Há várias formas de se obter estatísticas descritivas no Python. A mais comum é utilizando o describe(). Porém, essa função não é tão útil quando precisamos de resumos por grupo. Imagine, por exemplo, tentar obter a idade média dos clientes por estado, ou por gênero. Além dessa flexibilização, seria interessante também poder fazer um resumo de alguma métrica criada por você. O post de hoje é, claro, sobre isso. Vamos obter um resumo estatístico agrupando por categoria, além de incluir funções criadas por nós mesmos, em Python. Continuar a ler “Resumo Estatístico Agrupando por Categoria em Python”
Etiqueta: estatística descritiva
Machine Learning do Zero no Python
Recentemente, estive na Python Brasil 2019. Um evento muito legal, falei um pouco sobre ele no Twitter do EstatSite (veja a thread aqui), e, inclusive, estou devendo um post aqui no blog. Acabei participando de um tutorial chamado “Machine Learning do Zero”, dado pelo Tarsis Azevedo – o cara é fera, recomendo que acompanhem o trabalho dele pelo Twitter ou Github, @tarsisazevedo. Aqui, vai o código feito em sala de aula, com algumas alterações e comentários que inclui porque achei relevante – outras porque achei que poderia facilitar para os mais novos
Atualização: Vocês agora podem visitar o post Regressão Linear no Python para aprender mais sobre regressão linear utilizando Python! Continuar a ler “Machine Learning do Zero no Python”
Como obter a moda no R
Moda é uma medida de tendência central. A definição é simples: é o valor que aparece com maior frequência nos seus dados. Exemplo: a moda do conjunto {1,1,2,2,3,3,3,4} é 3. Hoje, vamos ver como obter essa métrica no R!
Média Truncada (Trimmed Mean)
Já falei de estatística descritiva algumas vezes (como em Estatística Descritiva), mas nunca mencionei a média truncada, principalmente porque eu quase não uso.
A média truncada nada mais é do que a média desconsiderando algum percentil, o que a faz útil se você quer desconsiderar os outliers. Se você quiser calcular a média truncada de um conjunto de 10 observações, você vai retirar a primeira e a última observação, para depois calcular a média.
Por exemplo: Qual a média truncada de 10% de {1,2,2,2,2,2,2,2,2,10}?
Será (2+2+…+2)/8 = 2
E se quisermos calcular no R?
dados = c(1,2,2,2,2,2,2,2,2,10); mean(dados, trim=.1); [1] 2
Simples!
Proc Means
No SAS, uma das melhores formas de se obter estatísticas descritivas é através do proc means. Além de ser possível obter média, mediana e moda, você consegue diferentes faixas de percentil, observações missing e até mesmo gerar estatísticas cruzando variáveis.
Veja algumas maneiras de se utilizar o proc means com a nossa conhecida base german_credit_2:
1. Primeiro, vamos obter algumas informações para a variável DurationOfCreditMonth utilizando o proc means da maneira mais simples possível:
proc means data= german_credit_21; var DurationOfCreditMonth; run;
2. Em alguns momentos você pode precisar gerar as informações segregadas por diferentes grupos. Por exemplo, você pode precisar da mediana da dívida dos clientes por cada estado, ou a média das notas dos alunos por matéria. Em nosso exemplo, vamos observar como a variável DurationOfCreditMonth se diferencia entre clientes com Creditability = 1 e Creditability = 0:
proc means data=tmp.german_credit_21; class Creditability; var DurationOfCreditMonth; run;
3. Média, mediana e desvio padrão são medidas interessantes e auxiliam na interpretação dos números. No entanto, você pode estar interessado em entender mais a respeito da distribuição desses números. Uma forma de entender isso, é através de algum percentil:
proc means n mean std p10 p25 p50 p75 data=tmp.german_credit_21; class Creditability; var DurationOfCreditMonth; run;
4. Agora que você já possui alguns números para entender melhor a variável, pode ser uma boa ideia deixar o seu resultado mais limpo limitando a duas casas decimais com o maxdec:
proc means n mean std skew p10 p25 p50 p75 data=tmp.german_credit_21 maxdec=2; class Creditability; var DurationOfCreditMonth; run;
5. Não é tão interessante quanto os primeiros itens, mas salvar seus resultados em uma tabela – que aqui chamamos de tabela_saida – pode ser útil, principalmente em processos mais automáticos:
proc means data=tmp.german_credit_21; class Creditability; var DurationOfCreditMonth; output out=tabela_saida sum=soma mean=media p50=mediana; run;
6. Outra coisa que podemos fazer, semelhante ao que fizemos no item 2, é gerar essas medidas para mais variáveis dividindo todas pelo Creditability ou então, gerar as medidas da variável por outras classes:
proc means data=tmp.german_credit_21; class Creditability; var DurationOfCreditMonth Purpose; output out=tabela_saida sum=soma mean=media p50=mediana; run;
proc means data=tmp.german_credit_21; class Creditability Purpose; var DurationOfCreditMonth; output out=tabela_saida sum=soma mean=media p50=mediana; run;
BÔNUS:
Para incluir os dados missing e ainda contar o número de observações missing, acrescente missing e nmiss no proc means:
proc means data= <nome da base> missing nmiss; class <classe - nao obrigatorio>; var <variavel>; run;
Demonstrando dados com a função aggregate no R
A função aggregate no R é bem interessante. Como o próprio nome diz, ela agrega as informações de um dataframe, incluindo alguma função que é especificada por um parâmetro chamado FUN. Sendo assim, é algo bem interessante para você analista ou cientista de dados! Continuar a ler “Demonstrando dados com a função aggregate no R”
Média Móvel: Explicação, Comando SAS e Função LAG
A maioria das pessoas conhece e utiliza a média no dia a dia. O que alguns não conhecem é a média móvel. O que seria isso?
A média móvel nada mais é do que a média de um determinado número de observações recentes. Por exemplo, suponha que você seja dono de uma oficina e venda peças para automóveis. Suas vendas trimestrais estão representadas pela tabela abaixo:
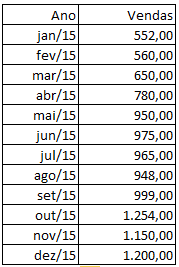
Você é cauteloso com o seu orçamento, e, para decidir quanto gastar no ano seguinte, você quer verificar a tendência das vendas. Uma alternativa é utilizar a média móvel trimestral, que seria nada mais do que a média dos últimos três meses. Ou seja, você irá sempre pegar a média dos últimos três meses. Isso é útil para verificar se está havendo uma tendência de crescimento ou uma reversão, pois você captura movimentos recentes de vendas:
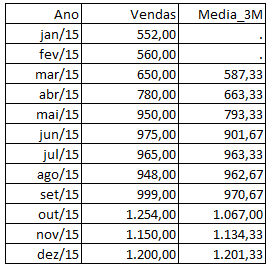
Simples, não?
Bônus – Média Móvel no SAS:
Para calcular a média móvel no SAS você precisará de algo que identifique os meses anteriores ao que você está analisando, isso pode ser obtido com a função lag().
Vamos supor que a tabela do exemplo acima foi criada no SAS com o nome BASE_VENDAS, contendo as variáveis: Ano e Vendas. Ao utilizar LAG(vendas), obteremos a variável vendas com uma defasagem. Ao utilizar LAG2(vendas), obteremos a variável vendas com duas defasagens:
data Variaveis_Defasadas;
set Base_Vendas;
Vendas_M1 = lag(vendas);
Vendas_M2 = lag2(vendas);
run;
Esse é o resultado:
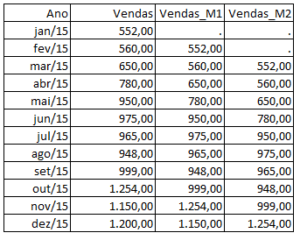
Agora ficou fácil descobrir como chegar a média móvel, certo?
data Media_Movel;
set Variaveis_Defasadas;
Media_3M = SUM(Vendas,Vendas_M1,Vendas_M2)/3;
DROP Vendas_M1 Vendas_M2;
run;
Simples não?
Apenas para sanar quaisquer dúvidas:
SUM = Soma as variáveis, utilizando a vírgula para separá-las.
DROP = Exclui da tabela as variáveis (as colunas) que você não precisa mais.
Estatística, Estatística Descritiva, Inferência Estatística
Para quem já é do ramo parece algo trivial, mas para quem nunca viu, os nomes acima não são tão triviais. Sendo assim, acho que vale a pena explicar rapidamente aqui o que é cada um.
Estatística é o estudo de como coletar, organizar, analisar e interpretar dados. Pense em uma pesquisa eleitoral. Não é possível entrevistar todos os eleitores de um país. Sendo assim, técnicas estatísticas vão nos ensinar como coletar dados de forma a pegar uma amostra que represente a população ou saber quais as falhas a coleta pode ter. Além disso, é preciso saber o que retirar desses dados. Quem vota em qual político, qual a característica dos eleitores que votam no político X e quais as características de quem vota no político Y. Esse é apenas um exemplo dentre tantos que mostram como a estatística é utilizada.
Estatística descritiva é uma forma de sumarizar seus dados de forma quantitativa. É uma forma de resumir a informação que você possui. Pensemos agora em uma sala de aula. A professora tem a nota de todos seus alunos e quer saber como a classe está se saindo. Para isso, ela pode calcular a média, o mínimo, o máximo e o desvio padrão das notas dos alunos. Esses valores são estatísticas descritivas e estão passando para a professora uma ideia, um resumo, de como a sala dela está se saindo.
Por fim, temos a inferência estatística, que é o conjunto de técnicas para tirar conclusões dos seus dados. A inferência estatística é a parte em que a estatística tirará conclusões e deduzirá propriedades da sua população. Após você coletar uma amostra da sua população, você pode tirar algumas estatísticas descritivas dessa amostra mas e depois? Suponha que você queira saber quanto a família brasileira gasta. Você não consegue entrevistar todas as famílias do Brasil. O que você faz? Entrevista algumas e a partir disso, utilizando as técnicas corretas, deduz o quanto a família brasileira gasta. Note que estatística descritiva te dá apenas as informações da sua amostra coletada, sem deduzir nada, diferente da inferência, que é quando você irá traçar conclusões de toda a população com base na sua amostra.
Curtose
A curtose é uma medida que, conforme falado no post anterior, aparece na sua estatística descritiva do excel. Porém, a maioria das pessoas não a conhece. Tranquilão, aqui vai um resumo deboas para você:
O que a curtose nos fornece é simplesmente o quão achatado é o “pico” da nossa distribuição de frequência.
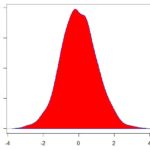
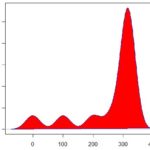
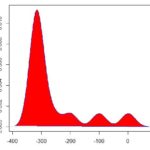
Veja as três distribuições abaixo:
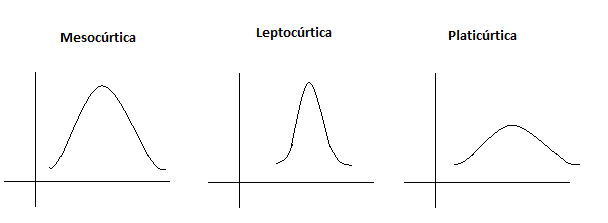
Elas mostram como nossos dados estão distribuídos. No primeiro caso, nossa curva parece uma normal. No segundo gráfico, nossos dados estão mais concentrados no ponto central. Já no último gráfico, nossos dados estão menos concentrados.
Beleza, agora já entendemos o motivo de estudarmos a curtose e o que é exatamente esse “achatamento” do pico. Queremos entender como nossos dados estão distribuídos, simples. E como utilizamos o número que o excel nos fornece?
Só para constar, o que o excel nos dá, colocando de uma forma mais formal, é o que chamamos de excesso de curtose.
Tá, blá blá blá, whatever… o que isso significa?
Significa que se o excel “cuspir” uma curtose próxima de 3, sua distribuição parecerá uma normal, se for menor que 3 então teremos um pico um pouco mais fino e se maior que 3 um pico mais achatado, parecido com aquele terceiro gráfico acima.
E aqueles nomes em cima dos gráficos? É só uma forma mais legal de chamar a nossa distribuição. Só para reforçar, mais uma vez:
Se a curtose for menor que 3, distribuição é leptocúrtica
Se a curtose for próxima de 3 a distribuição é mesocúrtica
Se a curtose for maior que 3 distribuição é platicúrtica.
E se você gostou desse conteúdo, imagine estudar com trilhas estruturadas e projetos práticos, com direcionamento claro do que aprender e em que ordem. No nosso Clube de Assinaturas, você encontra desde o essencial para entrar na área de dados, até temas que diferenciam profissionais mais seniores no mercado, como inferência causal, engenharia de software e álgebra linear aplicada a ML.
Conheça: www.universidadedosdados.com
Estatística Descritiva
Estatística descritiva, como o próprio nome já diz, é uma disciplina (ramo, técnica, etc.), que utilizamos para descrever dados de forma quantitativa.
Quando você está no excel e vai em análise de dados, você pode selecionar estatística descritiva e marcar a caixinha “resumo estatístico” para obter diversas informações a respeito dos seus dados. Farei aqui um breve resumo do que é cada uma das principais estatísticas fornecida pelo Excel.
Antes, vamos lembrar algumas definições básicas.
A média, mediana e moda, são chamadas de medidas de tendência central. Como o próprio nome diz, elas fazem referência ao centro da nossa distribuição. Ou seja, onde nossos dados estão centrados, qual o “meio” da nossa distribuição.
Em contrapartida, mediana, variância e desvio padrão são medidas de dispersão. Servem para mostrar o quanto nossos dados estão dispersos.
Por exemplo, suponha que a gente tenha duas cidades, A e B, com 10 moradores cada e com os seguintes salários:
Cidade A: $200, $200, $200, $200, $200, $200, $200, $200, $200, $200;
Cidade B: $10, $10, $10, $10, $10, $100, $100, $100, $100, $1550.
A média da cidade A e da cidade B é $200, mas o desvio padrão da cidade A é 0 e da cidade B é 451,99. Ou seja, os dados da cidade B estão bem mais dispersos. Podemos ver que os salários na cidade A são bem distribuídos, enquanto na cidade B há uma diferença significante entre os salários. Por esse motivo, é importante conhecermos tanto as medidas de tendência central, quanto as medidas de dispersão.
Vejamos agora as principais estatísticas fornecidas pelo Excel e o que significa cada uma:
- Média: Média aritmética da sua amostra, provavelmente a estatística mais conhecida e utilizada por todos, imagino que não precise de muita explicação. Nada mais é do que a soma das suas observações dividido pelo número de observações.
- Erro padrão: Estima a variabilidade de suas amostras, sua fórmula é o desvio padrão dividido pelo tamanho da amostra.
- Mediana: Valor que está no centro da sua amostra, metade dos valores está acima deste número e metade abaixo. Na cidade A a mediana é 200 e na cidade B é 55, pois (10+100)/2 = 55.
- Moda: Valor que aparece mais vezes nos seus dados. Na cidade A a moda é 200 e na cidade B é 10.
- Desvio padrão: Mede o quanto seus dados variam com relação a média.
- Variância: Essa medida vai te dar a dispersão dos seus dados com relação a média, mas em uma dimensão que será o quadrado da dimensão dos seus dados.
- Curtose: Também é uma medida para indicar a dispersão dos seus dados, mas nesse caso, a estatística nos dará o quão achatado é o gráfico da função de probabilidade dos nossos dados. Falaremos mais dessa medida em um post futuro, por enquanto, ficamos com a definição mais básica de que uma Curtose próxima de zero indica uma distribuição normal.
- Assimetria: Nos dá a simetria da distribuição dos nossos dados. Como assim? Bem, se você desenhar a curva de distribuição dos seus dados, você pode ter algo parecido com uma normal, uma curva um pouco mais concentrada a direita e caindo quando vai para a esquerda, ou o contrário. É isso que a essa medida do excel nos ajuda a entender. Uma distribuição simétrica, que tem o formato de um sino, terá assimetria igual a 0. No entanto, se a distribuição possuir uma maior concentração de dados a esquerda, o valor dessa estatística será negativo.