Quem trabalha muito com bases de dados com certeza já usou algum comando com o nome merge ou os famosos joins. Esse eu acho que é de longe o tipo de comando que eu mais uso quando trabalho com base de dados. Como você nunca tem todas as informações possíveis em uma tabela, você sempre vai precisar enriquecer suas bases com informações de outros locais.
ATENÇÃO: A identação (espaçamento) do WordPress é meio ruim, tenha cuidado ao copiar e colar os exemplos no R.
No exemplo abaixo, temos a tabela_A com as informações de id, nome e idade dos clientes de uma loja. Na tabela_B, temos a informação de id e UF destes mesmos clientes. Vamos utilizar a função merge() para trazer as informações de UF da tabela_B para tabela_A. Nossa nova tabela se chamará tabela_merge:
# constroi tabela A
tabela_A = data.frame(c("AA125", "BB235","CC355","DE354","QQ111","XX000"),
c("Andre", "Marcos", "Fernanda", "Julia", "Maria", "Jose"),
c(21,28,29,35,22,39))
colnames(tabela_A) = c("id","Nome","Idade")
# constroi tabela B
tabela_B = data.frame(c("AA125", "BB235","CC355","DE354","QQ111","XX000"),
c("BA", "RJ", "RJ", "RS", "SP", "MG"))
colnames(tabela_B) = c("id", "UF")
# une as duas tabelas pelo campo id
tabela_merge = merge(tabela_A, tabela_B, by="id")
# analisa o output
View(tabela_merge)
# ou
head(tabela_merge



Note que nós simplesmente agregamos as informações da tabela_B na tabela_A.
Caso você queira unir por dois campos, basta incluir todas as variáveis em comum após o comando by: merge(tabela_A, tabela_B, by = c(variavel_1, variavel_2, variavel_3, …). No exemplo abaixo, não temos uma chave única por cliente. Por isso, para garantir que estamos trazendo as informações corretas da tabela_B, vamos unir utilizando os campos nome e tel:
# constroi tabela A
tabela_A = data.frame(c("Andre", "Marcos", "Fernanda", "Julia", "Maria"),
c(7596565669, 2198979789, 516556498, 116458986, 316587989),
c(21,28,29,35,30),
c(0,0,1,1,2))
colnames(tabela_A) = c("Nome","Tel","Idade","N de Filhos")
# constroi tabela B
tabela_B = data.frame(c("Andre", "Marcos", "Fernanda", "Julia", "Maria"),
c(7596565669, 2198979789, 516556498, 116458986, 316587989),
c("Analista","Analista","Coordenador","Gerente","Gerente"),
c("S","S","N","S","S"))
colnames(tabela_B) = c("Nome","Tel","Cargo","Possui Carro")
# une as duas tabelas pelo campo id
tabela_merge = merge(tabela_A, tabela_B, by=c("Nome", "Tel"))



Vale lembrar que esse comando (merge) é semelhante ao inner join do SAS, ele trará somente as informações de intersecção das duas tabelas. Veja, por exemplo, quando pegamos nosso primeiro exemplo e nossa tabela_B não tem a informação para o id = BB235:
# constroi tabela A
tabela_A = data.frame(c("AA125", "BB235","CC355","DE354","QQ111","XX000"),
c("Andre", "Marcos", "Fernanda", "Julia", "Maria", "Jose"),
c(21,28,29,35,22,39))
colnames(tabela_A) =c("id","Nome","Idade")
# constroi tabela B
tabela_B = data.frame(c("AA125","CC355","DE354","QQ111","XX000"),
c("BA", "RJ", "RS", "SP", "MG"))
colnames(tabela_B) = c("id", "UF")
# une as duas tabelas pelo campo id
tabela_merge = merge(tabela_A, tabela_B, by="id")

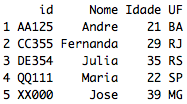
tabela_A

tabela_B
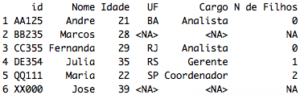
E se você tiver muitas colunas na tabela_B e quiser trazer só uma? Isto é, você quer fazer algo semelhante ao left join do SAS e SQL. Neste caso, complemente o merge declarando também all.x=TRUE:
# constroi tabela A
tabela_A = data.frame(c("AA125", "BB235","CC355","DE354","QQ111","XX000"),
c("Andre", "Marcos", "Fernanda", "Julia", "Maria", "Jose"),
c(21,28,29,35,22,39))
colnames(tabela_A) = c("id","Nome","Idade")
# constroi tabela B
tabela_B = data.frame(c("AA125","CC355","DE354","QQ111"),
c("BA", "RJ", "RS", "SP"),
c("Analista", "Analista", "Gerente", "Coordenador"),
c(0,0,1,2))
colnames(tabela_B) = c("id", "UF", "Cargo", "N de Filhos")
tabela_merge = merge(tabela_A, tabela_B, by="id", all.x=TRUE)


Como lição de casa, tente substituir all.x = TRUE por all.y = TRUE e por all = TRUE.
Mas e se você só quiser empilhar – colocar uma em cima da outra – as duas tabelas? Neste caso, utilize o rbind():
# constroi tabela A
tabela_A = data.frame(c("Andre", "Marcos", "Fernanda", "Julia", "Maria"),
c(7596565669, 2198979789, 516556498, 116458986, 316587989),
c(21,28,29,35,30),
c(0,0,1,1,2))
colnames(tabela_A) = c("Nome","Tel","Idade","N de Filhos")
# constroi tabela B
tabela_B = data.frame(c("Fabio", "Giulia", "Talita", "Fernando"),
c(7596565669, 2198979789, 516556498, 116458986),
c(20,38,19,32),
c(1,0,2,1))
colnames(tabela_B) = c("Nome","Tel","Idade","N de Filhos")
# empilha as tabelas
tabela_empilhada = rbind(tabela_A,tabela_B)


Agora você pode usar seu R quase como um SAS ou SQL.
E aí, curtiu o post?
E aí? Gostou do conteúdo? Se inscreva para receber todas as novidades. Deixe seu e-mail em INSCREVA-SE na barra à direita, logo abaixo de pesquisar. E, por favor, não deixe de comentar, dar seu feedback e, principalmente, compartilhar com seus amigos. De verdade, isso faz toda a diferença. Além disso, você também pode acompanhar mais do meu trabalho seguindo a conta de Twitter @UniDosDados, no Instagram @universidadedosdados ou por alguma das redes que você encontra em Sobre o Estatsite / Contato, como meu canal de Youtube Canal Universidade dos Dados.
Aproveite e adquira sua camiseta de data science na LOJA DA UNIVERSIDADE DOS DADOS. Vai ficar estiloso e me ajudar neste projeto!
BONS ESTUDOS!