O mais legal de trabalhar com análise de dados é que você pode analisar absolutamente TUDO que você quiser. Já analisei dados do Twitter no post Analisando o Twitter com o R, já me aventurei em dados ambientais (mencionei neste tweet aqui) e, agora, resolvi abrir os dados do Instagram. Se você quer saber como andam seus likes, quem comenta suas fotos, pare de pagar aqueles apps que fazem isso e rode você mesmo um script que traga tudo isso!
DISCLAIMER
Antes de mais nada, os créditos todos para este código vão para o pessoal da Innovi Tech Academy. Tudo que foi realizado aqui está baseado no script que eles publicaram no Medium e que pode ser acessado aqui. O que eu quis fazer aqui foi traduzir o post e adicionar explicações de forma a ajudar mais pessoas, principalmente os que não sabem inglês. Além disso, propus alguns desafios também para quem quiser se aventurar mais ainda nesses dados. Há tanta coisa que pode ser feita que eu tenho certeza de que você vai se empolgar bastante!
A BIBLIOTECA E INICIALIZAÇÃO
Primeiramente, desabilite a autenticação em dois fatores da sua conta – temporariamente apenas, é importante para a segurança dela ter esses dois fatores. Em seguida, instale o pacote InstagramAPI no Python. O jeito mais fácil é indo ao terminal e digitando pip install InstagramAPI. Feito isso, vamos importar algumas bibliotecas:
# BIBLIOTECAS PARA ANALISE
from InstagramAPI import InstagramAPI
import pandas as pd
from pandas.io.json import json_normalize
# PARA QUE O JUPYTER EXIBA MAIS DE UM OUTPUT POR CELULA
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
# OUTRAS BIBLIOTECAS TRADICIONAIS
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import os
import sys
# IGNORA ALERTAS
import warnings
warnings.filterwarnings("ignore")
#### PADRONIZACAO DE GRAFICOS E OUTPUTS ###########
sns.set()
pd.options.display.max_columns = 500
plt.style.use("fivethirtyeight")
plt.rcParams["figure.figsize"] = [10, 5]
%load_ext nb_black
EXTRAÇÃO DOS POSTS
Agora, estamos prontos para começar. Inicie logando na sua conta com a função abaixo. A função InstagramAPI() utiliza como input seu usuário e senha. Quando você a utiliza com seu método .login(), seu acesso é realizado. Vamos utilizar uma função para deixar nosso código melhor estruturado:
def realiza_login(usuario, senha):
api = InstagramAPI(usuario, senha)
api.login()
return api
api = realiza_login('insira seu usuario','insira sua senha')
Obviamente, não vou incluir minha senha e usuário aqui. No entanto, não me parece existir nenhuma dúvida aqui. É bem simples, insira o nome do usuário e a senha na última linha do trecho acima. Após rodar o trecho, você deve receber a mensagem “Login success!” Se quiser acompanhar, as análises aqui foram feitas para o perfil @pitacotech.
Agora, vamos extrair todos os posts do seu perfil. A partir deles, conseguiremos fazer análises das curtidas e comentários:
def extrai_posts(api):
""" EXTRAI POSTS DO PERFIL """
my_posts = []
has_more_posts = True
max_id = ""
while has_more_posts:
api.getSelfUserFeed(maxid=max_id)
if api.LastJson["more_available"] is not True:
has_more_posts = False # stop condition
max_id = api.LastJson.get("next_max_id", "")
my_posts.extend(api.LastJson["items"])
print("Total de posts extraídos: " + str(len(my_posts)))
return my_posts
my_posts = extrai_posts(api)
Cuidado com a identação (o espaçamento). O WordPress não deixa o código no formato adequado, portanto, não copie e cole apenas. Isso não vai dar certo. Escreva o código você mesmo, pelo menos dentro das funções, loops e condicionais.
No meu caso, há somente 25 posts. Portanto, o output da função foi a seguinte mensagem:
Total de posts extraídos: 25
INFORMAÇÕES DE CURTIDAS
Agora é que começa a verdadeira análise. Iniciamos extraindo as informações de curtidas:
def extrai_curtidas(api, meus_posts):
""" EXTRAI AS INFORMAÇÕES DE CURTIDAS """
likers = [] # CRIA UMA LISTA ONDE GUARDAREMOS AS CURTIDAS
print('wait %.1f minutes' % (len(meus_posts)*2/60.))
for i in range(len(meus_posts)):
m_id = meus_posts[i]['id']
api.getMediaLikers(m_id)
likers += [api.LastJson]
# ADICIONA ID DO POST
likers[i]['post_id'] = m_id
# INFORMA O TERMINO
print('done')
return likers
likers = extrai_curtidas(api, my_posts)
Porém, se você digitar likers e executar a célula, vai ver que o resultado é um dict não muito legal de se analisar. Vamos converter esse resultado para um dataframe do Pandas:
def converte_curtidas_em_df(likers):
""" CONVERTE O DICT PARA DATAFRAME """
df_likers = json_normalize(likers, 'users', ['post_id'])
# CRIA UMA COLUNA PARA IDENTIFICAR TIPO DO CONTEUDO
df_likers['content_type'] = 'like'
return df_likers
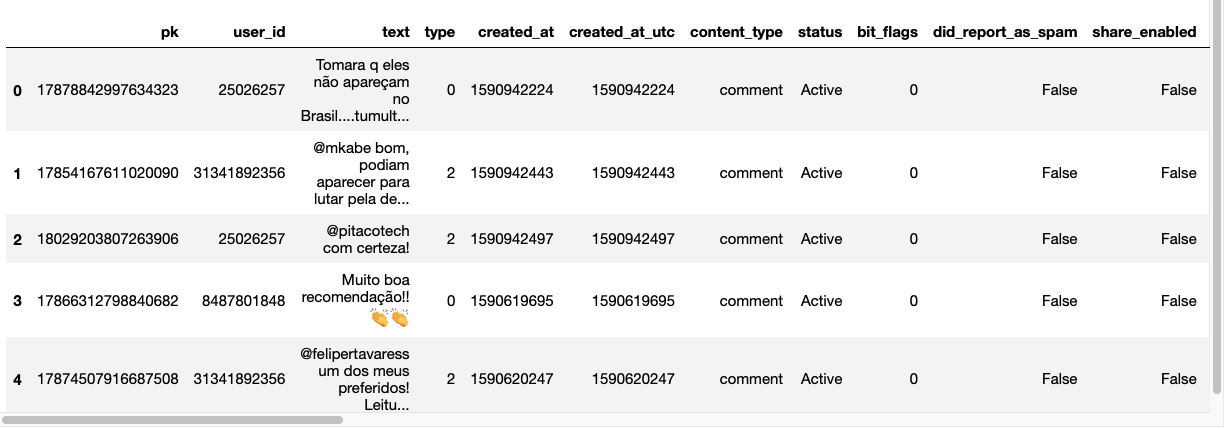
Veja como ficou o dataframe:

Convenhamos, muito melhor de se analisar. Se você é famoso, pode verificar quantas curtidas de outros famosos você recebeu, basta olhar a coluna is_verified. Se você possui um modelo de processamento de imagem, pode analisar as fotos do perfil e ver se é um usuário real ou fake. Enfim, as possibilidades são inúmeras!
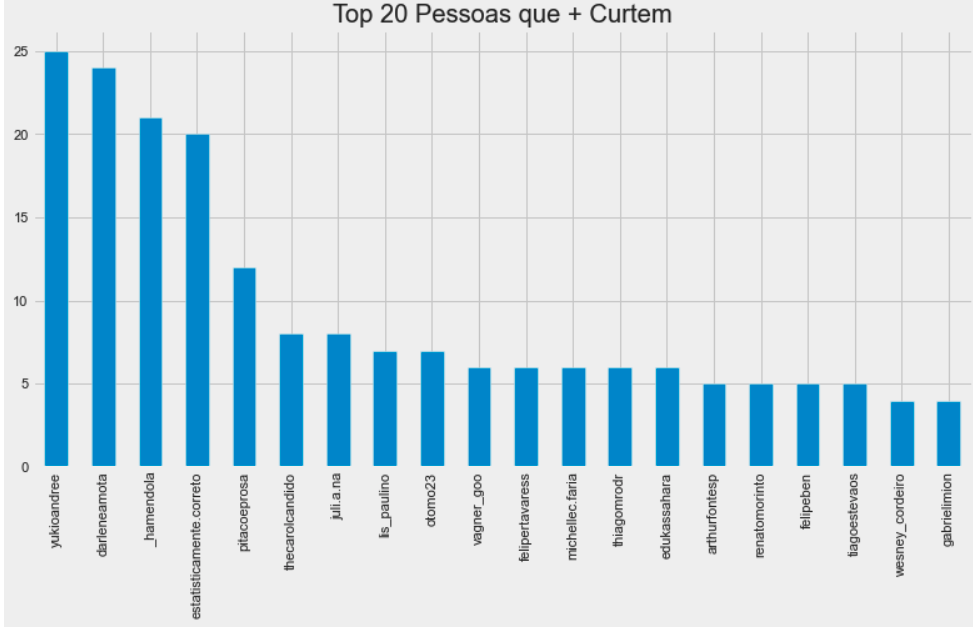
Vamos começar verificando os 20 perfis que mais curtiram posts do pitacotech:
df_likers.username.value_counts()[:20]
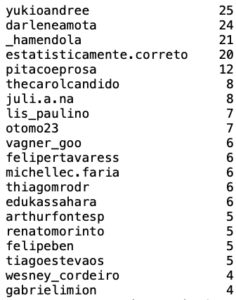
Melhor ainda, é ver essa informação em um gráfico:
INFORMAÇÕES DE COMENTÁRIOS
Com comentários, faremos praticamente o mesmo que fizemos com curtidas. Vamos extrair as informações, converter o dict num dataframe e fazer uma análise gráfica:
def extrai_comentarios(api, meus_posts):
""" EXTRAI AS INFORMAÇÕES DE COMENTARIOS """
commenters = []
print("wait %.1f minutes" % (len(my_posts) * 2 / 60.0))
for i in range(len(my_posts)):
m_id = my_posts[i]["id"]
api.getMediaComments(m_id)
commenters += [api.LastJson]
commenters[i]["post_id"] = m_id
print("done")
return commenters
commenters = extrai_comentarios(api, my_posts)
def converte_comentarios_em_df(likers):
""" CONVERTE O DICT EM DATAFRAME """
for i in range(len(commenters)):
if len(commenters[i]["comments"]) > 0:
for j in range(len(commenters[i]["comments"])):
commenters[i]["comments"][j]["username"] = commenters[i]["comments"][j][
"user"
]["username"]
commenters[i]["comments"][j]["full_name"] = commenters[i]["comments"][
j
]["user"]["full_name"]
df_commenters = json_normalize(commenters, "comments", "post_id")
return df_commenters
df_commenters = converte_comentarios_em_df(commenters)
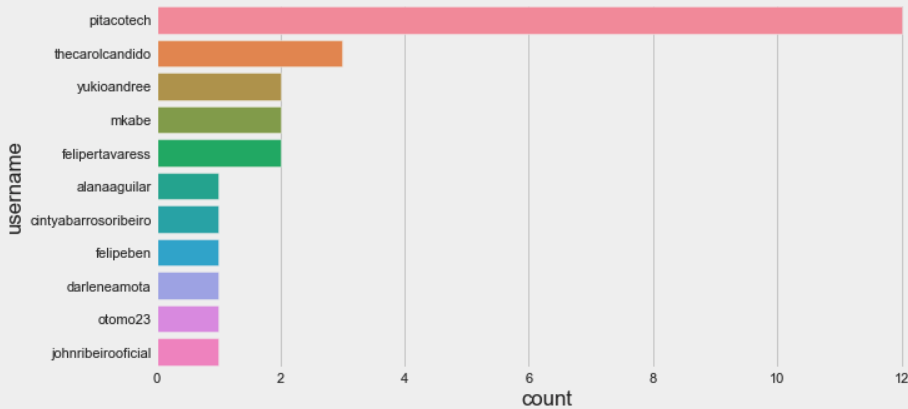
No caso dos comentários, há também inúmeras análises que podem ser feitas. Você pode verificar, por exemplo, se sua marca recebeu comentários positivos ou negativos, se as pessoas estão reportando os comentários como spam e até saber, por processamento de imagem, se as pessoas que estão comentando possuem foto real ou não.
Vamos experimentar um gráfico levemente diferente, pois temos poucos comentários na página:
sns.countplot(
y="username",
data=df_commenters,
order=df_commenters["username"].value_counts().index,
)
Agora, você notou que temos informações de dias da semana no dataframe? Que tal verificar quais dias da semana seus posts são mais comentados? Mais ainda, que tal verificar o horário em que há mais comentários?
Primeiro, tratamos os campos para deixá-los no formato adequado:
df_commenters.created_at = pd.to_datetime(df_commenters.created_at, unit="s") df_commenters.created_at_utc = pd.to_datetime(df_commenters.created_at_utc, unit="s")
Agora, basta plotar os gráficos:
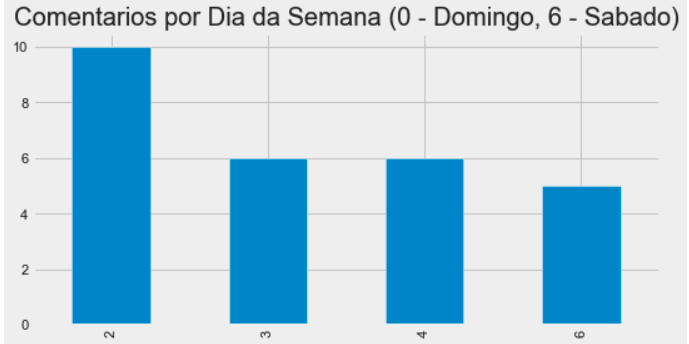
df_commenters.created_at.dt.weekday.value_counts().sort_index().plot( kind="bar", figsize=(8, 4), title="Comentarios por Dia da Semana (0 - Domingo, 6 - Sabado)", )
df_commenters.created_at.dt.hour.value_counts().sort_index().plot( kind="bar", figsize=(8, 4), title="Comentarios por Horario" )
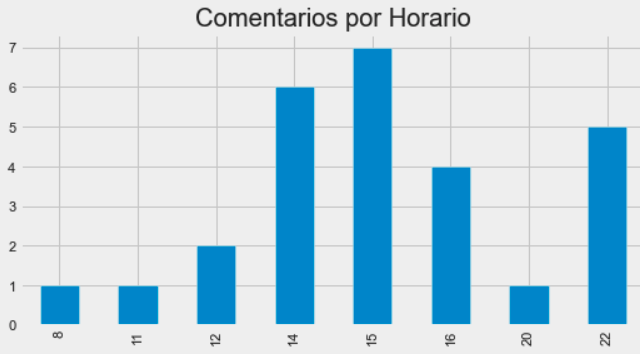
Aparentemente, as pessoas têm comentado mais no início da tarde e no fim do dia. Novamente, que tal fazer um modelo para agrupar pessoas através da semelhança no modo de agir nas redes?
Como você pode ver, há inúmeras possibilidades. Tem muito mais para se analisar do que isso. Aqui, foi muito mais uma introdução e, novamente, com todos os créditos para o pessoal da Innovi Tech Academy.
Gostou do conteúdo? Quer aprender Python com foco em dados, com projetos reais, indo do zero ao avançado?
Conheça nossa plataforma de ensino em análise e ciência de dados: www.universidadedosdados.com
Eu consigo executar o “likers “, mas não consigo converter para um dataframe em Pandas. Executo o código e não acontece nada. Estou usando o jupyter.
Que estranho, Pablo. Tu tem twitter? Chama lá na DM, acho mais fácil. Aí tu mostra os prints e tal. E eu sou mais ativo por lá até hahaha
Yukio, tem como extrair todos os comentários de uma postagem? Ainda não conseguir realizar essa façanha.
Uai, como assim? Nesse script não vem todos os comentários>
Yukio,ao rodar o código da função “realiza_login” tenho o seguinte retorno:
Request return 405 error!
{‘message’: ”, ‘status’: ‘fail’}
Request return 404 error!
Login success!
Sabe como posso resolver estes erros 405 e 404? Desde já agradeço
Vc tá com problema de acessar a conta. Vc usa autenticação com 2 fatores? Este pode ser um dos problemas
Olá, também estou com o mesmo problema, conseguiu resolver? Desde já agradeço.
Estou com o mesmo erro. Mesmo desabilitando a autenticação por 2 fatores. Conseguiu resolver?
Olá,
Seria possível extrair informações semelhantes de um outro perfil que não pertença ao usuário que está fazendo a pesquisa? Por exemplo, em vez de você extrair do seu próprio perfil, logando, como foi feito acima, a análise seria feita com dados de um outro perfil, como por exemplo, o da Prefeitura de São Paulo ou de alguma empresa.
Fala, Marcos!
Não conheço nenhum pacote que faz isso. Deve ser possível, mas não conheço.
Se souber de algo, posto aqui ou em alguma outra rede.
Abraços!
Obrigado pela resposta! Como te acho nas outras redes? Quero te seguir. Obrigado!
Opa, vai no instagram.com/universidadedosdados e no Youtube é Universidade dos Dados 🙂
Obrigado! Passei a seguir nos dois! Até a próxima!
Muito bom, queria saber se tem como eu pegar comentários da playstore? você conhece?
É possivel criar um filtro para carregar somente os posts dos últimos 3 meses?
Fala, Aleff.
Cara, não sei. Me questionaram na DM do Instagram, mas não encontrei uma solução que fizesse isso já na extração.
Vou verificar a possibilidade, mas, por enquanto, a solução é realmente extrair e filtrar na sequência.
Abs
Boa noite!
Estou começando a aprender Python para ciencia de Dados e maravihado!
Veja, tenho um cliente que tem um instagram. Ele me deu acesso para fazer lá as postagens, agendar, etc.
será que com este acesso eu consigo, pelo meu usuário capturar os dados do instagram que está dento do meu facebook business, como ativos?
Obrigado,
Wagner
Opa.
Preciso de uma ajuda. Não consigo rodar o código, ele dá o seguinte erro:
AttributeError: module ‘collections’ has no attribute ‘MutableMapping’
Alguém pode me ajudar?