Suponha que você tenha uma tabela analítica com as informações de compras dos seus clientes. Cada linha da tabela equivale a uma compra diferente que o cliente fez. O que você quer é saber o valor médio das compras de cada cliente. Como você conseguiria fazer isso no R? Continuar a ler “Equivalente ao Proc Sql Group By no R”
Etiqueta: proc sql
Contar linhas no R e SAS/SQL
Uma rapidinha para te ajudar a entender as bases analisadas…
Quando contamos as linhas no PROC SQL do SAS, podemos utilizar: Continuar a ler “Contar linhas no R e SAS/SQL”
Tutorial: Proc Sql (SAS)
Como já disse algumas vezes aqui, o SQL é uma linguagem própria para trabalhar com bases de dados. Logo, é de se esperar que alguns softwares utilizem funções semelhantes, ou até iguais, a ela. Isso porque (i) muitas pessoas que utilizam base de dados já estão acostumadas com o SQL, e (ii) é muito mais fácil se basear nessas funções já existentes do que ficar tentando criar algo novo mirabolante. O SAS, assim como outros softwares estatísticos Continuar a ler “Tutorial: Proc Sql (SAS)”
SAS: Representatividade de cada linha e Soma Cumulativa
Recentemente me pediram ajuda com o SAS, para que fosse possível colocar, para determinada coluna, o quanto cada linha representava (%) da soma total dessa coluna. Na sequência, seria preciso colocar a soma cumulada desses percentuais. Continuar a ler “SAS: Representatividade de cada linha e Soma Cumulativa”
Introdução ao SQL
SQL (Structured Query Language) é a linguagem padrão utilizada para armazenar, manipular e recuperar informações de bancos de dados. Colocando de forma simples, é através do SQL que é possível criar e atualizar nossos dados através de um modelo relacional. Os maiores usuários da linguagem são os DBAs (Database Administrators), responsáveis por toda a gestão dos dados, desde criar tabelas até dar acesso às demais áreas (para os mais curiosos há um podcast brasileiro com foco nos DBAs chamado DatabaseCast).
Charada de SQL
Esse é um tipo de “pegadinha” comum em entrevistas e que mesmo no dia a dia confunde algumas pessoas na hora de tratar os dados. Seja para surpreender o entrevistador ou para resolver rápido os problemas, você precisa ter a resposta na ponta da língua.
Conversão texto para número no data step e proc sql
O jeito mais simples de converter de texto para número no data step é simplesmente multiplicar a coluna por 1:
SQL dentro do SAS
O SQL é uma linguagem utilizada comumente na manipulação de dados. É bastante intuitiva e fácil de utilizar. Para selecionar, por exemplo, uma coluna denominada Nome contendo os nomes de clientes da tabela XYZ, o comando a ser utilizado é praticamente a frase “selecionar nome da tabela XYZ”, mas em inglês:
SELECT Nome from tabela XYZ
Ou então, você pode selecionar todas as colunas da base XYZ com o comando ‘*’:
SELECT * from tabela XYZ
Como você pode ver, é bem intuitivo.
O SQL é uma das linguagens embutidas no SAS e você pode acioná-la utilizando o comando proc sql seguido pelo tradicional ponto e vírgula e finalizá-lo com o comando run do SAS. Para você ver como pouco muda, o comando de SQL utilizado acima ficaria da seguinte forma no SAS:
proc sql; select * from tabela XYZ; run;
Caso você já acompanhe o blog, ou tenha lido alguns outros códigos, você deve ver muitas vezes ao invés do asterisco sozinho, algo como a.*. Isso ocorre porque quando temos duas tabelas, nós as denominamos de ‘a ‘e ‘b’ (ou t1, t2, etc.), sendo assim você precisa mencionar de qual tabela você está selecionando a coluna. O código acima, caso quiséssemos chamar a tabela XYZ de ‘a‘, ficaria da seguinte forma:
proc sql; select a.* from tabela XYZ as a; run;
Veja que para uma tabela só não tem muita diferença, mas imagine com duas ou três como já complicaria escrever simplesmente select Nome. Se o SAS pudesse falar, ele diria: seleciono de onde? De XYZ ou das outras tabelas?
Veja que a linguagem de SQL embutida no SAS facilita bastante a manipulação dos dados e fornece aos usuários alternativas quando a lógica com o data step for mais complicada.
Como o código acima vai apenas mostrar para você a seleção feita, para utilizarmos a informação gerada dentro do próprio SAS podemos criar uma tabela. E, novamente, o código é uma mera tradução do inglês: Create Table:
proc sql; create table Tabela_Nomes as select Nome from tabela XYZ; run;
Vamos utilizar a tabela abaixo com algumas pessoas, a renda que elas possuem e a origem dessa renda, para demonstrar outros comandos utilizados no proc sql:

Os principais comandos a serem lembrados no SQL, além do select, são:
- Where: Um tipo de filtro, semelhante ao if. Vamos supor que a base contenha a coluna renda com o salário dos clientes e você queira apenas o nome de quem possui renda superior a mil reais. Agora, você terá que selecionar duas colunas, Nome e Renda, e a tabela com esses clientes seria criada da seguinte forma:
proc sql; create table Tabela_Renda as select id, Nome, Renda from tabela_exemplo where renda > 1000; run;

- Group by: Serve para agrupar os dados por algum campo em comum. Vamos pensar agora nos clientes que possuem várias fontes de renda, aquela pessoa que além do salário da empresa também possui rendas com aluguéis ou trabalhos de freelancer. Sendo assim, a base terá várias linhas com rendas diferentes para esse cliente. Se você quiser a renda total dele, você terá que somar essas rendas diferentes e agrupar pelo nome:
proc sql; create table Tabela_Renda_Cliente as select id, Nome, sum(Renda) as Renda_Total from tabela_exemplo group by id, nome having Renda_Total > 1000; run;

- Having : Bem semelhante ao where, é utilizado para o filtro depois de alguma tratativa. Como queríamos selecionar os clientes com renda acima de mil reais, e com o where só considerávamos a renda de um emprego, agora podemos filtrar os clientes com renda total acima de mil reais utilizando o having:
proc sql; create table Tabela_Renda_Cliente_2 as select id, Nome, sum(Renda) as Renda_Total from tabela_exemplo group by id, nome having Renda_Total > 1000; run;

Order By: Ordena a tabela de acordo com algum campo, na ordem crescente.
Poderíamos ter gerado a renda dos clientes, mas ordenando pela renda:
proc sql; create table Tabela_Renda_Cliente_3 as select id, Nome, sum(Renda) as Renda_Total from tabela_exemplo group by id, nome having Renda_Total > 1000 order by Renda_Total; Run;

Combinando três tabelas com o left join
Utilizando as informações do post Como combinar tabelas no SAS utilizando left join e full join, vamos imaginar que não tenhamos apenas duas tabelas, mas sim três, sendo que a terceira tabela contém as notas dos alunos que cursam Física:
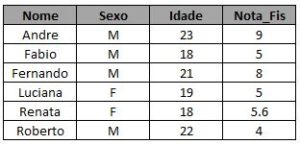
Para montar uma única query que traga a nota de física, basta continuar o left join:
* notas dos alunos de calculo incluindo as de fisica dos que fizeram;
proc sql;
create table exemplo_left_join as
select a.*, b.nota_estat, c.nota_fis
from turma_calc as a
left join (select * from turma_estat ) as b
on a.nome = b.nome
left join (select * from turma_fis) as c
on a.nome= c.nome;
run;
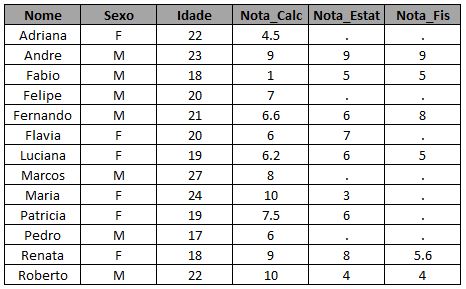
E você poderia inclusive filtrar antes de aplicar o left join. Como?
Bem, para quem leu o post SQL dentro do SAS sobre SQL fica bem claro o que foi feito acima: foi aplicado um left join em uma base construída entre parênteses. Ou seja, se para extrair as informações da turma de Física usamos select * from turma_fis, pra extrair os alunos aprovados na disciplina bastaria utilizar select * from turma_fis where Nota_Fis >= 6, teríamos então:
* excluindo os alunos reprovados em fisica;
proc sql;
create table exemplo_left_join_2 as
select a.*, b.nota_estat, c.nota_fis
from turma_calc as a
left join (select * from turma_estat ) as b
on a.nome = b.nome
left join (select * from turma_fis where Nota_Fis >= 6) as c
on a.nome= c.nome;
run;
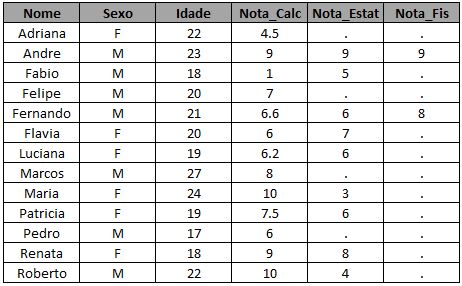
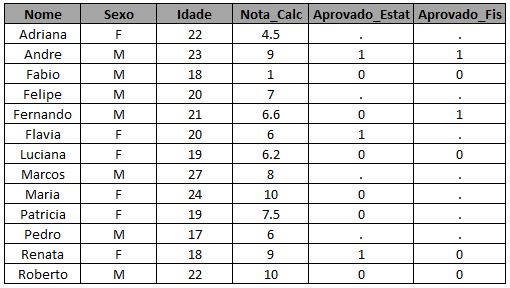
Agora que você sabe extrair informações utilizando o SQL e sabe que você pode fazer o que quiser dentro do parênteses antes de aplicar o left join, você poderia inclusive ser mais ousado e criar uma marcação de alunos aprovados, onde o campo Aprovado receberia 1 quando o aluno tem nota superior ou igual a 6 e 0 caso contrário:
* cria uma flag = 1 para trazer quem foi aprovado em fisica e estatistica;
proc sql;
create table exemplo_left_join_3 as
select a.*, b.Aprovado_Estat, c.Aprovado_Fis
from turma_calc as a
left join (
select *, case when Nota_Estat >= 6 then 1
else 0 end as Aprovado_Estat from turma_estat ) as b
on a.nome = b.nome
left join (
select *, case when Nota_Fis >= 6 then 1
else 0 end as Aprovado_Fis from turma_fis) as c
on a.nome= c.nome;
run;
Como combinar tabelas no SAS utilizando left join e full join
Provavelmente a tarefa mais comum de alguém que trabalha com dados seja combinar diferentes tabelas para se obter toda a informação que precisa. Por exemplo, se em uma tabela você tiver o nome dos seus clientes e a informação de idade em uma base de dados, e em uma segunda tabela tiver informações como endereço e sexo, é bem provável que ao fazer um estudo, um modelo estatístico, você tenha que combinar estas duas tabelas. Vamos ver agora como combinar duas tabelas de algumas formas diferentes.
Vamos utilizar como exemplo duas turmas da faculdade, uma do curso de Cálculo e outra do curso de Estatística.Podemos ter alguns alunos matriculados em uma delas e não matriculados na outra e vice-versa. As duas tabelas abaixo contêm os alunos de cada turma, o sexo, a idade e a nota final da disciplina:

 Caso alguém ainda não saiba criar sua própria tabela para treinar, segue o código utilizado para gerar as que serão utilizadas aqui:
Caso alguém ainda não saiba criar sua própria tabela para treinar, segue o código utilizado para gerar as que serão utilizadas aqui:
data turma_calc; length nome $22.; input Nome $ Sexo $ Idade Nota_Calc; datalines; Roberto M 22 10 Maria F 24 10 Pedro M 17 6 Renata F 18 9 Andre M 23 9 Marcos M 27 8 Patricia F 19 7.5 Luciana F 19 6.2 Adriana F 22 4.5 Fernando M 21 6.6 Felipe M 20 7 Flavia F 20 6 Fabio M 18 1 ; run; data turma_estat; length nome $22.; input Nome $ Sexo $ Idade Nota_Estat; datalines; Roberto M 22 4 Maria F 24 3 Jose M 19 6 Renata F 18 8 Andre M 23 9 Alexandre M 17 8 Patricia F 19 6 Luciana F 15 6 Fernanda F 29 5 Fernando M 21 6 Marcelo M 17 5 Flavia F 20 7 Fabio M 18 5 ; run;
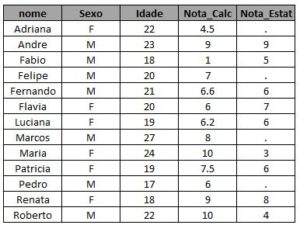
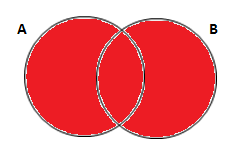
Vamos supor que você queira completar a primeira tabela com as notas de estatística para os alunos que cursaram as duas matérias, mas quer manter os demais também na tabela. Ou seja, pensando em dois conjuntos, você quer adicionar a informação que está na intersecção dos conjuntos A e B à informação do conjunto A. Abaixo temos a representação desse caso em um Diagrama de Venn seguido pelo código em SAS e a tabela de saída deste código:

* traz as notas de estatisticas para a tabela com os alunos de calculo; proc sql; create table exemplo_1 as select a.*, b.* from turma_calc as a left join turma_estat as b on a.nome = b.nome; run;
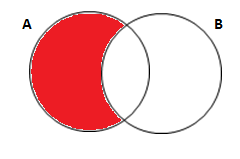
E se você quiser apenas os alunos que cursaram somente cálculo, excluindo quem cursou a outra disciplina:
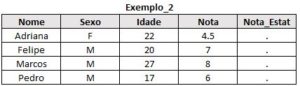
* traz os alunos que cursaram apenas Calculo; proc sql; create table exemplo_2 as select a.*, b.* from turma_calc as a left join turma_estat as b on a.nome = b.nome where b.nome is NULL; run;
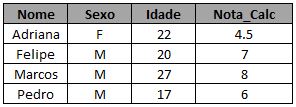
Caso você não quisesse essa última coluna, bastaria não ter selecionado nada da tabela b:
proc sql; create table exemplo_2b as select a.* from turma_calc as a left join turma_estat as b on a.nome = b.nome where b.nome is NULL; run;
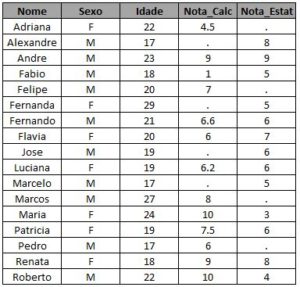
Se quiser trazer os alunos das duas turmas:
* traz todos os alunos das duas turmas; proc sql; create table exemplo_3 as select coalesce (a.nome, b.nome) as Nome , coalesce (a.sexo, b.sexo) as Sexo , coalesce(a.idade, b.idade) as Idade , a.* , b.* from turma_calc as a full join turma_estat as b on a.nome = b.nome; run;
Se você não quiser os alunos que cursaram as duas matérias, quiser apenas quem cursou uma:
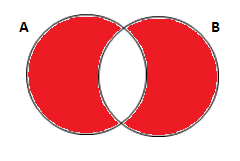
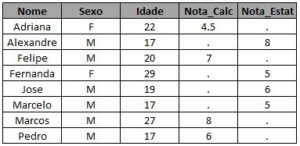
* traz os alunos que cursam somente um dos dois cursos; proc sql; create table exemplo_4 as select coalesce (a.nome, b.nome) as Nome , coalesce(a.sexo, b.sexo) as Sexo , coalesce(a.idade, b.idade) as Idade , a.* , b.* from turma_1 as a full join turma_2 as b on a.nome = b.nome where a.nome is NULL or b.nome is NULL; run;
Se você já programou em sas ou sql, também já ouviu falar do right join, que muda muito pouco com relação ao left join. Como o próprio nome implica, você vai inverter a ordem das tabelas que serão unidas. Veja abaixo uma imagem completa que descreve todas as funções join do sql:
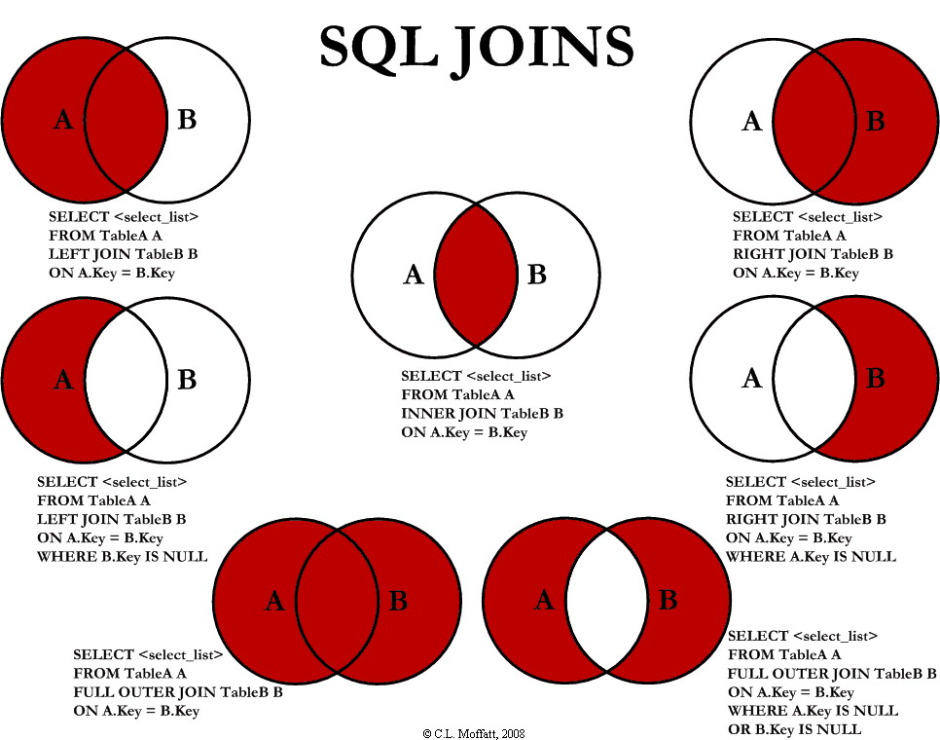
Imagem retirada do site Guia DBA
E aí? Gostou do conteúdo? Agora, imagine estudar análise e ciência de dados com trilhas estruturadas e projetos práticos, com direcionamento claro do que aprender e em que ordem. No nosso Clube de Assinaturas, você encontra desde o essencial para entrar na área de dados, até temas que diferenciam profissionais mais seniores no mercado, como inferência causal, engenharia de software e álgebra linear aplicada a ML.
Conheça: www.universidadedosdados.com