E finalmente chegou o grande dia! O desafio está lançado! Não esqueça, os dados que serão utilizados estão todos aqui. Se precisar entrar em contato por conta de alguma dúvida, o ideal é através da DM do Twitter, que é o @EstatSite. Lá é o local onde eu estou mais ativo.
O desafio ficará aberto por uma semana. Se estiver demorando, não se preocupe, é assim mesmo. Não é desafio de uma ou duas horas, vai levar tempo. Não desanime, lembre-se de que tem prêmio por participação (além do aprendizado que você vai ganhar!). Aceitarei entregas até o domingo dia 07/06/2020.
E, não se esqueça, assim que terminar envie a solução para estatsite@gmail.com! Boa sorte!!!
1. Utilizando o dataset Fifa19: Se fossemos classificar a força dos clubes de acordo com a média do campo Overall de seus jogadores, considerando somente clubes com pelo menos 25 jogadores, qual seria o clube mais forte? E o mais fraco?
2. Utilizando o dataset Fifa19: Se fossemos olhar somente para os 20 melhores jogadores de cada seleção, qual nação teria o time mais forte utilizando o critério da média do Overall de seus jogadores? Em outras palavras, filtre somente os 20 melhores jogadores de cada seleção, sendo o critério de “melhor” o campo Overall, e, utilizando o mesmo campo, verifique qual seleção tem a melhor média.
3. Utilizando o dataset Fifa19: Neste exercício, considere o campo Release Clause como sendo o valor do jogador. Considerando somente os clubes que possuem mais de 25 jogadores, quais são os 5 clubes mais valiosos?
4. Utilizando o dataset Fifa19: Imagine que você é diretor de um clube e possui um certo orçamento para comprar 11 jogadores que irão compor o time titular. Cada jogador é contratado de acordo com a release clause. O presidente deseja trazer jogadores jovens, sendo assim, pede que você não contrate ninguém acima de 29 anos. O presidente também demanda que você não traga nenhuma estrelinha que possa conturbar o elenco, sendo assim, o preço máximo a ser pago por um jogador não pode ultrapassa os 15 milhões de euros. Quais são os 11 jogadores de maior Overall que você consegue trazer para seu clube? Isto, é claro, seguindo as restrições orçamentárias e etárias impostas pelo seu chefe.
Para fins do exercício, desconsidere aqui as posições táticas dos jogadores. Ou seja, traga 11 atacantes se isso for a melhor escolha.
5. Utilizando o dataset Fifa19: Utilizando a tabela com os jogadores que você selecionou no exercício anterior, crie uma coluna chamada High_Price que recebe 1 se a Release Clause do jogador está acima da mediana dos 11 selecionados, e 0 caso contrário.
6. Utilizando o dataset Fifa19: Apresente os histogramas com a distribuição do peso, idade e salário dos jogadores que você escolheu no exercício 4.
7. Utilizando o dataset Iris: Através de um gráfico de dispersão (scatterplot), verifique se há relação linear entre comprimento da pétala (Petal Length) e o comprimento da sépala (Sepal Length). Adicione também diferentes cores aos pontos de acordo com a espécie da flor. A resposta aqui é somente o gráfico, não se preocupe em fazer análises mais aprofundadas.
8. Utilizando o dataset Iris: Primeiro, apague a substring “Iris-” da coluna Species. Em seguida, adicione 3 novas colunas à tabela inicial, sendo que cada coluna receberá uma dummy referente a cada uma das species. Ou seja, você deve criar uma coluna chamada Dummy_Setosa, que recebe 1 se a flor for da espécie Setosa e 0 caso contrário. O mesmo para as demais espécies.
9. Utilizando os Dados Históricos de MGLU3 e LREN3: Mostre através de um gráfico de linhas a evolução do preço de fechamento das duas ações durante os anos de 2017, 2018 e 2019. No mesmo gráfico, trace um gráfico de linhas pontilhadas com a evolução do preço de abertura das duas ações no mesmo período. Utilize cores diferentes para cada linha e insira uma legenda para as cores/linhas. A legenda deve ficar no canto inferior direito, como este exemplo:
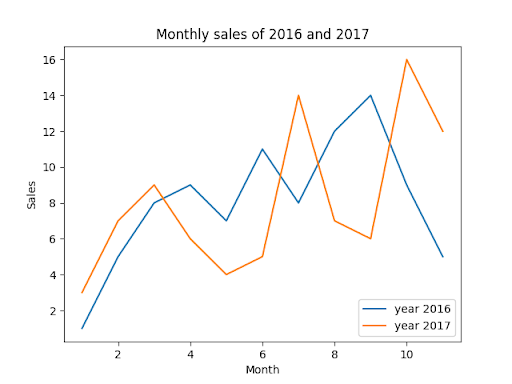
10. Utilizando COMPRAS e CADASTRO: A tabela COMPRAS possui as informações de todas as compras feitas pelos clientes da sua loja. Em CADASTRO, você encontrará as informações cadastrais dos seus clientes. Monte uma nova tabela chamada RESUMO. Essa tabela terá uma linha por cliente e as colunas serão os campos: Id, Idade, Estado, Gasto_Total. As primeiras colunas são auto-explicativas e podem ser obtidas diretamente na tabela COMPRAS. A última coluna deve trazer a soma de todas as compras feitas por cada cliente. Essa tabela é a primeira parte da resposta. A segunda parte será obter a soma, a média e o desvio padrão dos gastos por estado. Isto é, qual a soma, a média e o desvio padrão do campo Total_Gasto para cada estado.
11. Utilizando os datasets COMPRA e CADASTRO: Apresente a distribuição dos campos numéricos da tabela RESUMO através de um boxplot e um histograma. Coloque legenda dos eixos x e y do gráfico.
12. Utilizando os datasets COMPRA e CADASTRO: Sua empresa considera jovem os clientes com menos de 30 anos. A partir disso, elabore um gráfico de barras comparando o gasto médio de clientes jovens e velhos. Ou seja, a altura da barra será o gasto médio do gasto de cada um dos grupos.
Os 3 últimos exercícios envolvem lógica de programação e construção de funções. Se você nunca passou por uma aula formal de computação, talvez estranhe. Mas acredite em mim quando digo que a habilidade trabalhada aqui é importantíssima para a carreira de um cientista de dados.
Dica: Muitos desses exercícios possuem resolução em linguagens mais tradicionais como C++ e Java na internet. Adapte-as para o R/Python!
13. Crie uma função que, dado um número X, faça duas coisas: (1) retorna os números pares de 1 a 9 que não fazem parte de X; (2) retorna uma mensagem indicando se o número é par ou ímpar. Exemplo: se passarmos o número 239, a função deve retornar 4, 6, 8 e “ímpar”. Pode ser em forma de duas mensagens ou uma mensagem com os números e a definição de par ou ímpar. A escolha é sua.
14. Escreva uma função que receba uma string e retorne a mesma string sem nenhuma letra repetida. Exemplo: se a função receber a palavra “casa”, ela deve retornar “cas”.
15. Escreva uma função chamada return_percentile que receba como entrada um array de dimensão (N,1) e um percentile qualquer, e retorne o valor referente a este percentile. Não vale usar as funções percentile, quartile, etc.
Exemplo de aplicação:
> X = [0,1,2,3,4,5,6,7,8,9,10]
> return_percentile(X, .9)
output: 9
Acabou? Envie sua resolução para estatsite@gmail.com. Não se esqueça de mencionar se posso divulgar seu nome caso você esteja no top 5.
E não se esqueça de seguir a conta @EstatSite no Twitter e o Canal do Yukio no Youtube para concorrer aos livros.
Demorando muito para resolver? Envie mesmo assim! Todos que mandarem a resolução concorrerão a um vale compras de 10 reais!