Há várias formas de se obter estatísticas descritivas no Python. A mais comum é utilizando o describe(). Porém, essa função não é tão útil quando precisamos de resumos por grupo. Imagine, por exemplo, tentar obter a idade média dos clientes por estado, ou por gênero. Além dessa flexibilização, seria interessante também poder fazer um resumo de alguma métrica criada por você. O post de hoje é, claro, sobre isso. Vamos obter um resumo estatístico agrupando por categoria, além de incluir funções criadas por nós mesmos, em Python. Continuar a ler “Resumo Estatístico Agrupando por Categoria em Python”
Etiqueta: desvio padrao
Detectando Outliers pelo Desvio Padrão no Python
Detectar outliers é necessário em qualquer análise. Não importa se você pretende excluí-los ou mantê-los, você precisa saber quem são eles. Um dos métodos mais comuns e fáceis é através do desvio padrão. Uma rule of thumb comumente utilizada é: se o indivíduo/ponto estiver a mais de 3 desvios padrões da média, é um outlier. No Python, podemos localizar esses pontos através do código abaixo. Teremos aí df como sendo nosso datarame e coluna_1 como sendo a coluna analisada: Continuar a ler “Detectando Outliers pelo Desvio Padrão no Python”
Estatística Descritiva
Estatística descritiva, como o próprio nome já diz, é uma disciplina (ramo, técnica, etc.), que utilizamos para descrever dados de forma quantitativa.
Quando você está no excel e vai em análise de dados, você pode selecionar estatística descritiva e marcar a caixinha “resumo estatístico” para obter diversas informações a respeito dos seus dados. Farei aqui um breve resumo do que é cada uma das principais estatísticas fornecida pelo Excel.
Antes, vamos lembrar algumas definições básicas.
A média, mediana e moda, são chamadas de medidas de tendência central. Como o próprio nome diz, elas fazem referência ao centro da nossa distribuição. Ou seja, onde nossos dados estão centrados, qual o “meio” da nossa distribuição.
Em contrapartida, mediana, variância e desvio padrão são medidas de dispersão. Servem para mostrar o quanto nossos dados estão dispersos.
Por exemplo, suponha que a gente tenha duas cidades, A e B, com 10 moradores cada e com os seguintes salários:
Cidade A: $200, $200, $200, $200, $200, $200, $200, $200, $200, $200;
Cidade B: $10, $10, $10, $10, $10, $100, $100, $100, $100, $1550.
A média da cidade A e da cidade B é $200, mas o desvio padrão da cidade A é 0 e da cidade B é 451,99. Ou seja, os dados da cidade B estão bem mais dispersos. Podemos ver que os salários na cidade A são bem distribuídos, enquanto na cidade B há uma diferença significante entre os salários. Por esse motivo, é importante conhecermos tanto as medidas de tendência central, quanto as medidas de dispersão.
Vejamos agora as principais estatísticas fornecidas pelo Excel e o que significa cada uma:
- Média: Média aritmética da sua amostra, provavelmente a estatística mais conhecida e utilizada por todos, imagino que não precise de muita explicação. Nada mais é do que a soma das suas observações dividido pelo número de observações.
- Erro padrão: Estima a variabilidade de suas amostras, sua fórmula é o desvio padrão dividido pelo tamanho da amostra.
- Mediana: Valor que está no centro da sua amostra, metade dos valores está acima deste número e metade abaixo. Na cidade A a mediana é 200 e na cidade B é 55, pois (10+100)/2 = 55.
- Moda: Valor que aparece mais vezes nos seus dados. Na cidade A a moda é 200 e na cidade B é 10.
- Desvio padrão: Mede o quanto seus dados variam com relação a média.
- Variância: Essa medida vai te dar a dispersão dos seus dados com relação a média, mas em uma dimensão que será o quadrado da dimensão dos seus dados.
- Curtose: Também é uma medida para indicar a dispersão dos seus dados, mas nesse caso, a estatística nos dará o quão achatado é o gráfico da função de probabilidade dos nossos dados. Falaremos mais dessa medida em um post futuro, por enquanto, ficamos com a definição mais básica de que uma Curtose próxima de zero indica uma distribuição normal.
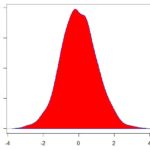
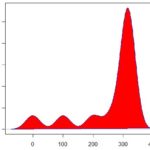
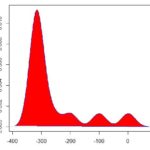
- Assimetria: Nos dá a simetria da distribuição dos nossos dados. Como assim? Bem, se você desenhar a curva de distribuição dos seus dados, você pode ter algo parecido com uma normal, uma curva um pouco mais concentrada a direita e caindo quando vai para a esquerda, ou o contrário. É isso que a essa medida do excel nos ajuda a entender. Uma distribuição simétrica, que tem o formato de um sino, terá assimetria igual a 0. No entanto, se a distribuição possuir uma maior concentração de dados a esquerda, o valor dessa estatística será negativo.