O SQL é uma linguagem utilizada comumente na manipulação de dados. É bastante intuitiva e fácil de utilizar. Para selecionar, por exemplo, uma coluna denominada Nome contendo os nomes de clientes da tabela XYZ, o comando a ser utilizado é praticamente a frase “selecionar nome da tabela XYZ”, mas em inglês:
SELECT Nome from tabela XYZ
Ou então, você pode selecionar todas as colunas da base XYZ com o comando ‘*’:
SELECT * from tabela XYZ
Como você pode ver, é bem intuitivo.
O SQL é uma das linguagens embutidas no SAS e você pode acioná-la utilizando o comando proc sql seguido pelo tradicional ponto e vírgula e finalizá-lo com o comando run do SAS. Para você ver como pouco muda, o comando de SQL utilizado acima ficaria da seguinte forma no SAS:
proc sql; select * from tabela XYZ; run;
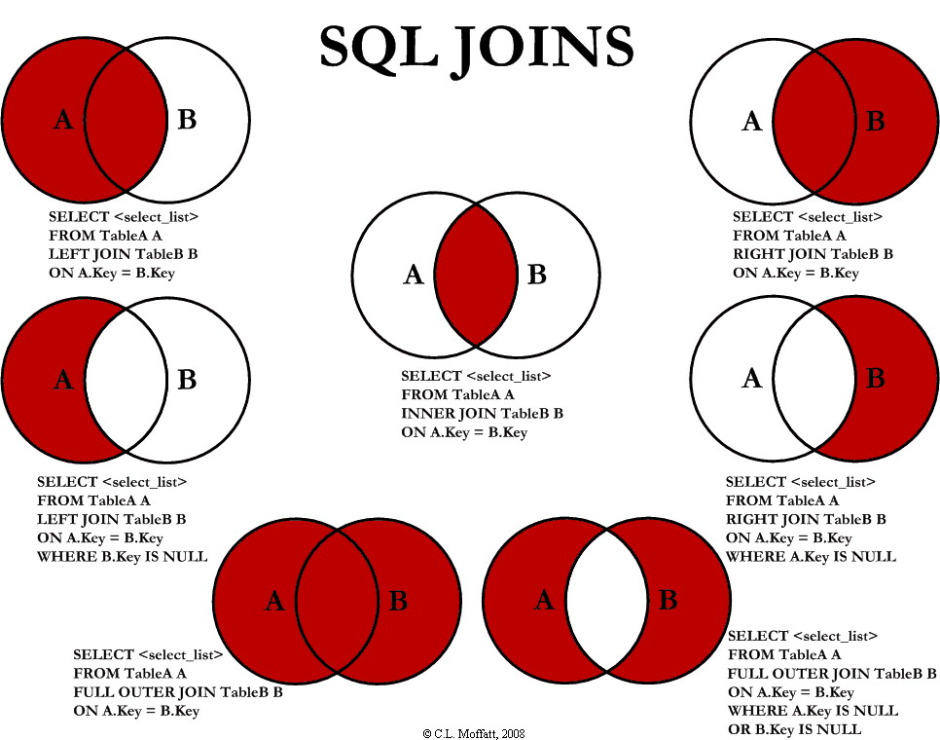
Caso você já acompanhe o blog, ou tenha lido alguns outros códigos, você deve ver muitas vezes ao invés do asterisco sozinho, algo como a.*. Isso ocorre porque quando temos duas tabelas, nós as denominamos de ‘a ‘e ‘b’ (ou t1, t2, etc.), sendo assim você precisa mencionar de qual tabela você está selecionando a coluna. O código acima, caso quiséssemos chamar a tabela XYZ de ‘a‘, ficaria da seguinte forma:
proc sql; select a.* from tabela XYZ as a; run;
Veja que para uma tabela só não tem muita diferença, mas imagine com duas ou três como já complicaria escrever simplesmente select Nome. Se o SAS pudesse falar, ele diria: seleciono de onde? De XYZ ou das outras tabelas?
Veja que a linguagem de SQL embutida no SAS facilita bastante a manipulação dos dados e fornece aos usuários alternativas quando a lógica com o data step for mais complicada.
Como o código acima vai apenas mostrar para você a seleção feita, para utilizarmos a informação gerada dentro do próprio SAS podemos criar uma tabela. E, novamente, o código é uma mera tradução do inglês: Create Table:
proc sql; create table Tabela_Nomes as select Nome from tabela XYZ; run;
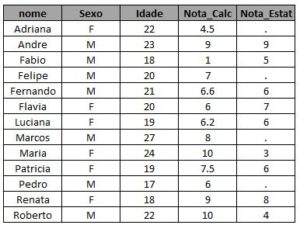
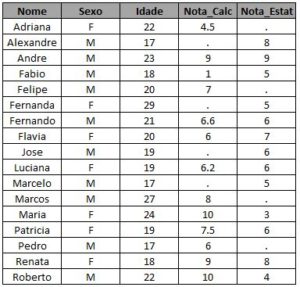
Vamos utilizar a tabela abaixo com algumas pessoas, a renda que elas possuem e a origem dessa renda, para demonstrar outros comandos utilizados no proc sql:

Os principais comandos a serem lembrados no SQL, além do select, são:
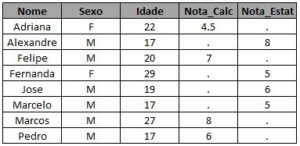
- Where: Um tipo de filtro, semelhante ao if. Vamos supor que a base contenha a coluna renda com o salário dos clientes e você queira apenas o nome de quem possui renda superior a mil reais. Agora, você terá que selecionar duas colunas, Nome e Renda, e a tabela com esses clientes seria criada da seguinte forma:
proc sql; create table Tabela_Renda as select id, Nome, Renda from tabela_exemplo where renda > 1000; run;

- Group by: Serve para agrupar os dados por algum campo em comum. Vamos pensar agora nos clientes que possuem várias fontes de renda, aquela pessoa que além do salário da empresa também possui rendas com aluguéis ou trabalhos de freelancer. Sendo assim, a base terá várias linhas com rendas diferentes para esse cliente. Se você quiser a renda total dele, você terá que somar essas rendas diferentes e agrupar pelo nome:
proc sql; create table Tabela_Renda_Cliente as select id, Nome, sum(Renda) as Renda_Total from tabela_exemplo group by id, nome having Renda_Total > 1000; run;

- Having : Bem semelhante ao where, é utilizado para o filtro depois de alguma tratativa. Como queríamos selecionar os clientes com renda acima de mil reais, e com o where só considerávamos a renda de um emprego, agora podemos filtrar os clientes com renda total acima de mil reais utilizando o having:
proc sql; create table Tabela_Renda_Cliente_2 as select id, Nome, sum(Renda) as Renda_Total from tabela_exemplo group by id, nome having Renda_Total > 1000; run;

Order By: Ordena a tabela de acordo com algum campo, na ordem crescente.
Poderíamos ter gerado a renda dos clientes, mas ordenando pela renda:
proc sql; create table Tabela_Renda_Cliente_3 as select id, Nome, sum(Renda) as Renda_Total from tabela_exemplo group by id, nome having Renda_Total > 1000 order by Renda_Total; Run;


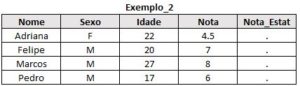
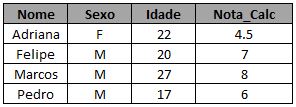
 Caso alguém ainda não saiba criar sua própria tabela para treinar, segue o código utilizado para gerar as que serão utilizadas aqui:
Caso alguém ainda não saiba criar sua própria tabela para treinar, segue o código utilizado para gerar as que serão utilizadas aqui: