Na vida real, as bases são bem diferentes do que costumamos ver na academia ou até mesmo em sites como o Kaggle. Sendo assim, é importante saber como lidar quando se deparar com um conjunto de dados em que haja algo faltando, em que existam campos missing. Vamos aprender como localizar linhas e colunas com missing, além de preencher essas células com algum valor. Bora aprender como tratar missing no python!
CONSTRUÇÃO DO DATASET
Primeiro, vamos criar uma base para trabalhar. Como de costume, gosto de simular uma situação real. Aqui, mais uma vez, trabalhamos em uma loja. Nossa base contém as informações a respeito das compras dos clientes. O primeiro campo se chama id e é uma chave única de identificação do cliente (como um CPF ou RG). Em seguida, temos a idade do cliente, o valor da compra realizada e a UF de onde a compra foi feita:
# importa biblioteca
import pandas as pd
# cria os campos
d = {
'id': ['AA123', 'BB123', 'BB123', 'CC256', 'DD777', 'DD799'],
'idade': [30, 50, 50, float("NaN"),35, float("NaN")],
'valor': [500, 250, 250, 300, 350, 200],
'UF': ['BA','MG','MG','BA','BA', 'BA']
}
# cria dataframe contendo os campos
df = pd.DataFrame(data=d)
# mostra o dataframe criado
df
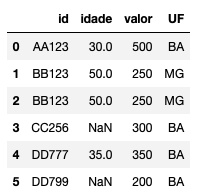
Repare que nosso dataframe é pequeno, portanto podemos apresentá-lo por completo. Caso fosse uma base gigante, seria interessante utilizar o comando df.head(), pois este mostraria somente as primeiras linhas.
IDENTIFICANDO MISSING
A primeira coisa – ou uma das primeiras – que costumamos fazer quando pegamos uma base qualquer é dar uma olhada nas descritivas das variáveis usando o describe(). A primeira linha da função apresenta a contagem de valores, sendo assim, o total de linhas menos esse valor de contagem é a quantidade de missing:
df.describe()
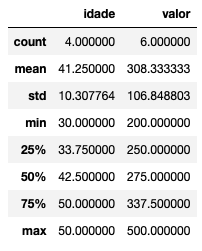
Sabemos que temos 6 linhas ao todo. Logo, há duas linhas em que a variável idade não foi preenchida. Mas e se você não souber quantas linhas tem na sua base? Utilize a função shape, ela retorna o número de linhas e colunas:
df.shape
Bom, estamos aqui para aprender como tratar missing no Python, logo, iniciamos identificando quais células estão com valores missing. Para isso, utilizamos isnull(). Veja o que a função faz:
# mostra tudo que eh nulo no df df.isnull()
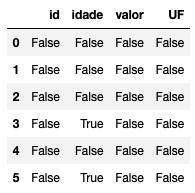
A função nos retorna se o campo é missing (True) ou não (False). O problema dela é que se tivermos uma base muito grande, não vamos conseguir olhar todas as linhas e identificar o que está nulo. Podemos então gerar somente as linhas que possuem missing em alguma das colunas:
df[df.isnull().any(axis=1)]
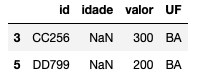
Mas e se não quisermos ver todas as colunas? E se estivermos olhando somente para algum campo específico? Afinal, temos casos em que as bases contém inúmeras colunas, não dá para analisar tudo e nem é de nosso interesse na maioria das vezes.
# verifica quais linhas possuem idade missing df[df.idade.isnull().any(axis=1)]
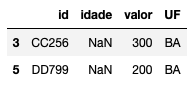
E se quisermos contar quantas linhas possuem missing?
# Contagem de todas linhas com algo missing df.isnull().sum() # para obter o percentual, utilize .mean()

EXCLUINDO LINHAS COM VALORES FALTANTES
Agora sim, vamos finalmente aprender como tratar os campos missing no Python. A primeira opção é remover essas observações, i.e. as linhas que possuam algum missing, caso isso não interfira em nossa análise:
# Remover Linhas com NA df_2 = df.dropna() df_2
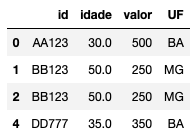
Repare que eu optei por criar um novo dataframe nesse caso. Se eu não me importasse em alterar o original, poderia simplesmente utilizar o comando df.dropna(inplace=True).
PREENCHENDO CAMPOS MISSING
Bom, sabemos muito bem localizar e até remover os campos missings. Mas e se quisermos manter esses campos? Pense que toda vez que você remove esses campos, você perde um pouco do poder preditivo do seu modelo. Você está perdendo um indivíduo por causa de uma variável missing. Uma forma diferente de lidar com missing é substituindo os valores nulos pela média ou mediana da coluna:
# substituir o missing pela mediana da coluna df.fillna(df.median())
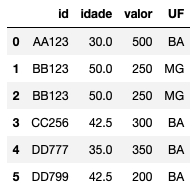
Note que não utilizamos o argumento “inplace=True”. Logo, df não foi alterado:
# Note que nao foi preenchido, pois nao utilizamos o inplace df
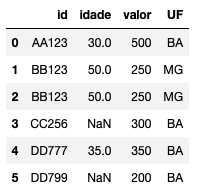
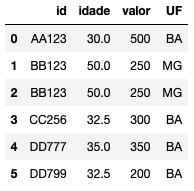
Por fim, imagine que você entenda que o valor da coluna como um todo não é a melhor aproximação para aquele valor nulo. Você acha que o melhor seria preencher calculando o valor por UF. Em outras palavras, preencher os campos nulos com a média (ou mediana) do valor agrupado (group by) por UF. Vamos combinar o group by com o fillna:
# substituir missing de acordo com a media por estado (aqui, usaremos inplace)
med = df.groupby('UF')['idade'].transform('mean')
df['idade'].fillna(med, inplace=True)
df
CONCLUSÃO
Agora sim, você está pronto para lidar com campos missings / nulos quando receber uma base incompleta. Veja que a forma de lidar, preenchendo com algum valor ou simplesmente excluindo a linha, varia de acordo com cada situação. Muitas vezes excluir uma linha ou outra sequer vai atrapalhar no todo e pode ser mais rápido e fácil. Em outros casos, para não perder muita informação, você pode optar por preencher com a média, mediana ou até mesmo com um valor fixo. Se estiver trabalhando com variáveis categóricas, criar uma nova categoria para o missing é uma opção também.
E aí? Gostou do conteúdo? Se inscreva para receber todas as novidades. Deixe seu e-mail em INSCREVA-SE na barra à direita, logo abaixo de pesquisar. E, por favor, não deixe de comentar, dar seu feedback e, principalmente, compartilhar com seus amigos. De verdade, isso faz toda a diferença. Além disso, você também pode acompanhar mais do meu trabalho seguindo a conta de Twitter @UniDosDados, no Instagram @universidadedosdados ou por alguma das redes que você encontra em Sobre o Estatsite / Contato, como meu canal de Youtube Canal Universidade dos Dados.
Aproveite e adquira sua camiseta de data science na LOJA DA UNIVERSIDADE DOS DADOS. Vai ficar estiloso e me ajudar neste projeto!
BONS ESTUDOS
Gostei, parabéns. O post me ajudou a entender uma dificuldade que estava tendo.
Uma dúvida:
# substituir o missing pela media da coluna
df.fillna(df.median())
Não seria mediana, já que média seria mean()?
Abraço!
Opa, é isso mesmo! Vou arrumar o post, obrigado pelo feedback e pelo aviso. Abraços!