nome base_compras. No SQL, se você tentar criar uma tabela e já existir outra com mesmo nome, ele retorna um erro. Por esse motivo, eu costumo adicionar um drop table antes de um create table. Agora que temos a base, vamos tentar resumir as informações por estado. Vamos obter a média e a soma dos gastos por cada estado:
-- sumariza os gastos por Estado
select estado,
sum(gastos) as gasto_total,
avg(gastos) as media_gastos
from base_compras
group by 1
order by 1;
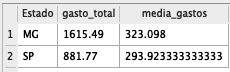
Note que a lógica é bem simples. Primeiro, selecionamos o que queremos: o estado (que será o objeto pelo qual as outras informações serão agrupadas), a soma de gastos (que denominamos “gasto_total”) e a média dos gastos (denominada media_gastos). Por fim, agrupamos e ordenamos pelo primeiro item selecionado: o estado. Poderíamos fazer a mesma coisa, mas utilizando o nome do campo:
-- sumariza os gastos por Estado
select estado,
sum(gastos) as gasto_total,
avg(gastos) as media_gastos
from base_compras
group by estado
order by estado;
Você poderia ordenar por mais campos também. Vamos ver um exemplo um pouquinho mais complexo (mas bem pouco).
Como estou trabalhando no SQLite, não consigo utilizar as funções mais simples para lidar com data, como por exemplo year(), month(), day(). Por isso, apenas para que vocês entendam como funciona, vou demonstrar o que faz a função strftime():
select strftime('%Y', Data_Compra) from base_compras
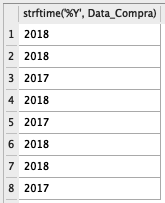
Veja que ela extrai a informação de ano da variável Data_Compra. Eu fiz isso porque agora nós vamos obter a média e a soma dos gastos agrupados por Estado e por Ano. Ou seja, veremos a média dos gastos dos clientes de MG no ano de 2017 e a média no ano de 2018. O mesmo para SP.
select estado,
strftime("%Y", Data_Compra) as Ano,
sum(gastos) as gasto_total,
avg(gastos) as media_gastos
from base_compras
group by 1,2
order by 1,2;
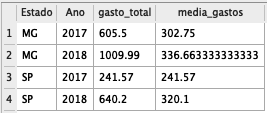
Viu que simples? Agora você pode fazer resumos dos seus dados de uma forma bem mais completa.
Gostou do post? Veja mais de SQL em Programação em SQL. Além disso, se restou alguma dúvida, ou se você tem alguma crítica, comentário ou sugestão, entre em contato deixando um comentário ou escrevendo através do contato deixado em Sobre o Estatsite / Contato.
Caso tenha interesse em obter mais conteúdos de Data Science, você pode acompanhar o @EstatSite.
Missing no Python: Como Localizar e Substituir
Na vida real, as bases são bem diferentes do que costumamos ver na academia ou até mesmo em sites como o Kaggle. Sendo assim, é importante saber como lidar quando se deparar com um conjunto de dados em que haja algo faltando, em que existam campos missing. Vamos aprender como localizar linhas e colunas com missing, além de preencher essas células com algum valor. Bora aprender como tratar missing no python! Continuar a ler “Missing no Python: Como Localizar e Substituir”
Tutorial: Limpeza e Análise de Dados com Python
Hoje vamos aprender algumas coisas que podem ser feitas quando se trabalha com dataframes no Python. Como filtrar uma base? Como converter textos para números? Como extrair um valor de moeda no formato texto para o formato numérico? Como obter as estatísticas descritivas? Como criar novas colunas? Como traçar um histograma? Como localizar valores nulos e preenchê-los com a média da coluna? Tudo isso e muito mais no post abaixo! Continuar a ler “Tutorial: Limpeza e Análise de Dados com Python”
Group By no Python + Group By com Base Filtrada
O termo group by é muito popular para quem trabalha com base de dados. Quando temos repetições para o elemento chave e queremos fazer um resumo, um agrupamento, é esse o comando a ser utilizado. Um exemplo clássico é quando você tem os dados dos gastos feitos por clientes de uma loja e sua base contém um gasto por linha. Para obter o total gasto por cada cliente, você irá recorrer ao group by. Continuar a ler “Group By no Python + Group By com Base Filtrada”
SAS Group By no R
Já aprendemos como somar e agrupar os dados no SAS aqui, no R isso é tão simples quanto, basta você utilizar a função tapply(). A função é composta basicamente de três elementos: o vetor contendo valores, o campo que será utilizado no agrupamento e a função que será aplicada. Continuar a ler “SAS Group By no R”
Soma com condição no SAS: Agrupamentos com Proc Sql
O group by é um método bem tranquilo de agrupar os valores de uma coluna de acordo com os valores de outra coluna. Veja os três exemplos abaixo, onde queremos primeiro saber qual o número de vendas de cada marca, o número de vendas por estado e o número de vendas de cada marca em cada estado: