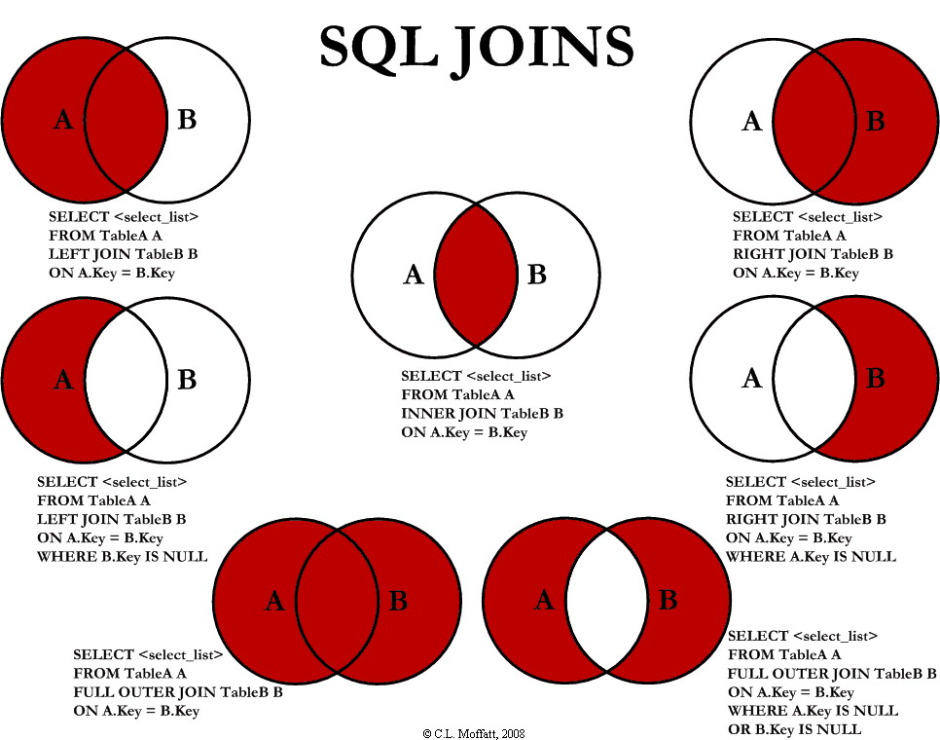
No post As boas práticas de programação foi mencionado que o código deveria ser o menos estático possível? No SAS isso pode ser feito muito bem com a criação de Macros e com a expressão %LET.
CONCEITO DE MACROS
De acordo com o Wikipedia “Uma macro (abreviação para macroinstrução), em ciência da computação, é uma regra ou padrão que especifica como uma certa sequência de entrada (frequentemente uma sequência de caracteres) deve ser mapeada para uma substituição de sequência de saída (também frequentemente uma sequência de caracteres) de acordo com um procedimento definido.”
Ou seja, uma macroinstrução é uma sequência de regras que o programa deve seguir. Quando você cria uma macro, você cria um programinha que vai executar uma série de procedimentos.
MACROS NO SAS
No SAS, assim como em outros programas, você pode deixar uma série de nomes flexíveis dentro da sua sequência de procedimentos, para que eles rodem diversas vezes soltando saídas diferentes.
Por exemplo, suponha que a gente tenha a base FATURA_YYYYMM gerada mensalmente com as faturas dos clientes no mês corrente. Você está realizando um estudo com clientes que possuem faturas de valor acima de R$ 200,00. Porém, para seu estudo, você vai pegar clientes dos primeiros três meses do ano. Se a pessoa não conhece muito sobre macros, é esperado que ela faça um código como esse:
data faturas_jan;
set fatura_201601;
if vlr_fatura > 200;
run;
data faturas_fev;
set fatura_201602;
if vlr_fatura > 200;
run;
data faturas_mar;
set fatura_201603;
if vlr_fatura > 200;
run;
Não parece a melhor maneira. Alguém mais calejado já estaria quebrando a cabeça imaginando que existe um jeito mais prático. Existe, é utilizando as macros do SAS.
No começo parece até algo mais complicado, mas é bem simples. A sintaxe é da seguinte forma:
%macro nome_da_macro(input 1, input2, ...);
comando 1;
comando 2;
.
.
.
%mend;
%nomedamacro(input 1, input2, ...);
Sendo assim, podemos criar a macro EXTRAI_FATURA na qual vamos colocar como inputs os nomes das bases que serão lidas e como output as bases de saída:
%macro extrai_fatura(input, output);
data &input;
set &output;
if fatura > 200;
run;
%mend;
%extrai_fatura(fatura_201601, extracao_janeiro);
%extrai_fatura(fatura_201602, extracao_fevereiro);
%extrai_fatura(fatura_201603, extracao_marco);
Veja que a macro está lendo as bases que declaramos como input e está soltando os resultados em bases com o nome que passamos como output (extracao + nome do mês).
Note que precisamos colocar o caractere ‘&’ antes do nome das variáveis que serão substituídas. Note também, que a macro pode ficar ainda mais flexível com você passando o valor que quiser em cada extração:
%macro extrai_fatura(input, output, valor);
data &input;
set &output;
if fatura > &valor;
run;
%mend;
%extrai_fatura(fatura_201601, extracao_janeiro, 100);
%extrai_fatura(fatura_201602, extracao_fevereiro, 200);
%extrai_fatura(fatura_201603, extracao_marco, 300);
Nessa segunda macro, podemos colocar o valor que quisermos em cada extração. A primeira execução vai ler a fatura_201601 e retornar a extracao_janeiro apenas com clientes que possuem fatura acima de R$ 100,00. A segunda execução lê a fatura_201602 e retorna a extracao_fevereiro apenas com os clientes de fatura acima de R$ 200,00.
%LET NO SAS
A expressão %LET é mais fácil ainda que a macro, embora não ache ela tão poderosa.
Essa expressão também serve para alterar parâmetros no meio do seu código, porém, diferentemente da macro, você declara a variável uma vez no início do código. Uma das facilidades que eu vejo no LET é que permite você rodar o código por partes, o que facilita bastante para pegar erros. Facilita para processos executados periodicamente em que se altera algumas variáveis de inputs. Vamos supor que agora você não vai fazer um estudo, mas você quer fazer uma campanha com os clientes de alta renda e todo mês, assim que a base de faturamento for gerada, você vai pegar os clientes que possuem faturas acima de R$ 500,00. Você faria o seguinte código no mês de janeiro:
%let base_fatura = fatura_201601;
data extracao_campanha;
set &base_fatura;
if fatura > 500;
run;
Novamente, a gente declara uma variável e insere ela no código com o comando ‘&’ seguido do nome do input. No mês seguinte, você precisaria apenas trocar o valor atribuído ao %let e executar o mesmo código:
%let base_fatura = fatura_201602;
data extracao_campanha;
set &base_fatura;
if fatura > 500;
run;
Pense agora na quantidade de possibilidades. Deixar o valor da fatura, o nome da base de saída e outras variáveis flexíveis também. Pense agora se você tivesse 50 condições ao invés dessa única. Facilitaria bastante, não?
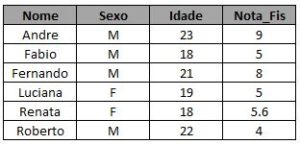
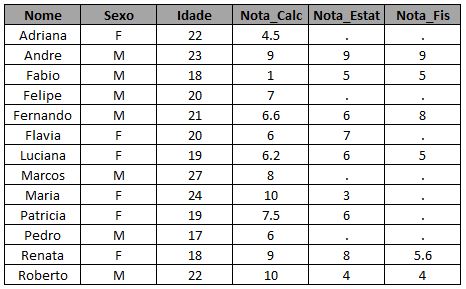

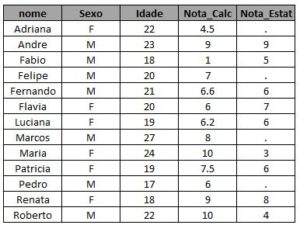
 Caso alguém ainda não saiba criar sua própria tabela para treinar, segue o código utilizado para gerar as que serão utilizadas aqui:
Caso alguém ainda não saiba criar sua própria tabela para treinar, segue o código utilizado para gerar as que serão utilizadas aqui: