No post Como combinar tabelas no SAS utilizando left join e full join ensinei como unir tabelas no SAS, utilizando o PROC SQL. Agora, como podemos fazer essa união no R? Como utilizar os clássicos inner join, left join, right join, etc., no R? É bem simples, você vai ver que consegue fazer tudo isso com menos linhas que no SQL.Para que não haja confusão a respeito do que faz cada join, coloco aqui mais uma vez uma figura retirada do site Guia DBA:
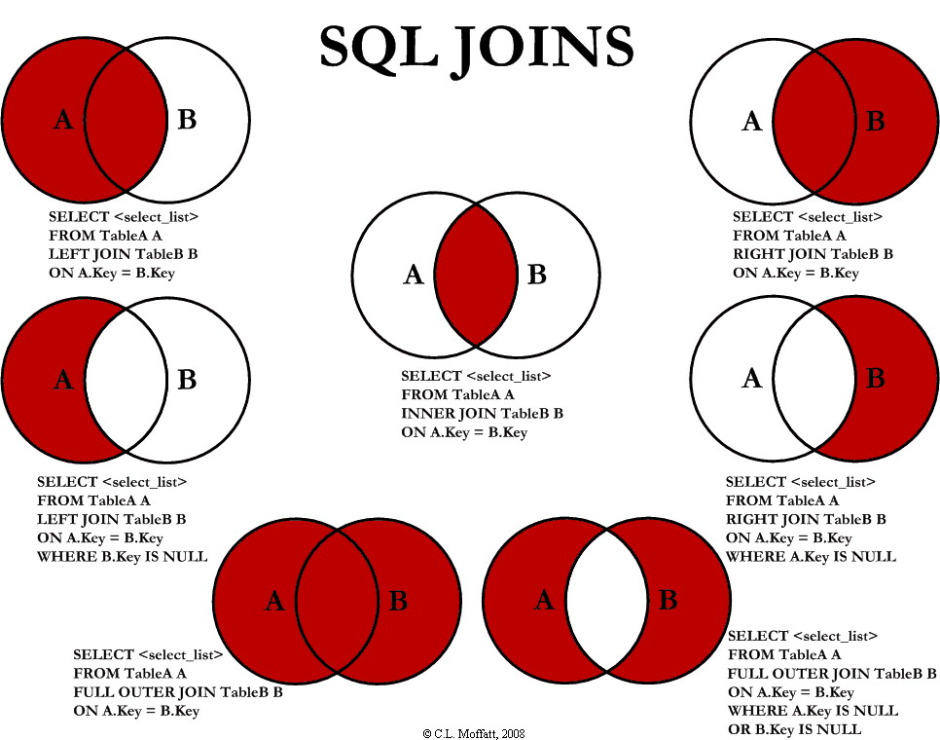
Agora, vamos construir duas tabelas para serem utilizadas como exemplo. Em uma dessas tabelas, temos as informações de cadastro dos clientes: o campo chave de identificação (id), a cidade em que reside o indivíduo e o sexo. Já na outra tabela, temos o valor da compra e o nome da loja na qual a compra foi feita.
id = c("AA111","BB222","CC333","DD444");
uf = c("SP", "MG", "MT","BA");
sexo = c("F","F","M","M");
tabela_A = data.frame(id, uf, sexo);
id = c("BB222","AA111","CC333","EE555");
vlr_compra = c(100, 95, 150,100);
loja = c("XYZ", "BAB", "AAA","BDC");
tabela_B = data.frame(id, vlr_compra, loja);

 INNER JOIN
INNER JOIN
inner_join = merge(tabela_A, tabela_B, by="id");
 OUTER JOIN
OUTER JOIN
outer_join = merge(tabela_A, tabela_B, by = "id", all = TRUE);
 LEFT OUTER JOIN
LEFT OUTER JOIN
left_outer_join = merge(tabela_A, tabela_B, by = "id", all.x = TRUE);
 RIGHT OUTER JOIN
RIGHT OUTER JOIN
right_outer_join = merge(tabela_A, tabela_B, by = "id", all.y = TRUE);

Ok, mas e se eu quiser unir através de duas (ou mais) variáveis?
Neste caso, a lógica é a mesma, você deve utilizar a mesma estrutura, porém, deve indicar duas variáveis no argumento ‘by =’.Lembre-se que quando queremos inserir um vetor de elementos no R, precisamos utilizar a seguinte estrutura c(elemento_1, elemento_2, …, elemento_n). Supondo que nossas tabelas tivessem o nome e quiséssemos combinar o join pelo id e nome, teríamos a seguinte função:
join_duas_colunas = merge(tabela_A, tabela_B, by c(“id”,"nome"));
Bom, praticamente tudo explicado. Talvez a dúvida que possa surgir seja para o caso de termos nomes de coluna diferentes. Poderíamos ter, por exemplo, uma tabela com o campo chave nomeado de id (como no nosso exemplo – e uma outra com o campo chave nomeado de identificacao. Para que o nosso join funcione, precisamos especificar qual o nome de cada variável no by:
join_nomes_diferentes = merge(tabela_A, tabela_B, by.x=c(“id”),by.y=c(“identificacao”));
Note que é possível fazer outros tipos de join ao mudar as colunas de posição. Fica de lição de casa praticar as diferentes formas de juntar as colunas.
Se tiver alguma dúvida, crítica ou sugestão, deixe um comentário neste post ou entre em contato comigo através do formulário que está em Sobre o EstatSite. Não se esqueça de seguir a minha nova conta de Twitter dedicada aos posts de Data Science: @EstatSite.
Bons estudos!