Como qualquer área, a Ciência de Dados e o Machine Learning estão cheio de desafios, coisas que complicam a obtenção de um bom modelo preditivo. Pensando nisso, compilei aqui os maiores desafios em Machine Learning, baseado principalmente nos livros The Hundred-Page Machine Learning Book e Hands-on Machine Learning with Scikit-Learn & Keras. Já adiantando, este post teve início em uma thread que fiz no Twitter, sobre conceitos de Machine Leanring. Você pode acessá-la clicando aqui.
INSUFICIENTES DADOS PARA TREINAMENTO
Ppara que o modelo saiba indicar coisas como “esse cara não vai pagar”, “esse cara vai deixar de ser seu cliente”, etc., ele precisa olhar como se comportam pessoas que não pagam ou que deixam de ser cliente. Ou seja, ele precisa olhar para o histórico de pessoas que já fizeram isso e aprender. Igual quando a gente é criança e aprende o que é um carro. A gente sabe porque a gente viu alguém mostrar um carro e dizer que se chama carro. Não adianta você ter um puta modelo se você não tem dados suficientes para que ele aprenda. Isso inclusive já foi abordado algumas vezes, como mostrado em “The Unreasonable Effectiveness of Data” (2009).
DADOS NÃO-REPRESENTATIVOS (VIÉS)
Mais uma vez, a importância de ter dados. Neste caso, ter BONS DADOS. Imagine que você quer treinar seu modelo para pegar os não-pagadores. Mas te chega uma base só com os pagadores. Ele não vai conseguir saber a característica de um não pagador. Quer um exemplo legal? Pesquisas feitas por enquetes do Twitter. Tente criar algum modelo com isso e veja o insucesso você mesmo.
DADOS DE BAIXA QUALIDADE
Missing, outlier, tudo isso é delicado na hora de construir um modelo. Saiba quando descartar a observação e quando tratá-la. Mas mais ainda, veja a possibilidade de evitar isso. Se for problema da coleta, voltamos ao problema anterior.
CARACTERÍSTICAS IRRELEVANTES
Você só consegue fazer uma boa predição se os motivos para que o evento ocorra estiverem nos dados levantados. Imagine que você queira saber se o cliente vai pagar ou não. Seria legal ter a informação do tamanho da dívida, da quantidade de contratos que ele tem com a empresa, se ele tem casa própria e por aí vai. Aí te chega uma base com a data de nascimento dele e o gosto musical. A não ser que você seja esses malucos que acreditam em astrologia, não dá para tirar muito dessa informação. Isso porque eu só quis citar duas variáveis, mas poderiam ter vindo 10 e as 10 serem inúteis. Além de ter boas variáveis, tratá-las adequadamente é de extrema importância. Saber como criar novas variáveis a partir da informação que você tem pode ser um trunfo. Um pouco mais sobre feature engineering: 7 feature engineering techniques for Machine Learning/.
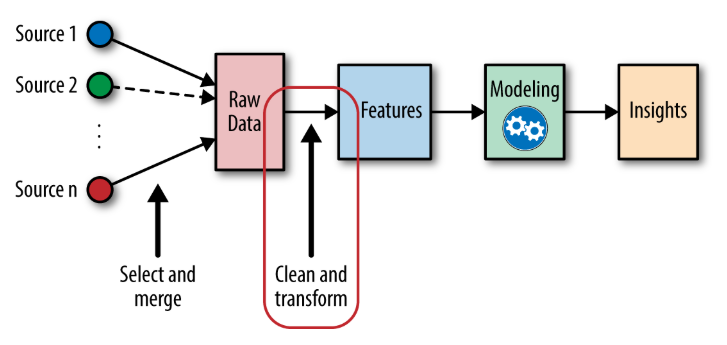
Veja o fluxo abaixo para entender em que momento da construção do modelo nós estamos:
OVERFITTING
Essa eu já cansei de abordar aqui no site e nunca é demais, já que é o erro de muita gente que está iniciando na área. Overfitting nada mais é do que aquele aluno que estuda a mesma lista várias vezes, decora e não consegue fazer a prova. É o cara do “poxa, eu sabia esse exercício com maçãs”. É quando um modelo se ajusta bem até demais aos dados de treino e acaba sendo ineficaz com novos dados. Imagine que o seu modelo aprendeu tão bem, mas tão bem, que até os erros ele considerou como parte da predição.
Outra explicação que eu gosto bem básica: Overfitting em anedota
Um jeito simples de identificar é comparar o modelo no treino e teste. Se no treino for muito bem e no teste muito mal, é quase certo que você tem um problema de overfitting.
Formas de lidar com o overfitting:
- Regularização (Regularização: Introdução ao conceito e sua importância)
- Validação cruzada
- Early stopping
- Obtenha mais dados
UNDERFITTING
A última, mas não menos importante, é exatamente o oposto do item anterior. No caso do underfitting, o modelo não consegue capturar a complexidade do problema, seu desempenho é ruim. Você pode resolver isso adicionando mais features, tentando um modelo mais poderoso, regularização, etc.
E já que uma imagem vale mais do que mil palavras, creio que seja razoável deixar essa aqui:
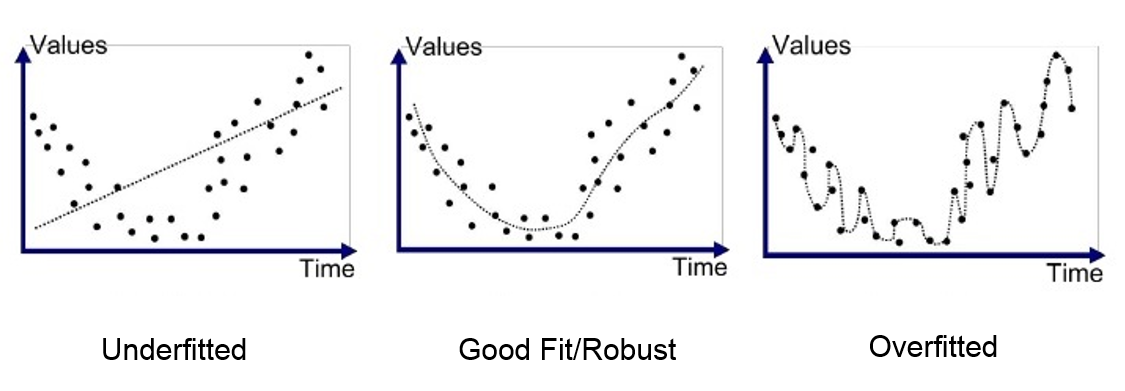
Formas de evitar o underfitting:
- Mais features
- Feature engineering pode ajudar (veja o link em Características Relevantes)
- Obtenha mais dados
- Reduzir a regularização
CONSIDERAÇÕES FINAIS
Por fim, vale lembrar um tweet do Alexey Grigorev, Lead Data Scientist da OLX: se o seu modelo de Machine Learning está 99% correto, algo está errado. Possíveis razões:
- Métrica de avaliação errada: Usar somente acurácia, ignorando curva ROC, f1-score, matriz de confusão, etc.;
- Dados de validações ruins: Já explicado acima;
- Overfitting: Já explicado acima;
- Data Leakage: Por exemplo, dividir em treino/teste antes de fazer tratamentos como imputar missing e one-hot encoding;
Bom, agora você não só conhece os maiores desafios de Machine Learning, como sabe como lidar com eles. Sendo assim, nesta questão, você pode se sentir mais tranquilo de que seu modelo não vai cair num erro besta já conhecido.
E aí? Gostou do conteúdo? Se inscreva para receber todas as novidades. Deixe seu e-mail em INSCREVA-SE na barra à direita, logo abaixo de pesquisar. E, por favor, não deixe de comentar, dar seu feedback e, principalmente, compartilhar com seus amigos. De verdade, isso faz toda a diferença. Além disso, você também pode acompanhar mais do meu trabalho seguindo a conta de Twitter @UniDosDados ou por alguma das redes que você encontra em Sobre o Estatsite / Contato, como meu canal de Youtube Canal Universidade dos Dados. E se você gosta de tecnologia, escute o podcast Futuristando!
Bons estudos!