Muitas vezes quando você faz uma regressão, você quer saber quanto uma variável impacta a outra, por exemplo quanto um ano a mais de estudos impacta o salário. No entanto, outras variáveis podem afetar o salário, como profissão e até o sexo. Para saber como os anos de estudos impactam o salário, você precisa controlar as demais variáveis e isolar o efeito dos anos de estudos. Sendo assim, as variáveis profissão e sexo devem ser levadas em conta na sua análise, basicamente sendo inseridas na sua regressão. Isso são as variáveis de controle, são variáveis que possivelmente ou com certeza causam efeito na sua variável dependente, no nosso caso o salário, e que devem ser levadas em consideração para que a gente consiga estimar o efeito único de uma variável independente na variável dependente.
O impacto que seus colegas tem sobre suas decisões
É interessante observar como nós respondemos as pressões sociais. Desde pequenos tomamos decisões influenciados pelo grupo ao qual pertencemos. O que pouca gente sabe é que isso tem um custo, para o indivíduo e para a sociedade. No artigo How does peer pressure affect educational investments?, Leonardo Bursztyn e Robert Jensen buscam explicar como a pressão social faz com que alunos deixem de fazer um curso preparatório para o SAT, um vestibular utilizado nos EUA. Continuar a ler “O impacto que seus colegas tem sobre suas decisões”
Comentando no SAS
Mais um (breve) post sobre o SAS.
Aqui você vai aprender como deixar seus comentários nos códigos, para se lembrar do que fez ou para que outra pessoa consiga executá-los. Continuar a ler “Comentando no SAS”
Visualizando seus dados: Histograma
Um histograma nada mais é do que uma forma de representar seus dados utilizando um gráfico de barras onde o eixo y representa a frequência e o eixo x os intervalos (chamados também de classes) dos seus dados. Simples assim. E já para dar uma ideia antes mesmo das definições mais formais, veja esse exemplo de um conjunto de dados e um histograma executado automaticamente pelo excel (veja o passo a passo no Canal da Educação):

Só de bater o olho, acho que a maioria já consegue entender o que o histograma apresenta. Ele nos dá uma ideia de como nossos dados estão distribuídos, mas para isso ele separa nossos dados em classes, ou, como o excel chamou, em blocos. Veja o que o excel fez, ele separou nossos dados em 5 intervalos:
Menor ou igual a 1, maior que 1 e menor ou igual a 25, maior que 25 e menor ou igual a 49, maior que 49 e menor ou igual a 73 e um último intervalo como sendo os números acima de 73. Para cada intervalo, ele contou o número de elementos dos nossos dados que fazem parte do intervalo em questão e a partir daí fez o gráfico de barras.
Quantos números do nosso conjunto de dados são menores ou iguais a 1? Apenas 1. Quantos são maiores que 1 e menor ou igual a 25? Apenas 6.
Eu não sou fã desse histograma do excel por achar pouco intuitivo os pontos 1, 25, 49, 73 e “Mais” estarem localizados no meio da barra mas não serem o ponto médio do intervalo. É bom se atentar a isso. Mas, deixando a crítica de lado e voltando ao assunto…
Nesse gráfico, o excel nos devolveu o resultado em termos da frequência absoluta, que nada mais é que o número de vezes em que determinado dado aparece. O histograma também pode ser construído com base na frequência relativa, que é o número de vezes em que determinado dado aparece dividido pelo número de elementos da nossa amostra ou população. Em outras palavras, é a representação percentual. Veja esse exemplo com os mesmos dados, mas utilizando a frequência relativa:

E NO SAS? COMO FAZEMOS UM HISTOGRAMA
A forma mais rápida que eu conheço é pelo proc univariate, é bem simples. Basta acrescentar histogram logo após você selecionar as variáveis que deseja visualizar o histograma. No exemplo abaixo, vamos inserir através do Datalines a data e o índice Ibovespa (índice na abertura, alta, baixa, etc.) e em seguida utilizamos o proc univariate para gerar o histograma:
data dados;
input notas;
datalines;
3.6
3.6
5
6.4
6.6
6.6
6.8
7.5
8
8.7
9
9.5
;
proc print;
run;
proc univariate data = dados;
var notas;
histogram;
run;

Veja que o SAS criou seus intervalos também.
E se eu quiser alterar a forma como as classes estão divididas?
Bom, nesse caso podemos usar tanto o endpoints como o midpoints e escolher o intervalo inferior de todas as classes, o superior, e qual tamanho de cada classe. Veja esse exemplo com midpoints e tente brincar depois com endpoints:
proc univariate data = dados; var notas; histogram / midpoints=(3 to 10 by 2) ; run;

Percentil – Conceito e Código SAS
Expliquei o conceito de mediana nesse post quando falei de estatística descritiva. O que não falei é que a mediana pode ser chamada também de 50° percentil (ou p50). Continuar a ler “Percentil – Conceito e Código SAS”
Como formatar datas no SAS
E aqui estamos mais uma vez para aprender como deixar nossos datasets melhor formatados. Dessa vez, falaremos de um problema recorrente em qualquer linguagem: datas. Como este campo pode vir em formato numérico ou texto, as pessoas tendem a ter problemas com operações ou até quando traçam gráficos utilizando eles. Sendo assim, hoje vamos aprender como formatar datas no SAS. Continuar a ler “Como formatar datas no SAS”
Média Móvel: Explicação, Comando SAS e Função LAG
A maioria das pessoas conhece e utiliza a média no dia a dia. O que alguns não conhecem é a média móvel. O que seria isso?
A média móvel nada mais é do que a média de um determinado número de observações recentes. Por exemplo, suponha que você seja dono de uma oficina e venda peças para automóveis. Suas vendas trimestrais estão representadas pela tabela abaixo:
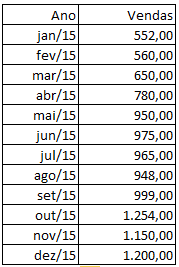
Você é cauteloso com o seu orçamento, e, para decidir quanto gastar no ano seguinte, você quer verificar a tendência das vendas. Uma alternativa é utilizar a média móvel trimestral, que seria nada mais do que a média dos últimos três meses. Ou seja, você irá sempre pegar a média dos últimos três meses. Isso é útil para verificar se está havendo uma tendência de crescimento ou uma reversão, pois você captura movimentos recentes de vendas:
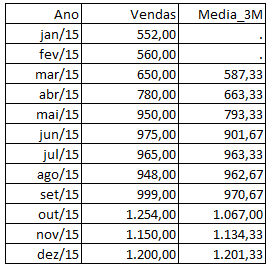
Simples, não?
Bônus – Média Móvel no SAS:
Para calcular a média móvel no SAS você precisará de algo que identifique os meses anteriores ao que você está analisando, isso pode ser obtido com a função lag().
Vamos supor que a tabela do exemplo acima foi criada no SAS com o nome BASE_VENDAS, contendo as variáveis: Ano e Vendas. Ao utilizar LAG(vendas), obteremos a variável vendas com uma defasagem. Ao utilizar LAG2(vendas), obteremos a variável vendas com duas defasagens:
data Variaveis_Defasadas;
set Base_Vendas;
Vendas_M1 = lag(vendas);
Vendas_M2 = lag2(vendas);
run;
Esse é o resultado:
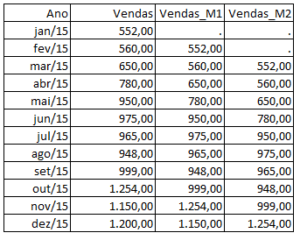
Agora ficou fácil descobrir como chegar a média móvel, certo?
data Media_Movel;
set Variaveis_Defasadas;
Media_3M = SUM(Vendas,Vendas_M1,Vendas_M2)/3;
DROP Vendas_M1 Vendas_M2;
run;
Simples não?
Apenas para sanar quaisquer dúvidas:
SUM = Soma as variáveis, utilizando a vírgula para separá-las.
DROP = Exclui da tabela as variáveis (as colunas) que você não precisa mais.
SAS “não University”
O SAS que você irá se deparar na sua empresa provavelmente não se parece muito com o SAS University. Porém, os códigos que ensinaremos no University também servem para o SAS Guide do lugar onde você trabalha. Há algumas diferenças que também abordaremos no site para você não ficar confuso.
Para começar, você precisa saber no SAS Enterprise Guide, as tabelas encontram-se em estruturas físicas chamadas libname, entenda a libname como uma pasta em um diretório que você vai salvar suas tabelas, simples assim. Você salva as coisas no seu computador em diversas pastas, certo? Aqui é igual, você irá salvar em várias pastas. Para acessá-las, são dois passos simples:
1° – “Chame a Libname”:
Libname YUKIO "sasdata/estudos/Yukio";
2° Inicie a leitura da tabela com o nome da libname:
Data Aula_1; SET YUKIO.Tabela_1; Run;
Como vocês podem ver, primeiro eu tive que inserir no código uma linha para chamar a libname Yukio. Isso feito, eu utilizei um datastep simples apenas para atribuir todo o conteúdo da Tabela_1 localizada na libname Yukio em uma nova tabela chamada Aula_1. Eu simplesmente coloquei toda informação da Tabela_1 na Aula_1.
DATA é o comando para criar uma tabela nova, nesse caso a tabela chama Aula_1.
SET é comando que está lendo uma tabela qualquer, nesse caso a tabela sendo lida é a Tabela_1 que está na libname Yukio. Ok, mas e se escrevermos apenas Tabela_1, sem o YUKIO antes? O SAS nos voltaria um erro falando que não existe essa tabela, a não ser que ela exista na WORK (falaremos disso algumas linhas abaixo).
RUN é utilizado para finalizar o código. É basicamente o comando que deve ser utilizado ao final de cada código.
Agora, voltando a questão da . A work nada mais é do que a sua pasta temporária dentro do SAS.
Vamos pensar num exemplo prático:
Suponha que você tenha salvo a tabela do IBOVESPA do post anterior na libname YUKIO.
Como você faria isso? Simples, lembra que iniciamos o código passado com Data Ibovespa?
Basta iniciá-lo com Data Yukio.Ibovespa, e pronto, toda informação inputada está nesse endereço. Agora, olhe para o código abaixo dividido em duas partes:
DATA Ibovespa_v1; SET YUKIO.IBOVESPA; RUN; DATA Ibovespa_v2; SET Ibovespa_v1; IF Close > 50000; RUN;
Como já vimos no início, o primeiro Datastep inserido não faz nada além de copiar as informações de YUKIO.Ibovespa na tabela chamada Ibovespa_v1. Como não há nada antes do nome, essa tabela Ibovespa_v1 está salva na work, é temporária.
O segundo código, está lendo a tabela Ibovespa_v1 que está na work, na nossa pasta temporária. Ou seja, como já rodamos o primeiro código, existe uma tabela, chamada Ibovespa_v1, que não está em nenhuma libname, em nenhuma pasta. E onde está essa tabela? Ela está no que chamamos de work! A tabela está no SAS, você consegue executar códigos com ela enquanto não fechar o SAS. Após fechá-lo, você perde essa tabela, mas enquanto está aberto, você pode trabalhar com ela.
Ahhh, e tem o IF lá! Famoso IF!!!
If é um dos comandos mais utilizados em qualquer linguagem, e não tem segredo, é a tradução da palavra do inglês (=SE). É uma condicional, você quer ler a tabela Ibovespa_v1 e receber o resultado na tabela Ibovespa_v2 seguindo a condição imposta no IF, nesse caso, é a do valor de fechamento estar acima de 50000. Ou seja, você criou uma tabela chamada Ibovespa_v2 na sua work, com as mesmas colunas que a tabela Ibovespa_v2, mas só com as linhas em que o índice de fechamento está acima de 50000.
AVISO AOS INICIANTES EM SAS
Um dos maiores erros cometidos por iniciantes em SAS é sobrescrever uma tabela dentro de uma libname, ou seja, salvar algo em cima de uma tabela existente e perder a informação que havia nela.
Diferente de outros programas como o Excel, no SAS você não pode sair executando qualquer código e, se algo der errado, fechar o programa sem salvar, esperando que as tabelas modificadas voltem ao normal quando reabrir o programa. Não é assim que funciona.
Isto é, se você, por exemplo, possuir uma tabela chamada TABELA_1 na libname YUKIO e fizer um data set que crie uma tabela_1 na libname yukio, o comando irá sobreescrever a tabela_1 existente. Sem que eu precise ir lá em salvar como.
Por isso, minha sugestão para iniciantes é executar TUDO do código que receber na work. Ou então, alterar os nomes das bases em todos os data set que você tiver. Exemplo: Você recebeu o código abaixo de um colega. O processo que ficava com a pessoa, agora passará a ser seu.
/*filtra clientes SP*/ data lib.tabela_sp; set tabela_geral; if uf = "SP"; run;
O que você deve fazer é substituir a libname utilizada por work ou deixar em branco:
/*substitui a lib por work*/ data lib.tabela_sp; set tabela_geral; if uf = "SP"; run;
Ou então utilizar uma libname sua criada:
/*substitui a lib por uma lib nova sua*/ data novalib.tabela_sp; set tabela_geral; if uf = "SP"; run;
Agora você não está sobreescrevendo nenhuma tabela e não corre risco de perder as informações de seu colega. Ao final do código, você pode simplesmente dar um set na sua tabela final em uma lib sua.
Introdução ao SAS e ao SAS University

Este post possui uma versão atualizada: Instalando o SAS University… de novo.
Hoje vamos dar início a uma série de posts com mais conteúdo de programação, especificamente em SAS. Por quê? Porque se você pretende fazer modelos estatísticos utilizando grandes bases de dados – e.g.: bases de 10 milhões de linhas -, você não vai conseguir utilizar o Excel.
Você pode até tentar utilizar o R, já mencionado aqui, um software gratuito e bastante popular. Porém, não é tão comum ver o R nas grandes empresas – pelo menos não nas brasileiras -, principalmente porque o SAS fornece outros serviços. Além disso, o que eu (e alguns outros) consideram uma grande vantagem no R é considerada por alguns sua maior desvantagem: os pacotes criados pelos usuários. Muitos usuários podem criar pacotes com funções prontas para ajudarem nas análises, mas não há garantia de que o pacote não possui erros. Um software como o SAS é menos propenso a esse risco.
O SAS é um software criado na década de 60-70 e hoje é um dos maiores players de mercado de analytics. A programação SAS é simples, e com a prática torna-se intuitiva , sua estrutura é composta de procedimentos e dados (data e procs), e aprofundaremos em cada tópico quando for necessário.
Embora o SAS mais utilizado nas empresas seja uma versão paga, o software possui também sua versão gratuita: o SAS University. Se você tiver dificuldades com a instalação, veja o passo a passo em Instalando o SAS University.
DATA x PROC
O SAS possui dois modos principais para trabalhar com os dados, o comando DATA e o PROC. Ambos servem para ler os dados e fazer manipulações. Porém, há uma variedade de procedimentos PROC que servem para análises estatísticas. A sintaxe básica é a seguinte:
DATA NOME_DA_TABELA_NOVA; SET NOME_DA_TABELA_ANTIGA; (TRATAMENTO 1) (TRATAMENTO 2) . . . (TRATAMENTO N) RUN;
O que o código acima faz?
Ele pega uma base de dados qualquer, aqui chamamos de NOME_DA_TABELA_ANTIGA, faz uma série de tratamentos quaisquer, como filtrar clientes ou criar novos campos, e cria uma nova base com estes tratamentos, aqui chamamos essa nova base de NOME_DA_TABELA_NOVA. O comando RUN serve para executar o código.
Utilizando o PROC, poderíamos fazer o mesmo código da seguinte forma:
PROC SQL; CREATE TABLE NOME_DA_TABELA_NOVA AS SELECT * FROM SET NOME_DA_TABELA_ANTIGA; RUN;
Porém, a inserção dos tratamentos varia caso a caso, a depender de qual tratamento está sendo feito (você verá abaixo um exemplo). Poderíamos ter algo como:
PROC SQL; CREATE TABLE NOME_DA_TABELA_NOVA AS SELECT *, (TRATAMENTO 1) FROM SET NOME_DA_TABELA_ANTIGA (TRATAMENTO 2); RUN;
Note que esse procedimento possui SQL no nome. Para quem conhece a linguagem, vai reconhecer a sintaxe, pois é a mesma do SQL, acrescida de ‘PROC SQL’ e ‘RUN’.
Há uma série de procedimentos para obter algumas estatísticas da base, como o PROC MEANS, PROC FREQ, etc. Isso é abordado nos posts de Programação em SAS.
DATA STEP
Terminada a instalação e o entendimento do que são os comandos DATA e PROC, vamos começar construindo uma tabela para praticar. Na tabela abaixo, temos uma lista de clientes, cuja identificação se dá pelo campo id. Além da chave de identificação, temos a UF do cliente, a data em que o cadastro foi realizado e as respectivas idades:
/*Cria tabela exemplo*/
data tabela_exemplo;
input id $ uf $ dt_cadastro yyyymmdd. idade;
cards;
12531 SP 20170102 23
41456 SP 20180103 25
55564 GO 20180203 30
97943 PR 20171029 25
88712 PR 20150722 27
88712 SP 20140620 22
;
run;

Veja mais uma vez que para rodar um data step, você deve começar com Data + Nome da tabela que você vai criar, seguido por “;“.
Input com datalines serve para você inserir os dados manualmente. Após o input você deve colocar os nomes das suas variáveis e após o datalines os valores delas. Para finalizar, você deve utilizar o run.
Comentários são feitos utilizando uma barra seguida do asterisco e encerrados com asterisco seguido de uma barra. Ou então, e isto será mostrado nos próximos exemplos, com um asterisco e encerrado com ponto e vírgula.
Outro comando simples que é bastante utilizado e útil é o if, que pode servir tanto para filtrar quanto para executar um comando dada uma condição. Veja os exemplos abaixo:
* filtra clientes do parana; data tabela_pr; set tabela_exemplo; if uf = "PR"; run;

* se o cliente for de SP marca a fl_sp igual a 1; * caso contrario fl_sp igual a 0; data tabela_pr; set tabela_exemplo; if uf = "SP" then fl_sp = 1; else fl_sp = 0; run;

UTILIZANDO SQL DENTRO DO SAS
O SQL é a principal linguagem para manipular bases de dados. Como o SAS deve ser completo, fazendo com que o trabalho de ponta a ponta fique fácil para o usuário, é possível utilizar o SQL para fazer alterações nas bases. Para utilizá-lo, basta combinar o comando proc sql com os comandos tradicionais de SQL. No exemplo abaixo, selecionamos apenas os clientes com UF igual a SP:
proc sql; create table clientes_sp as select * from tabela_exemplo where uf = "SP" ; run;

Neste outro exemplo, tiramos a média das idades dos clientes:
proc sql; select mean(idade) as media_idade from tabela_exemplo ; run;
MUITO IMPORTANTE: TRABALHAR NA WORK x TRABALHAR NA LIBRARY
Os exemplos acima foram feitos trabalhando no que chamamos de WORK. O que quer dizer isso? Bem, quer dizer que ao fechar o SAS, você perderá esse trabalho. Claro que para uma análise rápida, você pode não querer salvar as tabelas geradas e por isso prefira trabalhar na WORK. No entanto, o mais comum é que você trabalhe numa biblioteca, na LIBRARY.
Na sua empresa, deve existir um servidor SAS que armazena todas as bases utilizadas. Para um analista de dados, alguém de modelagem estatística, não é necessário ter grande entendimento deste servidor, somente que ele funciona como um diretório qualquer do Windows, mas é armazenado num local específico sob os cuidados da área de TI.
Quando você quer salvar o arquivo numa library, há dois passos a serem feitos. Primeiro, você deve carregar a library executando uma simples linha de código que segue o padrão abaixo:
library nome_da_library "diretorio_da_library";
Em seguida, os exemplos acima devem ser mudados inserindo o nome da library antes do nome da base que está sendo carregada:
proc sql;
create table nome_da_library.clientes_sp as
select * from nome_da_library.tabela_exemplo
where uf = "SP" ;
run;
No exemplo acima, estamos trabalhando com uma base no caminho nome_da_library e estamos criando uma base nova neste mesmo caminho. Poderia ser diferente, poderíamos estar carregando a base de um caminho e salvando ela em outro:
library nome_da_library_1 "diretorio_da_library 1";
library nome_da_library_2 "diretorio_da_library 2";
proc sql;
create table nome_da_library_2.clientes_sp as
select * from nome_da_library_1.tabela_exemplo
where uf = "SP" ;
run;
Nesse último exemplo, nós carregamos uma base que estava localizada no caminho nome_da_library_1, fizemos um filtro nela e salvamos com um novo nome no caminho nome_da_library_2.
ATENÇÃO: É COMUM QUE INICANTES NO SAS AO COMETER ALGUM ERRO NO CÓDIGO PENSEM QUE, ASSIM COMO NO EXCEL, BASTA FECHAR O SOFTWARE SEM SALVAR QUE EM NADA IMPACTARÁ O QUE FOI FEITO. ISSO NÃO É INTEIRAMENTE VERDADE. VAMOS SUPOR QUE VOCÊ TENHA CRIADO UMA BASE NO CAMINHO NOME_DA_LIBRARY_2 CHAMADA CLIENTES_SP. PORÉM, NESSE MESMO CAMINHO JÁ EXISTIA UMA BASE COM ESSE NOME. VOCÊ IRÁ SOBRESCREVÊ-LA E NÃO TERÁ MAIS COMO RECUPERAR. CONSELHO DE AMIGO: NO COMEÇO, TRABALHE SOMENTE NA WORK E PERGUNTE AO SEU COLEGA MAIS SÊNIOR ONDE SALVAR O RESULTADO FINAL OU CRIE UMA LIBRARY SUA ONDE VOCÊ POSSA COMETER QUALQUER ERRO E NÃO ESTRAGUE NENHUMA BASE DA EMPRESA. SÉRIO, ESSE ERRO É MUITO COMUM, SE VOCÊ NÃO ENTENDEU, ME ESCREVA OU, EM ÚLTIMO CASO, FALE COM SEU COLEGA MAIS SÊNIOR “OLHA EU LI QUE POSSO ACABAR SOBRESCREVENDO UMA BASE NA BIBLIOTECA MAS EU NÃO ENTENDI DIREITO, ME AJUDA NISSO”.
Agora que você já sabe o básico, acesse Programação em SAS e pratique!
Avaliando intervenções: Variáveis Instrumentais
Já adiantando, esse post é para discutir alguns métodos econométricos. A discussão sobre o tema dos artigos utilizados não é relevante no contexto do post. Sugiro ainda a leitura do artigo Using Terror Alert Levels to Estimate the Effect of Police on Crime e do livro Freakonomics: O Lado Oculto e Inesperado de Tudo que nos Afeta (além dos que serão mencionados).
A polícia é bastante defendida e atacada pelas pessoas. De um lado os que acreditam na sua efetividade em combater o crime, do outro os mais céticos que acreditam que a polícia não é eficiente e é, muitas vezes, até pior para uma comunidade. Eu não estou aqui para discutir o que é certo e o que é errado, e sim mostrar como a estatística e a econometria são úteis na decisão de políticas que melhorem o bem estar geral e a não sermos enganados por qualquer correlação apresentada por aí.
Encontrar essa causalidade entre polícia e criminalidade não é fácil. Samuel Cameron, 1988, analisou 22 papers, desses, 18 indicavam uma relação positiva entre aumento policial e aumento de criminalidade ou então nenhuma relação. Nenhum conseguiu concluir que o aumento no número de policiais diminuía a criminalidade. Esses estudos, porém, não trataram o problema de endogeneidade. Endogeneidade ocorre quando seu erro e uma variável regressora estão correlacionados. Quando ela ocorre você não tem ideia de quem causa o que. E isso ocorre no nosso caso. Pense em um prefeito cuja cidade tem uma taxa de criminalidade alta. É bem provável que ele contrate mais policiais. Ou seja, muitos policiais em uma área de alta criminalidade, ou o contrário. Isso acaba enviesando nosso modelo.
E o que os estudos mais recentes nos dizem?
No artigo Panic on the Streets of London: Police, Crime, and the July 2005 Terror Attacks, Mirko Draca, Stephen Machin, and Robert Witt, utilizando diversas técnicas econométricas buscam explicar a causalidade entre policiamento e criminalidade.
Utilizando principalmente Difference in Differences eVariáveis Instrumentais, o paper analisa esse efeito utilizando o aumento do policiamento que ocorreu na Inglaterra após um ataque terrorista. É um material bem completo e uma análise cuidadosa, que considera efeitos de tendência (e se o bairro já estiver passando por uma redução de crimes?), teste de Placebo (análogo ao placebo quando falamos de remédios, mas para nossos grupos tratados) , dentre outras coisas.
Variáveis Instrumentais
Essa variáveis são utilizadas no estudo para lidar com o problema de endogeneidade que fazem com que nossos parâmetros de OLS sejam inconsistentes.
Para encontrar uma variável instrumental, precisamos de uma variável que impacta a variável resposta y através da variável explicativa x. Um exemplo famoso, citado no livro Mostly Harmless Econometrics, Angrist e Pischke, é de um estudo que buscava encontrar a relação entre anos de escolaridade e salário, que possuía a variável habilidade dentro do erro do modelo. A variável instrumental utilizada foi trimestre de nascimento, que impactava o salário, porém, através da variável escolaridade.
Para o estudo citado no início desse post, a variável encontrada foi o ataque terrorista. Note que essa variável de nada adiantaria para explicar a redução de criminalidade, porém, ao afetar o efetivo policial, ela acaba impactando a criminalidade. Essa é a intuição que eu acredito ser necessária para você entender o que é uma variável instrumental.
O resultado do estudo?
We find strong evidence that more police lead to reductions in what we refer to as susceptible crimes (i.e., those that are more likely to be prevented by police visibility, including street crimes like robberies and thefts)
Ou seja, eles conseguiram evidenciar, que o aumento no policiamento causa redução em crimes que eles chamam de “crimes suscetíveis”, que são os crimes que seriam mais visíveis aos policiais, como roubos, furtos e violência. Isso tudo mesmo com aquela correlação que observamos entre polícia e criminalidade.
Apenas para concluir, o modelo apresentado pelos autores demonstra que outros crimes, como os sexuais, não apresentaram diferenças significativas.
Leia também: Do Police Reduce Crime? Estimates Using the Allocation of Police Forces After a Terrorist Attack