Este post é um complemento ao Teorema de Bayes na prática: interpretando falso positivo e Probabilidade Condicional e o Teorema de Bayes. Apresento aqui uma demonstração visual de algumas medidas muito utilizadas na estatística.
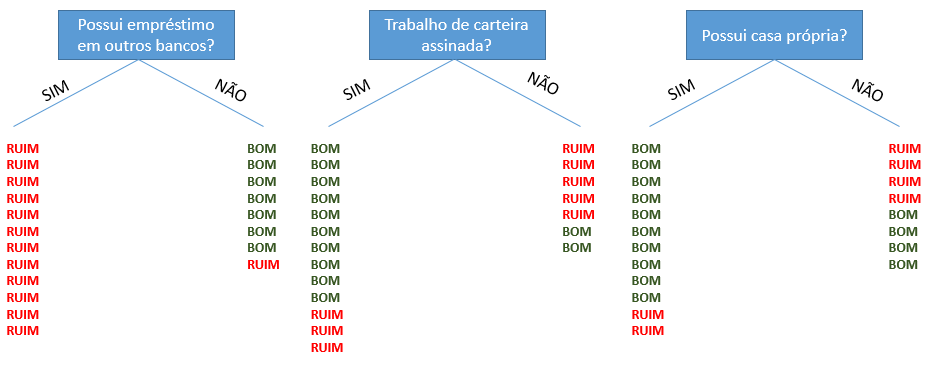
Dado um experimento em que queremos verificar se um exame é capaz de diagnosticar uma doença, temos os seguintes resultados possíveis:

- True Positive (TP) ~ Verdadeiro Positivo: O paciente foi diagnosticado como portador da doença e ele realmente é portador dela;
- False Positive (FP) ~ Falso Positivo: O paciente foi diagnosticado como portador da doença, porém, ele não é portador dela;
- False Negative (FN) ~ Falso Negativo: O paciente foi diagnosticado como não sendo portador da doença, porém, ele é portador dela;
- True Negative (TN) ~ Verdadeiro Negativo: O paciente foi diagnosticado como não sendo portador da doença, e ele realmente não é portador dela.
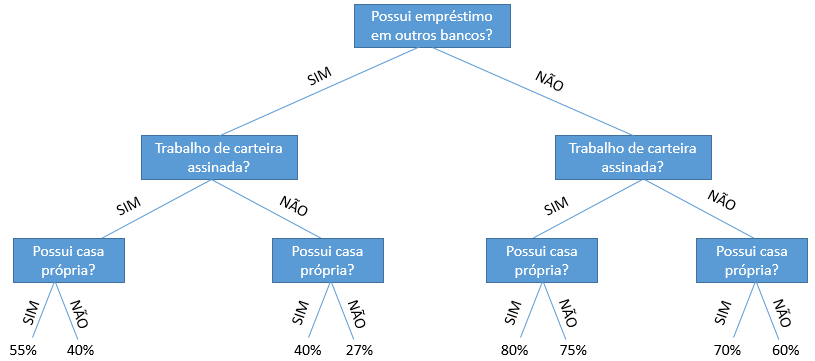
A partir deste quadro, temos as seguintes medidas:
- Sensibilidade: Probabilidade do exame ser positivo, dado que o paciente é portador da doença. Ou seja, capacidade do exame de acertar o diagnóstico de um paciente portador da doença;
- Especificidade: Probabilidade do exame ser negativo, dado que o paciente não é portador da doença. Ou seja, capacidade do exame de acertar o diagnóstico de um paciente saudável;
- Acurácia: Probabilidade do diagnóstico do exame estar correto.
Colocando em fórmulas matemáticas:
- Sensibilidade = TP / (TP+FN)
- Especificidade = TN / (FP+TN)
- Acurácia = (TP+TN) / (TP+FN+FP+TN)
Veja que estamos falando de exames e doenças, mas essas medidas são utilizadas de diversas formas. Por exemplo, se você fizer uma regressão logística para prever inadimplência, você pode calcular a sensibilidade do seu modelo, qual a probabilidade de identificar um mau pagador, dado que o indivíduo é realmente mau pagador.