Introduzi a noção de técnicas de agrupamento no post: Técnicas de Clustering: K-Means. Porém, ficou faltando um exemplo prático de construir o algoritmo por conta própria. Aqui, vou apresentar uma aplicação da técnica utilizando distâncias euclidianas no software Excel.
Etiqueta: clustering
Técnicas de Clustering: K-Means
O que é clustering?
Imagine o dono de uma loja com todo o histórico do que seus clientes compraram. Esse histórico permite que o lojista procure o tipo de produto que o cliente pode se interessar. Porém, fazer isto para cada cliente individualmente não é muito eficiente. Seria mais prático ele separar os clientes por grupos de acordo com a semelhança entre as preferências desses clientes. Assim, ele terá que pensar na recomendação para cada grupo, sendo que o número de grupos seria muito menor que o número de indivíduos.
Sendo assim, o que o lojista precisaria fazer era pensar em como separar os indivíduos, pensando no número de grupos que quer formar e qual critério de separação. Isso pode ser feito através de técnicas de clustering. (traduzido e adaptado de: K-means Clustering Tutorial)
Clustering é o método separar seus dados em grupos (clusters) quando estamos minerando dados. Ou seja, nada mais é do que unir indivíduos de sua base de dados com base em suas semelhanças.
Um algoritmo bastante utilizado é o k-means (traduzido por alguns como k-médias). Este algoritmo serve para agrupar os dados em grupos com base nas distâncias à média.
Vejamos um exemplo para facilitar o entendimento:
Queremos aplicar o k-means nos indivíduos 1,2,3,4,5,6,7,8,9 e 10, que possuem determinados valores em duas variáveis quaisquer X e Y:
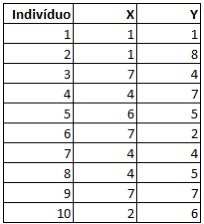
Para a utilizar o algoritmo precisamos escolher o número de grupos que queremos utilizar.
Para facilitar, no nosso exemplo iremos agrupar em dois grupos.
Iniciamos com um grupo contendo o elemento 1 e um outro grupo contendo o elemento 9.

Agora vamos alocar os elementos mais próximos de cada grupo de acordo com a distância entre os pontos. Por exemplo, note que a distância do indivíduo 4 é 6,7 para o Grupo 1, enquanto a distância ao Grupo 2 é 1,4. Logo, ele deve pertencer ao Grupo 2.
Fazemos a mesma comparação para os demais elementos e chegamos a essa divisão:

Note que as médias de cada grupo se alterou. Podemos então reagrupar os elementos, novamente através da distância às médias.
Por exemplo, a distância do indivíduo 4 em relação ao Grupo 1 agora é 3 e em relação ao Grupo 2 é de 3,7. Ou seja, ele agora está mais próximo do Grupo 1.
O mesmo deve ser feito para os demais elementos:

Esse processo é feito sucessivamente até que se encontre o melhor agrupamento, dado o critério de distância à média.
Dúvidas? Críticas? Deixe um comentário!