Provavelmente a tarefa mais comum de alguém que trabalha com dados seja combinar diferentes tabelas para se obter toda a informação que precisa. Por exemplo, se em uma tabela você tiver o nome dos seus clientes e a informação de idade em uma base de dados, e em uma segunda tabela tiver informações como endereço e sexo, é bem provável que ao fazer um estudo, um modelo estatístico, você tenha que combinar estas duas tabelas. Vamos ver agora como combinar duas tabelas de algumas formas diferentes.
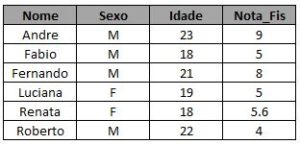
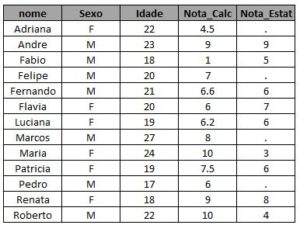
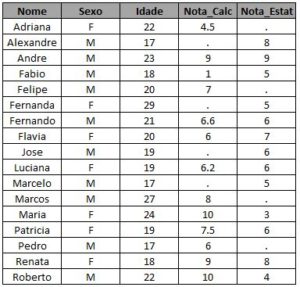
Vamos utilizar como exemplo duas turmas da faculdade, uma do curso de Cálculo e outra do curso de Estatística.Podemos ter alguns alunos matriculados em uma delas e não matriculados na outra e vice-versa. As duas tabelas abaixo contêm os alunos de cada turma, o sexo, a idade e a nota final da disciplina:

 Caso alguém ainda não saiba criar sua própria tabela para treinar, segue o código utilizado para gerar as que serão utilizadas aqui:
Caso alguém ainda não saiba criar sua própria tabela para treinar, segue o código utilizado para gerar as que serão utilizadas aqui:
data turma_calc;
length nome $22.;
input Nome $ Sexo $ Idade Nota_Calc;
datalines;
Roberto M 22 10
Maria F 24 10
Pedro M 17 6
Renata F 18 9
Andre M 23 9
Marcos M 27 8
Patricia F 19 7.5
Luciana F 19 6.2
Adriana F 22 4.5
Fernando M 21 6.6
Felipe M 20 7
Flavia F 20 6
Fabio M 18 1
;
run;
data turma_estat;
length nome $22.;
input Nome $ Sexo $ Idade Nota_Estat;
datalines;
Roberto M 22 4
Maria F 24 3
Jose M 19 6
Renata F 18 8
Andre M 23 9
Alexandre M 17 8
Patricia F 19 6
Luciana F 15 6
Fernanda F 29 5
Fernando M 21 6
Marcelo M 17 5
Flavia F 20 7
Fabio M 18 5
;
run;
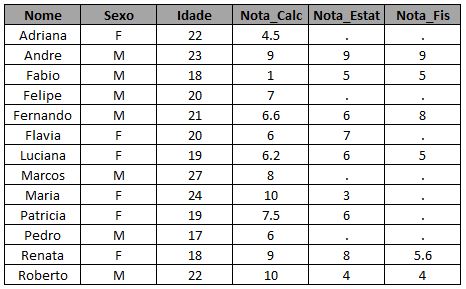
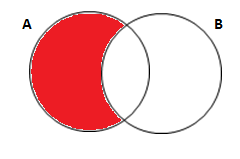
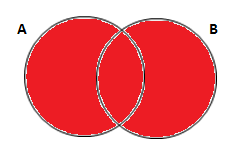
Vamos supor que você queira completar a primeira tabela com as notas de estatística para os alunos que cursaram as duas matérias, mas quer manter os demais também na tabela. Ou seja, pensando em dois conjuntos, você quer adicionar a informação que está na intersecção dos conjuntos A e B à informação do conjunto A. Abaixo temos a representação desse caso em um Diagrama de Venn seguido pelo código em SAS e a tabela de saída deste código:

* traz as notas de estatisticas para a tabela com os alunos de calculo;
proc sql;
create table exemplo_1 as
select a.*, b.*
from turma_calc as a
left join turma_estat as b
on a.nome = b.nome;
run;
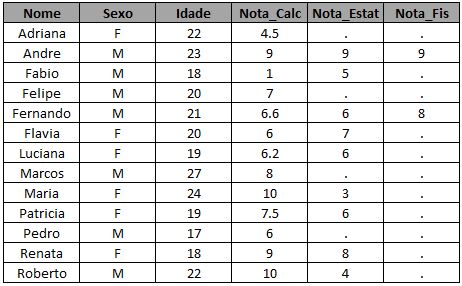
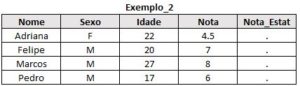
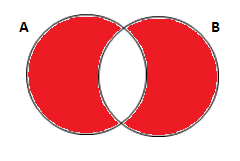
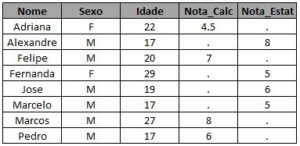
E se você quiser apenas os alunos que cursaram somente cálculo, excluindo quem cursou a outra disciplina:
* traz os alunos que cursaram apenas Calculo;
proc sql;
create table exemplo_2 as
select a.*, b.*
from turma_calc as a
left join turma_estat as b
on a.nome = b.nome
where b.nome is NULL;
run;
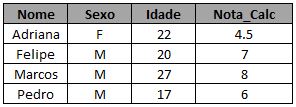
Caso você não quisesse essa última coluna, bastaria não ter selecionado nada da tabela b:
proc sql;
create table exemplo_2b as
select a.*
from turma_calc as a
left join turma_estat as b
on a.nome = b.nome
where b.nome is NULL;
run;
Se quiser trazer os alunos das duas turmas:
* traz todos os alunos das duas turmas;
proc sql;
create table exemplo_3 as
select coalesce (a.nome, b.nome) as Nome
, coalesce (a.sexo, b.sexo) as Sexo
, coalesce(a.idade, b.idade) as Idade
, a.*
, b.*
from turma_calc as a
full join turma_estat as b
on a.nome = b.nome;
run;
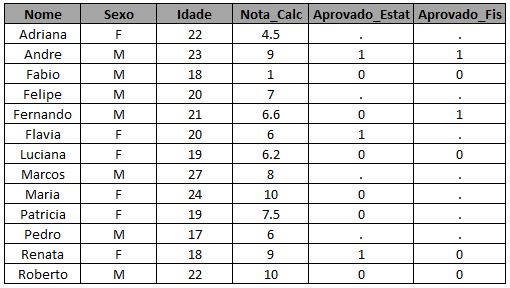
Se você não quiser os alunos que cursaram as duas matérias, quiser apenas quem cursou uma:
* traz os alunos que cursam somente um dos dois cursos;
proc sql;
create table exemplo_4 as
select coalesce (a.nome, b.nome) as Nome
, coalesce(a.sexo, b.sexo) as Sexo
, coalesce(a.idade, b.idade) as Idade
, a.*
, b.*
from turma_1 as a
full join turma_2 as b
on a.nome = b.nome
where a.nome is NULL or b.nome is NULL;
run;
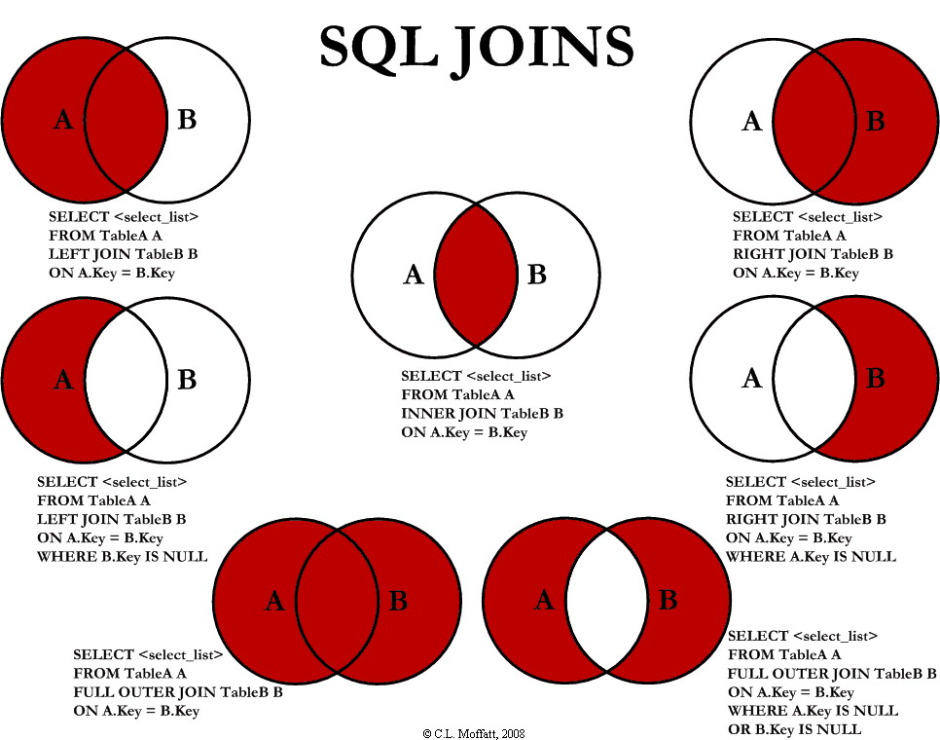
Se você já programou em sas ou sql, também já ouviu falar do right join, que muda muito pouco com relação ao left join. Como o próprio nome implica, você vai inverter a ordem das tabelas que serão unidas. Veja abaixo uma imagem completa que descreve todas as funções join do sql:
E aí? Gostou do conteúdo? Agora, imagine estudar análise e ciência de dados com trilhas estruturadas e projetos práticos, com direcionamento claro do que aprender e em que ordem. No nosso Clube de Assinaturas, você encontra desde o essencial para entrar na área de dados, até temas que diferenciam profissionais mais seniores no mercado, como inferência causal, engenharia de software e álgebra linear aplicada a ML.
Conheça: www.universidadedosdados.com