Recentemente, estive na Python Brasil 2019. Um evento muito legal, falei um pouco sobre ele no Twitter do EstatSite (veja a thread aqui), e, inclusive, estou devendo um post aqui no blog. Acabei participando de um tutorial chamado “Machine Learning do Zero”, dado pelo Tarsis Azevedo – o cara é fera, recomendo que acompanhem o trabalho dele pelo Twitter ou Github, @tarsisazevedo. Aqui, vai o código feito em sala de aula, com algumas alterações e comentários que inclui porque achei relevante – outras porque achei que poderia facilitar para os mais novos
Atualização: Vocês agora podem visitar o post Regressão Linear no Python para aprender mais sobre regressão linear utilizando Python!
Acredito que o código está suficientemente autoexplicativo, então as explicações deste post não serão tão extensas quanto tenho o costume de fazer – por exemplo, não incluirei todas as saídas. Inclusive, recomendo que rode o código por partes, incluindo cada trecho em uma célula diferente do Jupyter Notebook – se você nunca utilizou o Jupyter, visite o post Uma Brevíssima Introdução ao Anaconda e o Jupyter Notebook.
Aqui, você vai aprender a localizar linhas e colunas com valores nulos/missing, excluir linhas ou colunas, obter estatísticas descritivas, fazer análise exploratória (gráfico de dispersão, histograma, mapa de calor), dentre outras coisas importantes no dia a dia de um cientista de dados.
# CARREGA BIBLIOTECA
import pandas
import numpy
import jupyter
import seaborn
import pytest
import sklearn
from matplotlib import pyplot
# CARREGA DATASET
# Primeiro, cria nomes pra usa-los nas colunas qdo carregar o dataset
columns = ['crim',
'zn',
'indus',
'chas',
'nox',
'rm',
'age',
'dis',
'rad',
'tax',
'ptratic',
'b',
'lstat',
'medv']
# importa dataset utilizando a funcao read_csv do PANDAS
boston_df = pandas.read_csv('https://raw.githubusercontent.com/tarsisazevedo/pybr-tutorial/master/housing-unclean.csv', names=columns)
# Alternativa: boston = pd.read_csv("housing-unclean.csv", names="crim zn undus chas nox rm age dis rad tax ptratio b lstat mdev".split())
# verifica as primeiras linhas
boston_df.head()
# Se quiser entender mais sobre alguma funcao, use o interrogacao
pandas.read_csv?
# Ou digite pandas.read_csv e aperte shift+tab
# Tipo de cada variavel
boston_df.dtypes
# Num de linhas e colunas
boston_df.shape
# Verifica se a linha toda esta duplicada
boston_df.duplicated()
# Acessa a linha 605
boston_df.iloc[605]
# Calcula qtas linhas estao duplicadas. Essa soma funciona pq o booleano TRUE eh igual a 1
boston_df.duplicated().sum()
# retira linhas duplicadas
boston_df.drop_duplicates()
# Repare: O jupyter nao alterou o nosso dataset com o comando anterior
boston_df.shape
Conforme dito nos comentários, o Jupyter não está alterando nossa base quando digitamos alguma função do tipo boston_df.drop_duplicates(). Ele apenas nos mostra como ficaria sem as duplicidades, mas não aplica a função na base existente. Para que isso seja feito, você deve sempre incluir o argumento inplace como sendo igual a True. Caso você não queira alterar a base original – eu, particularmente, não gosto disso e prefiro criar várias versões para acompanhar as alterações – você pode criar um dataframe novo aplicando a função conforme comentário no trecho abaixo:
# agora sim, vai alterar usando inplace boston_df.drop_duplicates(inplace=True) # se quisesse criar uma nova versao: # boston_df_v2 = boston_df.drop_duplicates() # conta quantos nulos tem em cada coluna boston_df.isnull().sum()
Note que temos alguns valores nulos em nosso conjunto de dados. Algumas das possibilidades para lidar com campos missing:
- Preencher o missing com a média ou mediana da coluna;
- Utilizar algum valor que sirva como uma nova classe;
- Utilizar valores preditos com base em algum modelo.
Dito isto, no nosso caso, os valores foram inseridos pelo Tarsis somente para fins didáticos. Podemos excluí-los sem perda de informação relevante:
# No nosso caso, podemos soh excluir os nulos boston_df.dropna(inplace=True) # verificamos nossa base boston_df.shape
Agora sim, nosso conjunto de dados foi alterado. Feitas essas pequenas manipulações, você vai querer observar as estatísticas descritivas dessa base. Para isso, aplicamos a função describe():
# analise descritiva
pandas.set_option('display.width',100)
pandas.set_option('precision', 3)
boston_df.describe() #aqui, variaveis categoricas estao sendo tratadas como numericas (tenha em mente que eh errado)
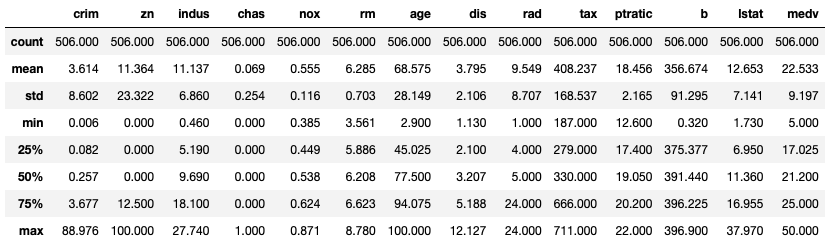
Temos então o número de indivíduos (count) para cada variável, a média, o desvio padrão, o valor mínimo, os percentis mais utilizados e o máximo. Caso desconheça alguma dessas variáveis, visite os posts Percentil – Conceito e Código SAS e Estatística Descritiva
E, agora, partimos para as visualizações, a famosa análise exploratória:
# boxplot da coluna crim
%matplotlib inline
boston_df.crim.plot("box")
# distribuicao das variaveis
plot_index=1
max_plots=4
for column in boston_df.columns:
axes = pyplot.subplot(4, max_plots, plot_index)
axes.set_title('Distribution of '+ column)
axes.figure.set_figheight(15)
axes.figure.set_figwidth(15)
axes.figure.set_tight_layout(False)
pyplot.hist(boston_df[column],bins=20)
plot_index=plot_index+1
# a feature que vamos prever
%matplotlib inline
pyplot.figure(figsize=(20, 5))
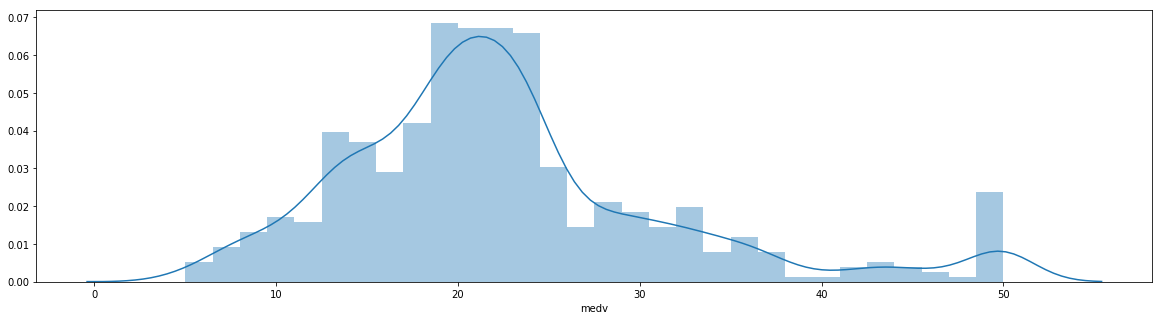
seaborn.distplot(boston_df['medv'], bins=30)
# boxplot 'tombado'
pyplot.figure(figsize=(20, 5))
seaborn.boxplot(boston_df['medv'])
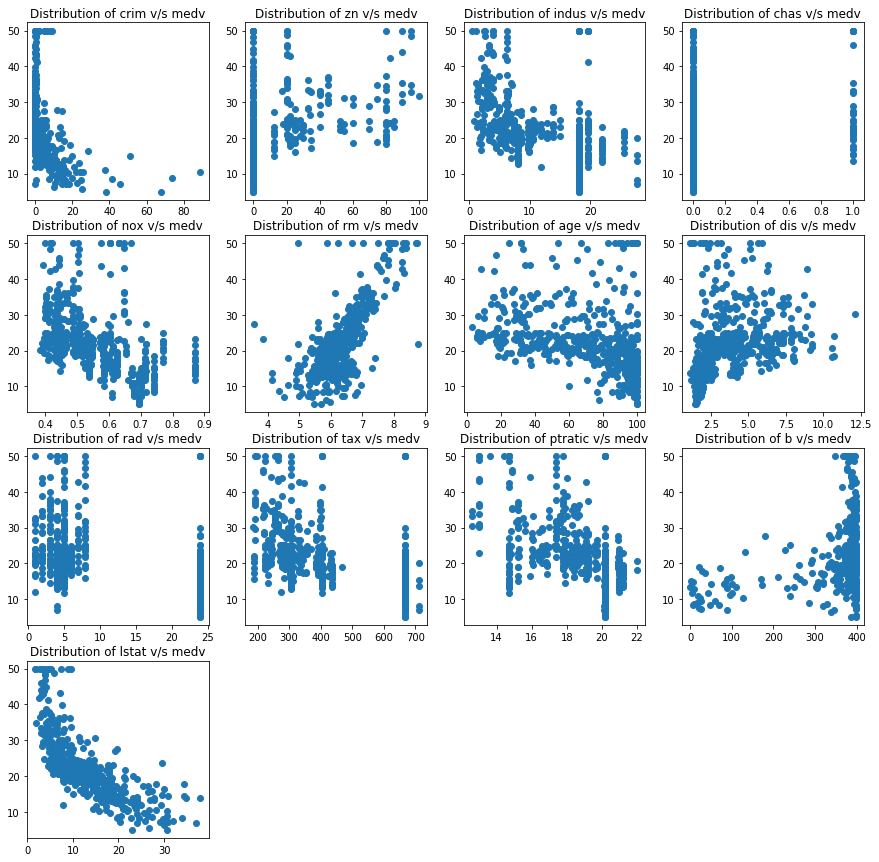
# Grafico de dispersao das variaveis vs medv
plot_index=1
max_plots=4
for column in boston_df.columns:
if column != "medv":
axes = pyplot.subplot(4, max_plots, plot_index)
axes.set_title('Distribution of '+ column + " v/s medv")
axes.figure.set_figheight(15)
axes.figure.set_figwidth(15)
axes.figure.set_tight_layout(False)
pyplot.scatter(boston_df[column], boston_df["medv"], marker='o')
plot_index=plot_index+1
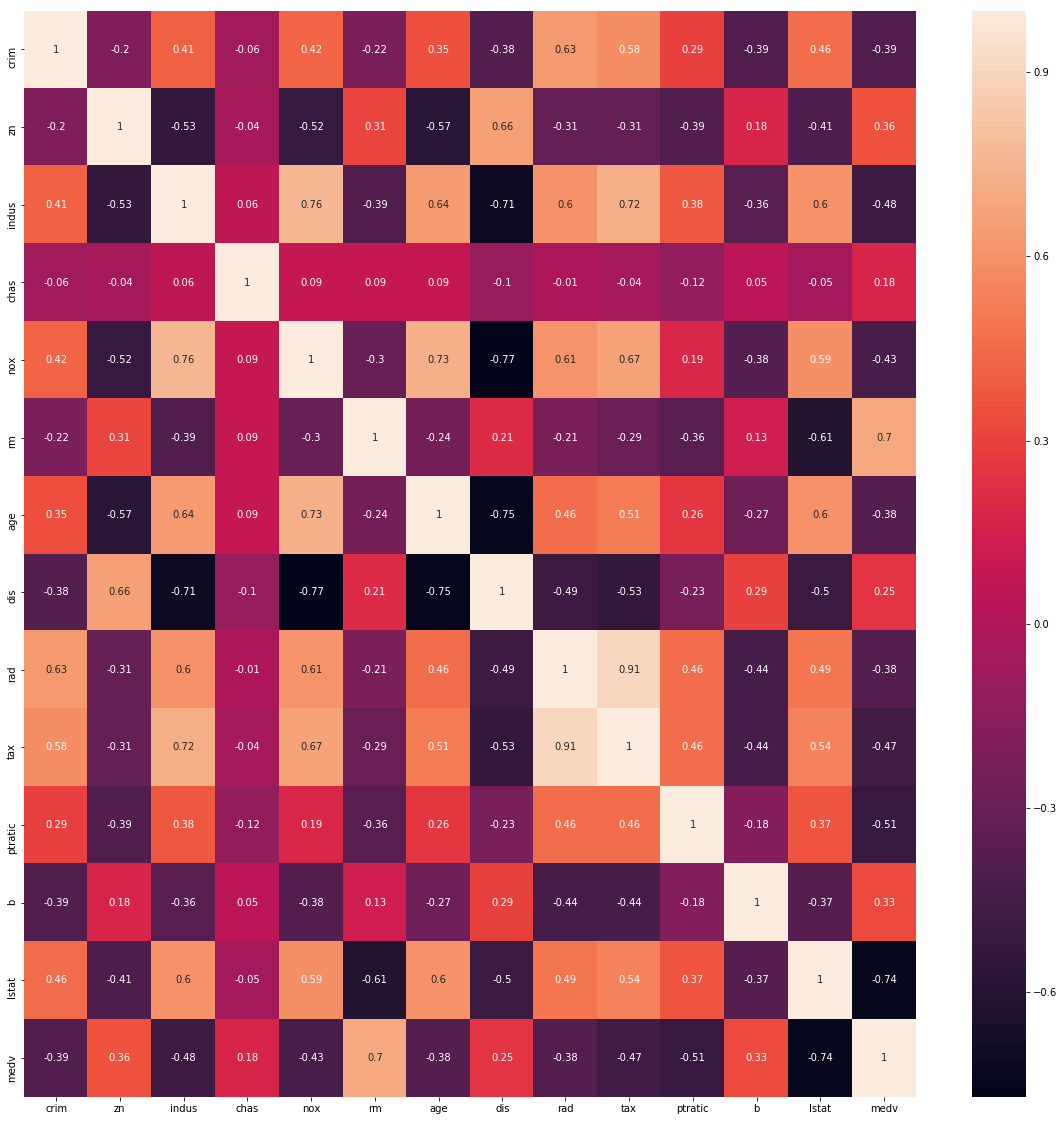
# Heatmap
pyplot.figure(figsize=(20, 20))
correlation_matrix = boston_df.corr().round(2)
# annot = True to print the values inside the square
seaborn.heatmap(data=correlation_matrix, annot=True)
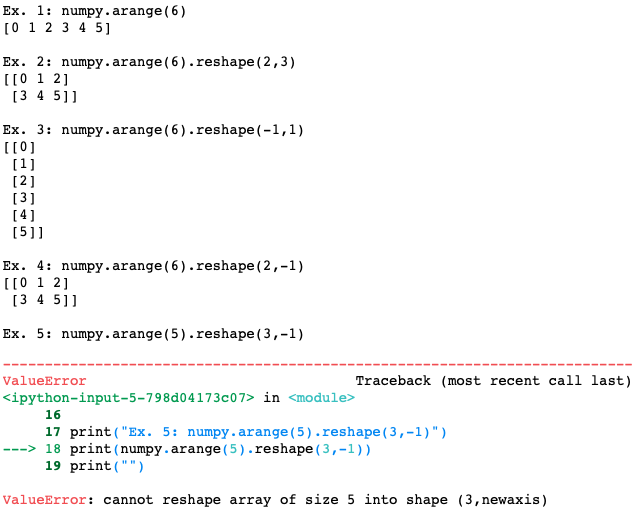
Agora, um breve parênteses a respeito da função reshape que usaremos mais para frente. Reshape serve para alterar as dimensoes do vetor. Quando temos reshape(2,3) queremos que o vetor seja reorganizado com duas linhas e tres colunas. Se tivermos um vetor com 5 elementos, reshape(2,3) nao vai funcionar, pois ficaria um espaco sobrando (2*3 = 6). Precisamos que o reshape seja exato. Ao utilizarmos -1 como argumento do reshape, entao o python vai determinar qual a quantidade de linhas ou colunas que deve utilizar. Por exemplo, se tivermos um vetor com 6 elementos e utilizarmos o reshape(-1,2), entao o python sabe que voce quer duas colunas, e que o numero de linhas deve ser de acordo com o que “couber” – no caso, serao 3. Se voce tiver 5 elementos e utilizar reshape(3,-1) entao o python tentara encontrar o numero de colunas necessarias para encaixar 5 elementos. Como isso nao eh possivel, ja que precisamos ter o numero exato de posicoes no reshape, ele retornara um erro.
Veja os exemplos abaixo:
print("Ex. 1: numpy.arange(6)")
print(numpy.arange(6))
print("")
print("Ex. 2: numpy.arange(6).reshape(2,3)")
print(numpy.arange(6).reshape(2,3))
print("")
print("Ex. 3: numpy.arange(6).reshape(-1,1)")
print(numpy.arange(6).reshape(-1,1))
print("")
print("Ex. 4: numpy.arange(6).reshape(2,-1)")
print(numpy.arange(6).reshape(2,-1))
print("")
print("Ex. 5: numpy.arange(5).reshape(3,-1)")
print(numpy.arange(5).reshape(3,-1))
print("")
Agora que você entendeu o reshape(), voltamos ao tutorial rodando uma regressão linear:
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# cria um vetor com uma coluna da variavel rm (sera a variavel independente)
rm = numpy.array(boston_df["rm"]).reshape(-1,1)
# cria um vetor com uma coluna da variavel medv (sera a variavel dependente)
medv = numpy.array(boston_df["medv"]).reshape(-1,1)
# separa em treino e teste
X_train, X_test, y_train, y_test = train_test_split(rm, medv, test_size=0.2, random_state=42)
linreg = LinearRegression().fit(X_train, y_train)
print('linear model coeff (w): {}'.format(linreg.coef_))
print(list(map('linear model intercept (b): {:.3f}'.format,linreg.intercept_))) # tive que mudar por erro na formatacao
print('R-squared score (training): {:.3f}'.format(linreg.score(X_train, y_train)))
print('R-squared score (test): {:.3f}'.format(linreg.score(X_test, y_test)))

Note que para apresentar o valor do intercepto tivemos que fazer uma mudança na função. Isso porque há uma diferença na formatação do valor que impediu o uso do script tradicional. Via de regra, utilizar print(‘linear model intercept (b): {:.3f}’.format(linreg.intercept_)) funciona!
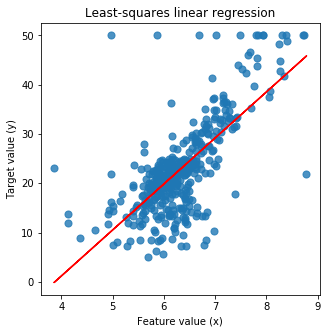
Podemos traçar o gráfico dessa regressão:
import matplotlib.pyplot as plt
plt.figure(figsize=(5,5))
plt.scatter(X_train, y_train, marker= 'o', s=50, alpha=0.8)
plt.plot(X_train, linreg.coef_ * X_train + linreg.intercept_, 'r-')
plt.title('Least-squares linear regression')
plt.xlabel('Feature value (x)')
plt.ylabel('Target value (y)')
plt.show()
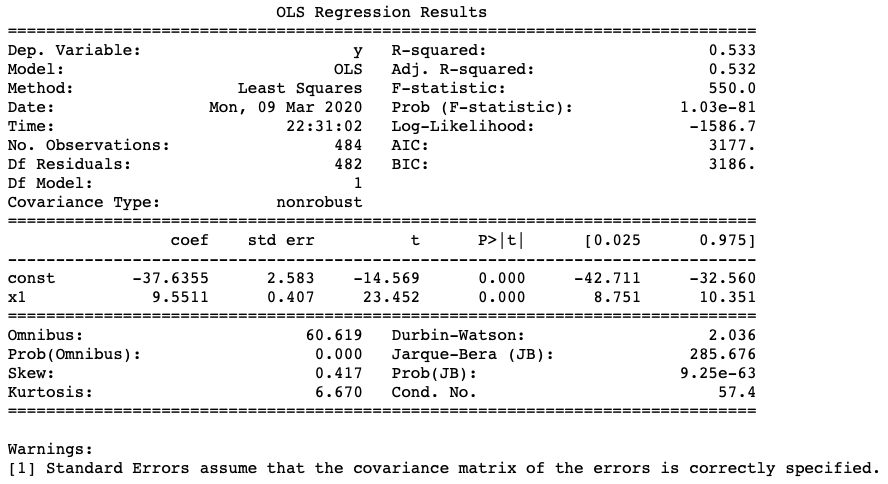
Como alternativa, você pode usar o statsmodels ao invés do sklearn:
import pandas as pd import numpy as np from sklearn import datasets, linear_model from sklearn.linear_model import LinearRegression import statsmodels.api as sm from scipy import stats X2 = sm.add_constant(X_train) est = sm.OLS(y_train, X2) est2 = est.fit() print(est2.summary())
Por hoje, ficamos aqui. Esse tutorial, por mais breve que tenha sido, engloba muito do dia à dia de um cientista de dados, pode acreditar. Claro, há modelos mais robustos, há bases mais bagunçadas. No entanto, saiba que com esse conteúdo aqui você já pode avançar bem nos estudos e, claro, no trabalho. Ponha em prática esses conhecimentos!
Caso tenha dúvidas, me envie um e-mail, comente o post ou mande uma DM em alguma rede social. Caso queira ver o Jupyter Notebook (recomendadíssimo!), acesse https://github.com/yukioandre/Python/blob/master/ml-do-zero.ipynb. Recomendo também que acesse outros posts sobre tratamento de bases, como o Tutorial: Limpeza e Análise de Dados com Python na Prática.
Gostou do conteúdo? Se inscreva para receber as novidades! Deixe seu e-mail em INSCREVA-SE na barra à direita, logo abaixo de pesquisar. E, por favor, não deixe de comentar, dar seu feedback e compartilhar com seus amigos. De verdade, isso faz toda a diferença. Você também pode acompanhar mais do meu trabalho seguindo a conta de Twitter @EstatSite ou por alguma das redes que você encontra em Sobre o Estatsite / Contato, como meu canal de Youtube Canal do Yukio.
Bons estudos!
Sou iniciante em análise de dados em jupyter notebook, Estou gostando do seus post’s, Continue postando o que você acha que os iniciantes de análise devem saber sobre esse universo dos dados, Deus Nos Dê inteligência.
Que bom que esta gostando Julio. Nao sei se vc tem Twitter, mas la rola bastante troca de ideia no @EstatSite tambem. Em breve vou postar outros modelos de Python aqui tambem. Bons estudos e pode chamar para o que precisar!