
Já havia falado da importância de identar seu código nesse post. Continuar a ler “Identando seu código Google’s style!”
Falando de Ciência de Dados desde 2016
Já havia falado da importância de identar seu código nesse post. Continuar a ler “Identando seu código Google’s style!”

Um oferecimento TI da depressão
Family Feud com autocomplete do Google:
Source: Google Feud
Ps.: Encontrei esse “joguinho” divertido no analisereal.com
A função read.table() do R serve para importar arquivos de diversos formatos. O print abaixo apresenta a descrição do que a função é capaz de fazer e algumas variações dela, como o read.csv() – muito embora a própria read.table() seja capaz de ler arquivos csv.
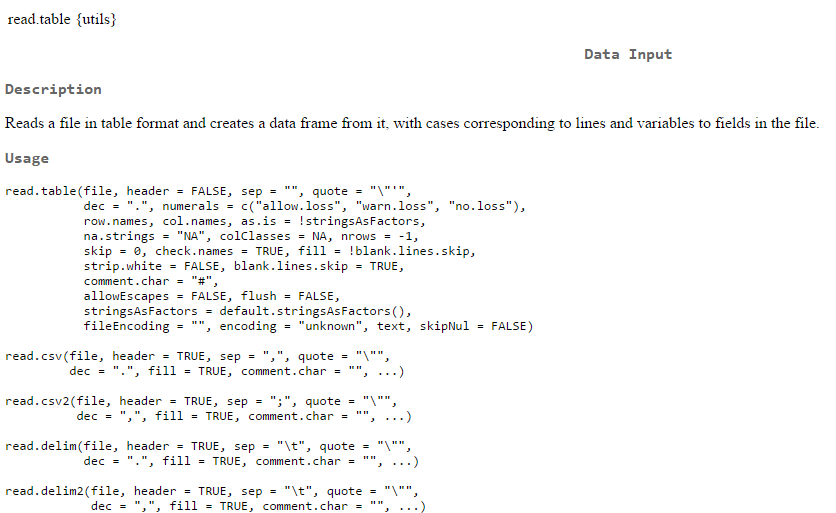
Não tem muito segredo para ler arquivos. Vejamos um exemplo de como ler um arquivo utilizando as principais especificações da função e vamos nomear o arquivo dados_exemplo:
dados_exemplo = read.table("C:/Users/Public/Desktop/tabela_exemplo.txt",header=TRUE,sep="\t",dec=",");
Item a item temos:
Após os dados serem importados você pode fazer pequenas manutenções (algumas poderiam ser feitas inclusive na hora de importar):
colnames(dados_exemplo) = c("NomeDaColuna 1";"NomeDaColuna 2";"NomeDaColuna 3";"NomeDaColuna 4",...)
## Para abrir a tabela de dados View(dados_exemplo) ## Para observar as primeiras linhas head(dados_exemplo) ## Para visualizar da primeira a décima linha, e da primeira a quinta coluna: dados_exemplo[1:10,1:5] ## Para visualizar a primeira linha da coluna 3 dados[1,"NomeDaColuna"]
dados_exemplo=dados_exemplo[order(dados_exemplo[,"NomeDaColuna"],decreasing = TRUE),];
ou
dados_exemplo$NomeDaColuna = sort(dados_exemplo$NomeDaColuna ,decreasing = TRUE)
E aí? Gostou do conteúdo? Se inscreva para receber todas as novidades. Deixe seu e-mail em INSCREVA-SE na barra à direita, logo abaixo de pesquisar. E, por favor, não deixe de comentar, dar seu feedback e, principalmente, compartilhar com seus amigos. De verdade, isso faz toda a diferença. Além disso, você também pode acompanhar mais do meu trabalho seguindo a conta de Twitter @UniDosDados, no Instagram @universidadedosdados ou por alguma das redes que você encontra em Sobre o Estatsite / Contato, como meu canal de Youtube Canal Universidade dos Dados.
Aproveite e adquira sua camiseta de data science na LOJA DA UNIVERSIDADE DOS DADOS. Vai ficar estiloso e me ajudar neste projeto!
BONS ESTUDOS!
Não deixe de treinar seus conhecimentos em R na seção Exercícios em R. A cada semana novos exercícios com as respectivas respostas!
Já falei de como trabalhar com datas no SAS em posts antigos, como em Formatando Datas no SAS. No entanto, nem sempre queremos trabalhar só com as datas que já estão nos nossos dados. Vamos supor que a gente queira trabalhar apenas com os alunos nascidos a partir de 31/01/1999 dos dados no post Como calcular a diferença entre duas datas no SAS?
Se você quiser pegar as informações cuja data é maior que 31/01/1999, os exemplos abaixo não funcionarão:
O SAS não vai entender que o que está à direita é uma data, para ele é um texto qualquer. Para trabalhar com essa data você precisaria utilizar as iniciais do mês e um d após o fechamento das aspas. No nosso exemplo, o que funcionaria seria:
if dt_nasc > "31jan1999"d;
Lembre-se que você deve colocar as iniciais do mês em inglês. Ou seja, para setembro, use “31sep2015″d ao invés de “31set2015″d!
O que é clustering?
Imagine o dono de uma loja com todo o histórico do que seus clientes compraram. Esse histórico permite que o lojista procure o tipo de produto que o cliente pode se interessar. Porém, fazer isto para cada cliente individualmente não é muito eficiente. Seria mais prático ele separar os clientes por grupos de acordo com a semelhança entre as preferências desses clientes. Assim, ele terá que pensar na recomendação para cada grupo, sendo que o número de grupos seria muito menor que o número de indivíduos.
Sendo assim, o que o lojista precisaria fazer era pensar em como separar os indivíduos, pensando no número de grupos que quer formar e qual critério de separação. Isso pode ser feito através de técnicas de clustering. (traduzido e adaptado de: K-means Clustering Tutorial)
Clustering é o método separar seus dados em grupos (clusters) quando estamos minerando dados. Ou seja, nada mais é do que unir indivíduos de sua base de dados com base em suas semelhanças.
Um algoritmo bastante utilizado é o k-means (traduzido por alguns como k-médias). Este algoritmo serve para agrupar os dados em grupos com base nas distâncias à média.
Vejamos um exemplo para facilitar o entendimento:
Queremos aplicar o k-means nos indivíduos 1,2,3,4,5,6,7,8,9 e 10, que possuem determinados valores em duas variáveis quaisquer X e Y:
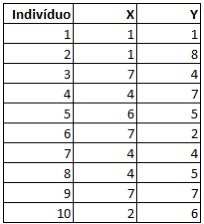
Para a utilizar o algoritmo precisamos escolher o número de grupos que queremos utilizar.
Para facilitar, no nosso exemplo iremos agrupar em dois grupos.
Iniciamos com um grupo contendo o elemento 1 e um outro grupo contendo o elemento 9.

Agora vamos alocar os elementos mais próximos de cada grupo de acordo com a distância entre os pontos. Por exemplo, note que a distância do indivíduo 4 é 6,7 para o Grupo 1, enquanto a distância ao Grupo 2 é 1,4. Logo, ele deve pertencer ao Grupo 2.
Fazemos a mesma comparação para os demais elementos e chegamos a essa divisão:

Note que as médias de cada grupo se alterou. Podemos então reagrupar os elementos, novamente através da distância às médias.
Por exemplo, a distância do indivíduo 4 em relação ao Grupo 1 agora é 3 e em relação ao Grupo 2 é de 3,7. Ou seja, ele agora está mais próximo do Grupo 1.
O mesmo deve ser feito para os demais elementos:

Esse processo é feito sucessivamente até que se encontre o melhor agrupamento, dado o critério de distância à média.
Dúvidas? Críticas? Deixe um comentário!

