Uma continuação do post Árvore de Decisão no R, agora vou incluir a probabilidade do cliente ser mau pagador na saída da árvore. Para isso, precisamos apenas complementar o código com a função rpart.plot(), do pacote com mesmo nome:
Etiqueta: decision tree
Árvore de Decisão
Uma das técnicas mais utilizadas para tomada de decisões é a árvore de decisões (em inglês decision trees). Sendo uma técnica capaz de lidar com a não linearidade, fácil de codificar, com poucas premissas e, talvez o mais importante, com resultado fácil de interpretar, a árvore de decisões é comumente adotada para concessões de crédito, diagnósticos médicos, análises de efeitos de drogas, análises de investimentos, etc.
A definição do wikipedia diz: “Uma árvore de decisão é uma representação de uma tabela de decisão sob a forma de uma árvore, porém podem haver outras aplicações. Tem a mesma utilidade da tabela de decisão. Trata-se de uma maneira alternativa de expressar as mesmas regras que são obtidas quando se constrói a tabela.”
Para ficar mais intuitivo, vamos pensar em um exemplo bem simples. O banco XYZ vai fornecer empréstimo a uma pessoa. Porém, sabemos que o banco XYZ não pode emprestar para qualquer um, não é todo mundo que vai pagar. Para decidir se vai ou não emprestar a uma pessoa, o banco XYZ monta um formulário com três perguntas:
- Você possui empréstimo em outros bancos?
- Você é casado?
- Você possui casa própria?
Claro que o exemplo é um pouco banal, pois essa decisão depende de muitas variáveis, mas estamos querendo simplificar. Com base nas suas respostas, o banco deve decidir ou não dar um empréstimo. Ou seja, com base em um conjunto de respostas, o banco decide se você é um bom ou não pagador. Veja na árvore de decisões abaixo, que o banco XYZ, com base nas respostas dos clientes, sabe a probabilidade do cliente pagar ou não o empréstimo. E passa a fornecer crédito, para os clientes com probabilidade acima de 50%, que são os que ele considera bons pagadores:
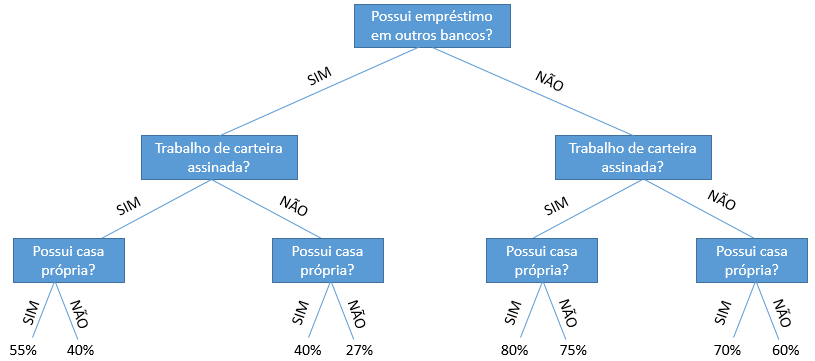
Veja pelo diagrama, como é fácil identificar os clientes com os quais o banco irá fazer negócio. Isso nada mais é do que uma árvore de decisões.
Note que a árvore de decisões é uma ilustração de um algoritmo, um passo a passo que você realiza para tomar uma decisão, nesse caso a de emprestar ou não a um cliente.
E como você chega nessas probabilidades? Bom, lembre-se que já foi falado no blog como fazer modelos estatísticos nesse post. Para a árvore de decisões o raciocínio, normalmente, é o mesmo. Você possui alguns dados de clientes que já tomaram ou não empréstimos, suas características e se eles já pagaram ou não a sua dívida. Com base nisso, você saberá definir as melhores variáveis se baseando nas menor incerteza.
Por exemplo, suponha que o banco XYZ tenha 20 clientes que tomaram empréstimo no passado. Você está tentando decidir entre algumas variáveis para sua árvore de decisão. Para isso, você organiza o diagrama abaixo, sendo que bom é o cliente que pagou a dívida e ruim é o cliente que não pagou a dívida:
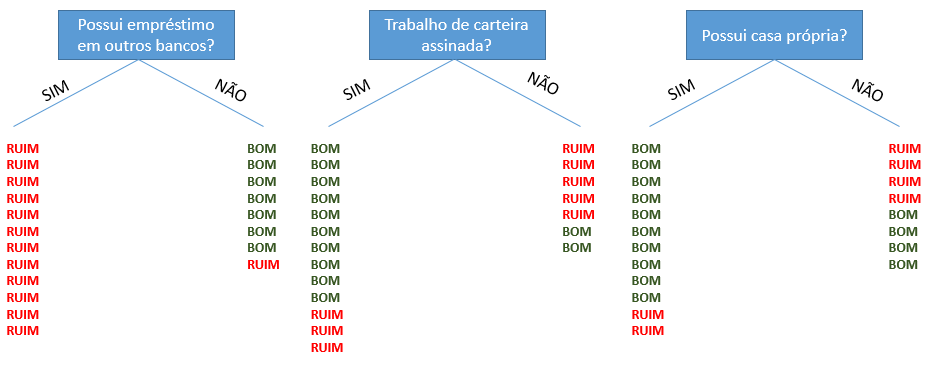
No diagrama, temos que dos 20 clientes da base do banco XYZ, dentre os que tomaram empréstimo em outros bancos, nenhum pagou a dívida. E dentre os que não tomaram, apenas um não pagou a dívida com o banco XYZ.
Com base na incerteza, podemos dizer que possuir empréstimo em outro banco é a melhor.
Veja que essa variável tem zero de incerteza, com base no histórico, todos os clientes que possuem empréstimo em outros bancos são maus pagadores.
E qual a pior variável?
Seguindo a mesma lógica, é a variável possui ou não casa própria. Veja que caso a pessoa não possua casa própria, a gente não consegue decidir se é mais provável que ela seja boa ou má pagadora. É equivalente a jogar uma moeda e decidir na sorte.
Leia também:
Árvore de Decisão no R
Árvore de Decisão com Probabilidade em R