No post Introdução aos Pipelines no Scikit-Learn, mostrei alguns exemplos de pipelines utilizando a biblioteca mais famosa para machine learning no Python. Hoje, quero mostrar alguns exemplos de pipelines com diferentes funcionalidades. Sendo assim, será um post bastante direto e prático, mas que deve ajudar bastante o leitor. Bora ver logo exemplos práticos de pipelines usando scikit-learn!
RELEMBRANDO PIPELINES
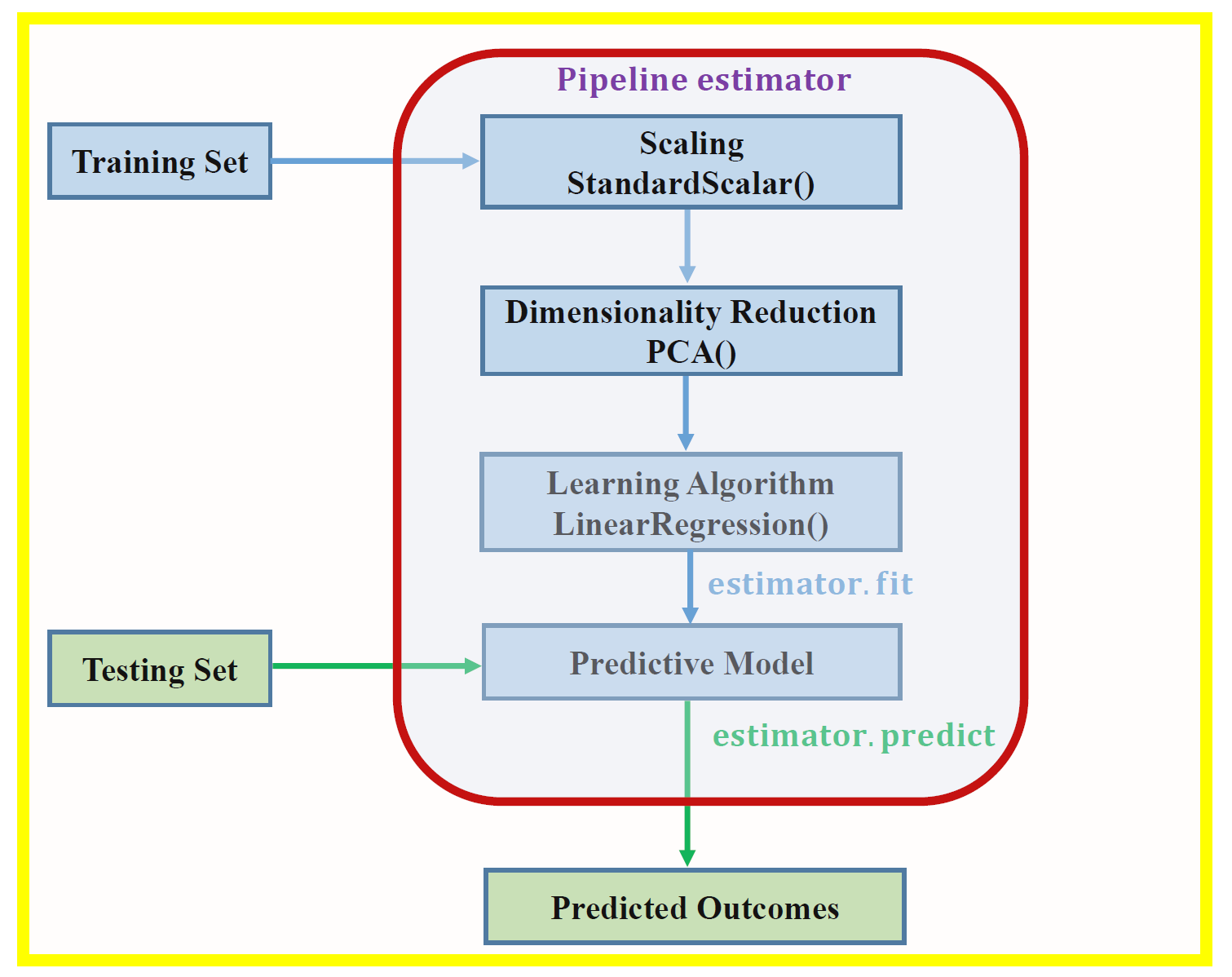
Primeiramente, caso você ainda não saiba o que são pipelines, vá ao post mencionado no primeiro parágrafo e veja a introdução ao conceito e, claro, como usar com scikit-learn (incluindo alguns exemplos como os que veremos aqui). Adicionalmente, creio que a imagem abaixo dará maior clareza ao assunto:
SINTAXES
Primeiro, vamos aprender, ou relembrar, as sintaxes que iremos utilizar.
Pipeline(): Estrutura o passo à passo do procedimento. I.e., aplica sequencialmente uma série de passos especificados pelo usuário. Aqui é onde você diz para seu programa quais passos ele irá seguir para preencher missing e outras coisas, até o modelo que deve ser rodado. Você deve passar o método/função junto com um nome qualquer.
pipe = Pipeline([('transformacao_1', transformacao_1()), ('transformacao_2', transformacao_2()), ... ('transformacao_n', transformacao_n()), ('modelo', modelo())]) pipe.fit(X_train, y_train) pipe.score(X_test, y_test)
Veja um exemplo retirado do próprio site do sklearn:
X, y = make_classification(random_state=0) X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=0) pipe = Pipeline([('scaler', StandardScaler()), ('svc', SVC())]) pipe.fit(X_train, y_train) pipe.score(X_test, y_test)
make_pipeline(): É praticamente a mesma coisa que o Pipeline. A ideia é a mesma, organizar os passos a serem executados. A diferença prática, na hora de escrever o código, é que você não precisa definir nomes para os tratamentos que você está aplicando.
pipe2 = make_pipeline(transformacao_1(), transformacao_2(), ... , transformacao_n(), modelo()) pipe2.fit(X_train, y_train) pipe2.score(X_test, y_test)
ColumnTransformer(): Este transformador serve para especificar em qual coluna a transformação deve ser aplicada. Imagine que você tenha uma coluna numérica contínua e uma categórica. Claramente, você precisará de tratamentos diferentes para cada uma delas. Enquanto na primeira podemos preencher valores nulos com a mediana e normalizar os dados, para a segunda podemos preencher os valores nulos com o valor mais frequente. De qualquer forma, um não consegue copiar os tratamentos do outro. O ColumnTransformer() permite que você especifique isso. Seu uso é bem simples, deve-se nomear o tratamento, especificar qual ele deve ser e especificar as colunas nas quais ele deve ser aplicado. Seria algo assim:
t = [('nome_transformador1', transformador_numerico, colunas_numericas),
('nome_transformador2', transformador_categorico, colunas_categoricas)]
transformer = ColumnTransformer(transformers=t)
Veja que demos um nome para o transformador, os passos que ele deve seguir e as colunas nas quais ele será aplicado. Na prática, você veria algo assim:
t = [('num', SimpleImputer(strategy="median"), colunas_numericas),
('cat', SimpleImputer(strategy="most_frequent"), colunas_categoricas)]
transformer = ColumnTransformer(transformers=t)
Mas e se você precisar de vários tratamentos? Use o próprio Pipeline!
numeric_transformer = Pipeline(
steps=[("median_imputer", SimpleImputer(strategy="median")), ("scaler", StandardScaler())]
)
categorical_transformer = Pipeline(
steps=[('freq_imputer', SimpleImputer(strategy='most_frequent')]
)
# aplica transformador numerico nas colunas 0 e 1 e categorico nas 2 e 3
t = [('num', numeric_transformer, [0, 1]), ('cat', categorical_transformer, [2, 3])]
transformer = ColumnTransformer(transformers=t)
EXEMPLOS COM REGRESSÃO LOGÍSTICA
Agora, ficou simples, você só precisa utilizar o pipeline para englobar todas as tratativas da sua base e o fit do modelo. Inicialmente, vamos ver um exemplo de um estimador dummy:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.dummy import DummyClassifier
# Tratamento de variaveis categoricas com one-hot encoding
# e standard scaler nas variaveis continuas
preprocessor = ColumnTransformer(transformers=[('OneHot', OneHotEncoder(), variaveis_categoricas),
('Scaler', StandardScaler(), variaveis_continuas)])
# Nosso pipeline utilizará o preprocessor e executara o modelo dummy
model = Pipeline([('preprocessor', preprocessor),
('logit', DummyClassifier())])
# Agora treinamos o modelo
model.fit(X_train, y_train)
# Realiza as previsões
y_pred = model.predict(X_test)
# Acurácia do modelo
accuracy_score(y_test, y_pred)
Veja como funciona o Pipeline() junto com o ColumnTransformer():
- Primeiro, utilizamos o ColumnTransformer() para definir qual tratamento será aplicado para qual variável. Em outras palavras, fazemos algumas tratativas para variáveis numéricas contínuas e outros tratamentos para variáveis categóricas. Por exemplo, podemos imputar a mediana nos valores nulos da coluna contínua; mas no caso da coluna categórica podemos imputar o valor mais frequente. ColumnTransformer() permite que você especifique qual tratativa deve ser utilizado para qual variável (abaixo, teremos mais exemplos com essa função);
- Agora, já tendo especificado qual tratamento deve ser aplicado em qual variável, utilizamos o Pipeline() para combinar tudo. Pipeline() é utilizado para estruturar quais tratamentos serão aplicados ao dataset. No nosso caso, já resumimos parte dos tratamentos na variável preprocessor. Porém, poderíamos ter feito algo mais simples e direto se todas as variáveis fossem do mesmo tipo. Veja como ficaria um exemplo sem o ColumnTransformer():
model = Pipeline([('imput', SimpleImputer(Strategy="median"), ('logit', DummyClassifier())])
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
- Por fim, “fitamos” o modelo. Vamos treinar nosso modelo com X_train e y_train.
O classificador dummy nada mais é do que um classificador que utiliza regras básicas. Em outras palavras, ele vai usar algum preditor “idiota” como por exemplo predizer que todos os valores serão iguais a zero – ou a um, dependendo de qual for o mais frequente. Mais sobre o dummy classifier você encontra aqui.
O exemplo acima eu “roubei” do código de um amigo – salve, Roberto! Note que ele chamou o pipeline de model. Se você preferir, adote o nome pipeline que pode clarificar as coisas:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.dummy import DummyClassifier
# Tratamento de variaveis categoricas com one-hot encoding
# e standard scaler nas variaveis continuas
preprocessor = ColumnTransformer(transformers=[('OneHot', OneHotEncoder(), variaveis_categoricas),
('Scaler', StandardScaler(), variaveis_continuas)])
# Nosso pipeline utilizará o preprocessor e executara o modelo dummy
pipeline_logit = Pipeline([('preprocessor', preprocessor),
('logit', DummyClassifier())])
# Agora treinamos o modelo
pipeline_logit.fit(X_train, y_train)
# Realiza as previsões
y_pred = pipeline_logit.predict(X_test)
# Acurácia do modelo
accuracy_score(y_test, y_pred)
Veja que ele não utilizou nenhuma tratativa para valores missing. Todavia, isso também pode ser incluído num pipeline comum. Veja um outro desenho para um pipeline, dessa vez incluindo imputação de missing e sem o ColumnTransformer():
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LogisticRegression
# it takes a list of tuples as parameter
pipeline = Pipeline([
('imputer', SimpleImputer(strategy='median'))
('scaler',StandardScaler()),
('clf', LogisticRegression())])
# fit do modelo
pipeline.fit(X_train,y_train)
# predict no teste
pipeline.predict(X_test, y_test)
OUTROS EXEMPLOS: make_pipeline() + ColumnTransformer()
Agora, vamos ver um exemplo que utilizei num projeto do Datacamp. Você pode ver o código do projeto e meu código, onde utilizei pipeline, neste link: https://github.com/yukioandre/courses/tree/master/datacamp/project-classify-song-genres-from-Audio-Data.
Você vai notar que eu não precisaria ter aplicado o transformador de coluna no exemplo do projeto. Simplesmente o fiz porque achei que facilitaria ter isso estruturado para programas futuros. E aqui você verá como usar o make_pipeline(), ao invés do Pipeline():
# Usaremos columntransformer mesmo nao precisando
# Só para deixar o código já estruturado
num_transformator = make_pipeline(SimpleImputer(strategy="median"), StandardScaler())
t = [("num", num_transformator,
[
"acousticness",
"danceability",
"energy",
"instrumentalness",
"liveness",
"speechiness",
"tempo",
"valence",
],)]
transformer = ColumnTransformer(transformers=t)
pipe2 = make_pipeline(transformer, RandomForestClassifier())
pipe2.fit(X_train, y_train)
# Fita o modelo
pipe2.fit(X_train, y_train)
# predicoes
y_pred = pipe2.predict(X_test)
OUTRAS POSSIBILIDADES: TEXT MINING
E isso vale para qualquer modelo. Logo, serve para text mining também:
from sklearn.feature_extraction.text import CountVectorizer,TfidfTransformer from sklearn.metrics import f1_score from sklearn.svm import LinearSVC from sklearn.pipeline import Pipeline vect = CountVectorizer() tfidf = TfidfTransformer() clf = LinearSVC() pipeline = Pipeline([ ('vect',vect), ('tfidf',tfidf), ('clf',clf) ]) pipeline.fit(X_train,y_train) y_preds = pipeline.predict(X_test)
TESTANDO DIVERSOS MODELOS
Primeiro, um programinha simples que testa KNN, SVC e Logit junto com StandardScaler():
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
classifiers = [
KNeighborsClassifier(),
SVC(),
LogisticRegression()
]
for clf in classifiers:
pipe3 = Pipeline([('scaler', StandardScaler()), ('clf',clf)])
pipe3.fit(X_train, y_train)
score = pipe3.score(X_test, y_test)
print(clf)
print(score)
Tranquilo, né?
E, para fechar, um exemplo que utilizei num projeto do Datacamp. Veja que a ideia é a mesma: inserir o pipeline num loop que contém uma lista de classificadores.
classifiers = [
KNeighborsClassifier(3),
SVC(kernel="rbf", C=0.025, probability=True),
SVC(),
LogisticRegression(),
DecisionTreeClassifier(),
RandomForestClassifier(),
AdaBoostClassifier(),
GradientBoostingClassifier(),
]
for classifier in classifiers:
pipe = Pipeline(steps=[("preprocessor", preprocessor), ("classifier", classifier)])
pipe.fit(X_train, y_train)
print(classifier)
print("model score: %.3f" % pipe.score(X_test, y_test))
Agora, imagine, você pode ao invés de trocar os classificadores, trocar os tratamentos. Será que seu modelo performa melhor com imput da mediana ou da média? Será que deveríamos aplicar one-hot encoding ou target encoding? Descubra com loop+pipeline!
Creio que os exemplos de hoje foram bem elucidativos e você agora já é capaz de criar seu próprio pipeline sem grandes problemas. Aliás, se tiver algum problema, é só comentar aí que eu te ajudo!
E aí? Gostou do conteúdo? Se inscreva para receber as novidades! Deixe seu e-mail em INSCREVA-SE na barra à direita, logo abaixo de pesquisar. E, por favor, não deixe de comentar, dar seu feedback e, principalmente, compartilhar com seus amigos. De verdade, isso faz toda a diferença. Além disso, você também pode acompanhar mais do meu trabalho seguindo a conta de Twitter @EstatSite ou por alguma das redes que você encontra em Sobre o Estatsite / Contato, como meu canal de Youtube Canal do Yukio. E se você gosta de tecnologia, escute o Pitacotech – disponível no Spotify, Apple Podcasts e demais agregadores.
Bons estudos!