Recentemente, fiz um dos projetos disponíveis na plataforma do Datacamp – tenho uma assinatura anual que fiz no início da pandemia. A ideia era criar um modelo que classificasse o estilo musical com base em algumas características da música. Este post é dedicado a explicar um pouco do código e dar uma base com outros posts para que você consiga acompanhar o conteúdo dele. Enfim, bora aprender um modelo legal de classificação de estilo musical em Python!
INTRODUÇÃO
Primeiro, baixe os datasets que serão utilizados no projeto. Eles podem ser encontrados aqui e aqui. Note que temos dados estruturados e um problema de aprendizado supervisionado. I.e, os dados possuem rótulos – sabemos qual música é hip-hop e qual é rock, e queremos fazer um modelo que consiga prever com dados novos qual estilo da música.
O notebook completoque fiz com a resolução é autoexplicativo e está neste link aqui. Caso não veja necessidade das instruções neste post, você pode ir direto ao notebook.
Iniciamos a resolução importando os dados:
# Importa as bibliotecas
import pandas as pd
# lê o dataset com as musicas
tracks = pd.read_csv('fma-rock-vs-hiphop.csv')
# lê o dataset com as características de cada estilo
echonest_metrics = pd.read_json('echonest-metrics.json',precise_float=True)
# une os dois datasets
echo_tracks = pd.merge(echonest_metrics,
tracks[['track_id','genre_top']],
on='track_id')
# verifica como ficou o dataset resultante da união
echo_tracks.head()
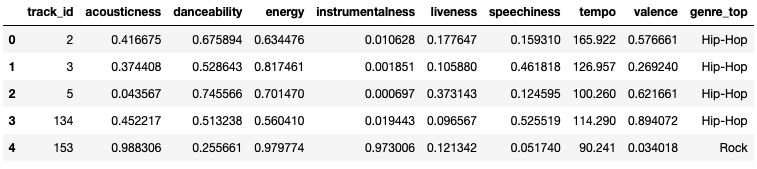
DIVISÃO DE TESTE E TREINO
Agora, temos um dataset preparado para rodar qualquer modelo das principais bibliotecas em Python. Porém, antes de rodar o modelo, precisamos separar os dados em TREINO e TESTE. Isso porque queremos construir o modelo com uma parte dos nossos dados e testá-lo em outra parte. Isso é algo feito de praxe para se evitar o overfitting – que você pode aprender lendo os posts Overfitting e Cross Validation e Explicando overfitting com uma anedota.
ATENÇÃO: Esta outra parte, chamada de treino, é uma simulação do mundo real. Sendo assim, seriam dados novos, que não utilizamos no modelo. Por esse motivo, TODO pré-processamento deve ser feito após a divisão em treino e teste. Quer preencher os valores nulos? Depois da divisão. Quer aplicar um PCA? Depois da divisão. Veja mais sobre o assunto no post Data Leakage, o erro que até os grandes cometem.
Enfim, vamos ao código:
# variáveis utilizaremos para fazer a predição features = echo_tracks.drop(columns=['genre_top', 'track_id'], axis=1) # variável que queremos prever labels = echo_tracks['genre_top'] # divisão em treino e teste from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.3, random_state=0)
PIPELINES E RANDOM FOREST
Lembra que eu falei que devemos fazer todo pré-processamento depois da divisão? Então, existe um jeito fácil de se evitar isso: utilizar PIPELINES.
Nunca ouviu falar disso? Então veja os posts Introdução aos Pipelines no Scikit-Learn e Pipeline usando Scikit-Learn: Exemplos Práticos. No fim das contas, nada mais é do que reunir diversas etapas do projeto em conjunto, enquanto definimos os parâmetros.
Voltando ao nosso modelo, vamos aplicar um pipeline que imputa missing utilizando o valor da mediana e aplica um StandardScale() – uma forma de padronização -, algo que não é tão necessário para árvores, mas que deixei porque achei legal mostrar a transformação para o pessoal pegar legal como criar um pipeline:
# MODELO COM PIPELINE
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.decomposition import PCA
from sklearn.tree import DecisionTreeClassifier
from sklearn.impute import SimpleImputer
# Criando o Preprocessamento no Pipeline
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, X_train.columns)])
# Pipeline com random forest
from sklearn.ensemble import RandomForestClassifier
rf = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', RandomForestClassifier())])
# treina o modelo
rf.fit(X_train, y_train)
BREVE PARÊNTESES 1: ÁRVORE DE DECISÃO E RANDOM FOREST
Primeiro, é preciso saber que uma Random Forest é um algoritmo que combina diversas árvores de decisão. Sendo assim, você precisa começar entendendo o que é uma árvore de decisão. Abaixo, um exemplo retirado do post Árvore de Decisão (bem mais completo e recomendado):

Agora, você já está apto para entender uma Random Forest, ou, traduzido diretamente, uma Floresta Aleatória. Abaixo, um exemplo que acredito já deixar bem claro como funciona o algoritmo:

BREVE PARÊNTESES 2: FUNCIONAMENTO DA RANDOM FOREST
De forma intuitiva, o algoritmo funciona da seguinte maneira:
- Coletamos uma amostra do dataset original, podendo haver repetições;
- Começamos a construção de uma árvore de decisão a partir do dataset gerado pela amostragem acima;
- Na hora de selecionar qual a feature do primeiro nó (=root node), consideramos um subconjunto das features disponíveis no dataset;
- Na hora de escolher a feature do nó seguinte, também selecionamos a partir de um subconjunto das variáveis que restaram;
- Seguimos fazendo isso até finalizar a árvore;
- Note: o subconjunto de features pode ter tamanho 2, 3, …, n. É preciso escolher o que gera melhor desempenho;
- Pegue o processo e repita centenas de vezes. I.e., construímos centenas de árvores de decisão;
- Como usamos as árvores?
- Pegue o primeiro data point (o primeiro “indivíduo” do nosso conjunto de dados) e rode ele na primeira árvore. Suponha que a gente esteja construindo um modelo para previsão de bom ou mau pagador. A previsão da primeira árvore é que o primeiro indivíduo é um mau pagador. Aí, rodamos para a segunda árvore. Ela também diz que ele será um bom pagador. Repetimos isso para todas árvores. Vemos qual opção recebeu mais votos. Como a maioria das árvores teve como previsão que o indivíduo seria um bom pagador, nossa previsão é que ele será um bom pagador.
Termo importante:
- Ensemble learning: Uso de múltiplos algoritmos para obter melhor desempenho preditivo.
Para uma explicação mais completa, você pode consultar este vídeo (forma intuitiva) ou este material (visão matemática).
RETORNANDO AO PIPELINE
Veja que criamos nosso modelo com os dados de treino. Na sequência, é preciso avaliar sua capacidade de predição em novos dados. Sendo assim, utilizamos os dados de treino. O que faremos é: (I) realizar predições para os dados de teste utilizando a função rf.predict(); (II) verificar a acurácia do modelo (acertos/total); (III) a acurácia pode nos enganar (principalmente para dados desbalanceados), então vamos verificar também outras métricas com o classification report e a matriz de confusão:
# predicoes
y_pred = rf.predict(X_test)
# Acurácia do modelo
from sklearn.metrics import accuracy_score
print("Random Forest Accuracy: \n",accuracy_score(y_test, y_pred))
# Classification report
from sklearn.metrics import classification_report
class_rep_rf = classification_report(y_test, y_pred)
print("Random Forest: \n", class_rep_rf)
# Matriz de Confusao
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_pred)

COMO LIDAR COM DADOS DESBALANCEADOS?
Veja que o modelo foi bem. Entretanto, ele está errando um pouco mais quando tenta predizer o estilo hip-hop. Isso ocorre porque os dados estão desbalanceados, não temos tanta ocorrência de hip-hop quanto temos de rock. Se você parar para refletir, vai ver que isso que está acontecendo aqui é bem comum em outros setores. Em fraude, por exemplo, temos bem menos ocorrência de fraudadores do que de não-fraudadores. Como lidar com isso?
Bom, há várias alternativas aqui. Vamos tratar hoje de CLASS WEIGHT. Quero abordá-la por ser algo simples, que já é parâmetro nos modelos do scikit-learn e que, curiosamente, não aparece nos cursos com tanta frequência – embora existam vários posts falando sobre o tema no Kaggle e Medium.
Bom, como o próprio nome diz, estamos falando de dar pesos a classes diferentes. Imagine que seu modelo trata de fraudadores. Neste caso, a classe 0 é de não-fraudador e a classe 1 é de fraudador. A classe 1 é bem menos presente nos dados, já que temos bem poucos fraudadores. Pode ser que a diferença seja de algo como 100 pra 1. Neste caso, o class weight serve para dar pesos de forma que essa classe ganhe força no treino.
CERTO, MAS COMO IMPLEMENTAR E QUAL PESO ESCOLHER?
A implementação ocorre na forma de parâmetro do modelo e como um dict do Python. Imagine, por exemplo, que você queira dar peso 100 para a classe 1 e peso 1 para a classe 0, você faria algo do tipo:
rf = RandomForestClassifier(class_weight={0:1, 1:100}
Simples assim. Outro truque ótimo é utilizar o parâmetro igual a “balanced”, isso por si só é capaz de resolver alguns problemas:
rf = RandomForestClassifier(class_weight={"balanced"}
Tá, mas e se nada disso der certo?
Bom, então você pode testar outros valores. Vamos voltar ao nosso exemplo de classificar estilo musical. O que eu fiz foi testar diferentes valores para as classes, mas buscando algo próximo da presença delas. A gente tem 4 vezes mais rock do que hip-hop nos nossos dados, então podemos testar algo como hip-hop recebendo peso 4 e rock peso 1. Melhor ainda, e se a gente for testando vários valores entre 2 e 8 para hip-hop, mantendo rock em 1?
Foi o que eu fiz com a seguinte função:
from sklearn.metrics import precision_recall_fscore_support
def trying_class_weight(class_weight):
""" FUNÇÃO PARA TESTAR O RESULTADO DE DIFERENTES PESOS PARA AS CLASSES """
# Criando o Preprocessamento no Pipeline
numeric_transformer = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="median")),
("scaler", StandardScaler()),
]
)
preprocessor = ColumnTransformer(
transformers=[("num", numeric_transformer, X_train.columns)]
)
# Pipeline com random forest
rf = Pipeline(
steps=[
("preprocessor", preprocessor),
("classifier", RandomForestClassifier(class_weight=class_weight)),
]
)
# Fita o modelo
rf.fit(X_train, y_train)
# predicoes
y_pred = rf.predict(X_test)
# Matriz de Confusao
cm = confusion_matrix(y_test, y_pred)
accuracy = (cm[0, 0] + cm[1, 1]) / len(y_test)
precision, recall, fscore, support = score(y_test, y_pred, average="macro")
return accuracy, fscore
Veja que a função testa vários valores e retorna a acurácia e f1-score. Honestamente, não sei se foi a melhor abordagem, então aceito sugestões de mudanças. De qualquer forma, ela resolve o problema.
Bom, agora que a função está criada, eu fiz duas coisas: (1) testei os resultados para “balanced”, None e 1:4; (2) fiz um loop para testar vários valores entre 2 e 8:
# Primeiro, algumas tentativas padrão:
accuracy, fscore = trying_class_weight("balanced")
print("For balanced:")
print(accuracy)
print(fscore)
accuracy, fscore = trying_class_weight(None)
print("For None:")
print(accuracy)
print(fscore)
accuracy, fscore = trying_class_weight({"Hip-Hop": 1, "Rock": 4})
print("For 1:4")
print(accuracy)
print(fscore)
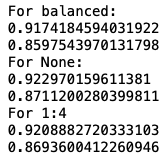
Eu sei que o print ficou meio feião, então você pode corrigir aí com o {.2f}.format(). Ah, e eu esqueci que além do valor numérico e do “balanced”, class_weight também aceita balanced_subsample como parâmetro:
accuracy, fscore = trying_class_weight("balanced_subsample")
print("For balanced subsample:")
print(accuracy)
print(fscore)

Novamente, eu sei que o output está feio e eu até teria vergonha disso, não fosse o fato que eu estou escrevendo este post enorme em minhas férias rs. Então eu acredito que vocês podem relevar essa formatação né?
Agora, a parte (2):
# Vamos testando alguns números entre 2 e 8 para rock (100 tentativas)
weights = []
accuracies = []
f1scores = []
# trying_class_weight é uma função que aplica o peso e ve acuracia e f1-score
for i in np.linspace(2, 8, 100):
accuracy, fscore = trying_class_weight({"Hip-Hop": 1, "Rock": i})
weights.append(i)
accuracies.append(accuracy)
f1scores.append(fscore) # será que dá para criar um dict aqui?
print(max(accuracies))
print(weights[accuracies.index(max(accuracies))])
![]()
Opa, para um peso de 2.5454… parece que a acurácia deu uma melhoradinha legal, quase chegamos em 93%. Vamos ver o reporte completo:
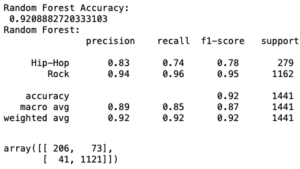
Uai, mas a acurácia mudou?
Sim, lembre-se de como funciona a random forest. Ela vai sortear features para ir treinando em cada árvore. Então toda vez que você rodar, vai ter um resultado diferente. O que o animal aqui tinha que ter feito é ter colocado uma seed nela. Vacilo total!

LOOP ALTERNATIVO
Vasculhando um pouco a internet, encontrei outro loop interessante para testar pesos diferentes para as classes:
# Vamos de tentar isso aqui que achei pela internet e ainda não entendi bem a lógica matemática
weights = []
accuracies = []
f1scores = []
for i in np.linspace(0.0, 1, 100):
accuracy, fscore = trying_class_weight({"Hip-Hop": i, "Rock": 1 - i})
weights.append(i)
accuracies.append(accuracy)
f1scores.append(fscore)
print(max(accuracies))
print(weights[accuracies.index(max(accuracies))]
Este vou deixar somente para fins de curiosidade. Eu não costumo aplicar e, honestamente, não entendi a ideia por trás. Fiquem à vontade para comentar aí o que acharam. Como costumo dizer, estou aqui aprendendo com vocês. Eu vou vendo e jogando aqui!
EXTRA: TESTANDO DIFERENTES MODELOS COM PIPELINE
Um último ponto aqui, veja como o Pipeline é maneiro para testar diferentes abordagens. Abaixo, testamos diversos modelos com os parâmetros default só para ver como o classificador se comporta para diferentes algoritmos:
from sklearn.metrics import accuracy_score, log_loss
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC, LinearSVC, NuSVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import (
RandomForestClassifier,
AdaBoostClassifier,
GradientBoostingClassifier,
)
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
from sklearn.linear_model import LogisticRegression
classifiers = [
KNeighborsClassifier(3),
SVC(kernel="rbf", C=0.025, probability=True),
SVC(),
LogisticRegression(),
DecisionTreeClassifier(),
RandomForestClassifier(),
AdaBoostClassifier(),
GradientBoostingClassifier(),
]
for classifier in classifiers:
pipe = Pipeline(steps=[("preprocessor", preprocessor), ("classifier", classifier)])
pipe.fit(X_train, y_train)
print(classifier)
print("model score: %.3f" % pipe.score(X_test, y_test))
CONSIDERAÇÕES FINAIS
Há outras técnicas de undersampling/oversampling, como SMOTE. Você poderia também usar o random sampling para dar peso a indivíduos do dataset. De qualquer forma, como nosso modelo tem acurácia de ~93% e o f1-score de Hip-Hop chegou a 0.79. Creio que a gente pode considerar essa missão, de criar um classificador para estilo musical, como cumprida. Num futuro próximo, quem sabe, podemos testar essas outras alternativas. Aliás, eu com certeza vou testar. Por isso, acompanhem o blog e o @EstatSite no Twitter para ver como isso irá evoluir.
Se quiser ver mais posts de modelos de machine learning, veja os posts XGBoost em Python, Regressão Logística em Python, Classificador Random Forest em Python e Regressão Linear no Python.
Encontrou algum erro? Pode comentar aí. Eu estou aprendendo, assim como vocês. Cometo erros como todo mundo, zero medo de admitir isso.
E aí? Gostou do conteúdo? Agora, imagine estudar análise e ciência de dados com trilhas estruturadas e projetos práticos, com direcionamento claro do que aprender e em que ordem. No nosso Clube de Assinaturas, você encontra desde o essencial para entrar na área de dados, até temas que diferenciam profissionais mais seniores no mercado, como inferência causal, engenharia de software e álgebra linear aplicada a ML.
Conheça: www.universidadedosdados.com
Bons estudos!
Um comentário em “Modelo de Classificação de Estilo Musical”