A função aggregate no R é bem interessante. Como o próprio nome diz, ela agrega as informações de um dataframe, incluindo alguma função que é especificada por um parâmetro chamado FUN. Sendo assim, é algo bem interessante para você analista ou cientista de dados!
Vejamos um exemplo utilizando a base mtcars do próprio R:
## Para visualizar os dados: head(mtcars) # ou View(mtcars) ## cria uma tabela com combinacoes de cyl e gear e uma estatistica ## descritiva do mpg para cada combinacao myData <- aggregate(mtcars$mpg, by = list(cyl = mtcars$cyl, gears = mtcars$gear), FUN = function(x) mean = mean(x));
No exemplo acima, o resultado é um data frame com 8 linhas, sendo que cada linha possui na primeira coluna o campo cyl e na segunda o campo gear, e para cada combinação temos a média, desvio padrão e número de mpg diferentes que aparecem:
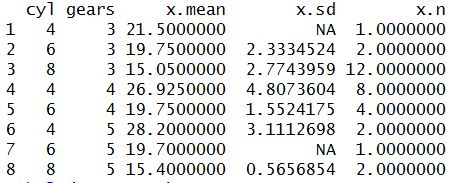
Ou seja, olhando para nossa segunda linha, temos que para carros com 6 cilindros (cyl) e 3 marchas (gears) a média de milhas por galão é 19.75, o desvio padrão é 2.3334524 e há dois elementos nessa base com essas características. Fica a seu critério qual função você quer utilizar, poderia ser o máximo, o mínimo, ou até mesmo uma função que você criou em R.
Veja que utilizamos c() porque estamos trabalhando com diversas funções. Fazemos a mesma coisa quando criamos um vetos com diversos elementos:
exemplo = c(1,2,3,4,5);
Se quiséssemos incluir somente a função média, nosso código ficaria:
myData <- aggregate(mtcars$mpg, by = list(cyl = mtcars$cyl, gears = mtcars$gear), FUN = function(x) mean = mean(x));
E aí, curtiu o post?
E aí? Gostou do conteúdo? Se inscreva para receber todas as novidades. Deixe seu e-mail em INSCREVA-SE na barra à direita, logo abaixo de pesquisar. E, por favor, não deixe de comentar, dar seu feedback e, principalmente, compartilhar com seus amigos. De verdade, isso faz toda a diferença. Além disso, você também pode acompanhar mais do meu trabalho seguindo a conta de Twitter @UniDosDados, no Instagram @universidadedosdados ou por alguma das redes que você encontra em Sobre o Estatsite / Contato, como meu canal de Youtube Canal Universidade dos Dados.
Aproveite e adquira sua camiseta de data science na LOJA DA UNIVERSIDADE DOS DADOS. Vai ficar estiloso e me ajudar neste projeto!
BONS ESTUDOS!
Olá Yukio:
suponha que exista a seguinte tabela de dados no R:
ID<-c(9673,9673,15049,15049,15049,15049,15049,15049,15049,15049,15049,15049, 15049)
dt_inicio<-c("2018-01-25","2018-04-09","2010-08-26","2010-12-22","2011-04-19", "2012-09-12","2013-07-10","2014-04-09","2014-09-10","2015-03-11","2015-10-14", "2016-08-10","2017-03-08")
dt_fim<-c("2018-04-09","2018-08-28","2010-12-22","2011-04-19","2012-09-12", "2013-07-10","2014-04-09","2014-09-10","2015-03-11","2015-10-14","2016-08-10", "2017-03-08","2017-09-13")
CD4_status<-c(0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
VL_status<-c(2, 0, 2, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0)
ART_adher<-c(0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 0)
TP_FOLLOW<-c(74,141, 118, 118, 512, 301, 273, 154, 182, 217, 301, 210, 189)
database%summarise(Total=sum(TP_FOLLOW))
não me atende pq ele soma o TP_FOLLOW de todos os resultados iguais e não considera somente aqueles que estão em intervalos consecutivos….Desde já agradeço a compreenção, abraços
Oi, Cassia! Acabei de ver sua dúvida. Vou tentar ver aqui pela manhã e já te respondo. Abs
Oi Cassia, não entendi o que vc quer fazer.
Como assim somar o TP_FOLLOW em resultados consecutivos?
Olá, obrigada pelos ensinamentos.
Mas fiquei com duvida quanto a usar a minha própria função.
Gostaria de obter o R² fazendo a regressão linear para cada grupo. Meu código esta assim, mas não consigo rodar.
> dados
Rótulos.de.Linha ORDEM area.ACM Largura
1 0 1 90.10 3.78
2 0 2 239.20 13.61
3 0 3 639.62 22.21
…
22 1 3 1148.70 15.46
23 1 4 1483.86 23.16
24 2 1 188.40 9.76
25 2 2 381.31 9.73
x <- dados$area.ACM
y <- dados$Largura
model <- lm(log(y)~log(x))
novosdados <- aggregate(dados,
by = list(rotulo = dados$Rótulos.de.Linha),
FUN = function(model))