Fazer um histograma no R é bem simples, basta utilizar o comando hist() com a variável que você quer investigar a distribuição. No entanto, um gráfico detalhado pode necessitar de mais detalhes, seja uma mudança na cor ou a apresentação das medidas de tendência central. Este post apresentará os detalhes que são possíveis de acrescentar no seu histograma utilizando o R.
Etiqueta: graficos
Análise Bidimensonal para Variáveis Quantitativas
Análise bidimensional (ou bivariada) é a análise de duas variáveis em conjunto. Quando utilizamos medidas resumo como média, mediana e variância (como no post Estatística Descritiva), estamos analisando a variável de forma isolada. Porém, em muitos casos, é interessante entender como as variáveis interagem entre si.
Gráficos no R com qqplot() (Histograma, Gráficos de Dispersão e Boxplot)
A função qqplot() do R – pertencente ao pacote ggplot2 – é uma das melhores para se fazer gráficos. Este post, sem muitas enrolações, é basicamente uma continuidade do Gráficos em R. Aqui vamos utilizar os dados da base Wage do pacote ISLR do R.
Para começar, apenas carregue os pacotes e visualize a base:
library(ggplot2); library(ISLR); View(Wage);
Como você pode ver, se trata de dados referentes a salário, escolaridade, saúde, etc.
Abaixo, você terá os códigos para gerar diferentes gráficos e comentários explicativos:
## Tracando grafico simples com qplot ## por default, temos um histograma bem simples qplot(wage, data=Wage);
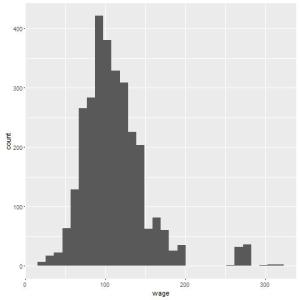
Você deve ter notado a mensagem: “`stat_bin()` using `bins = 30`. Pick better value with `binwidth`“. Isto quer dizer que por default, seu histograma é dividido em 30 barras diferentes, mas você pode escolher o melhor número de barras. Vamos testar com 15:
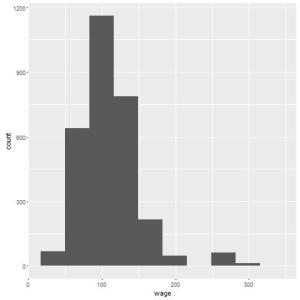
qplot(wage, data=Wage, bins=15);
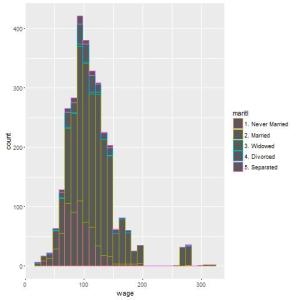
## Agora, vamos visualizar cada barra separando pelo estado civil qplot(wage, colour=maritl, data=Wage);
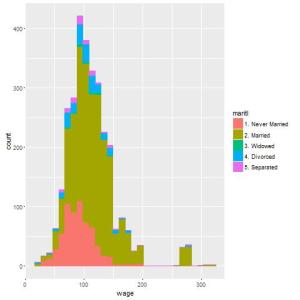
## Separar apenas com a cor do contorno nao ficou legal ## vamos trocar tambem a cor de preenchimento utilizando fill qplot(wage, colour=maritl, fill=maritl, data=Wage);
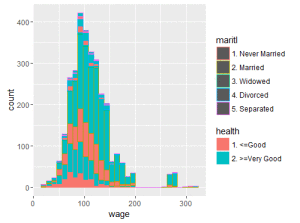
## Podemos inclusive preencher os blocos com cores diferentes ## Por exemplo, para cada estado civil, queremos ver quantos sao ## saudaveis e quantos nao sao qplot(wage, colour=maritl, fill=health, data=Wage);
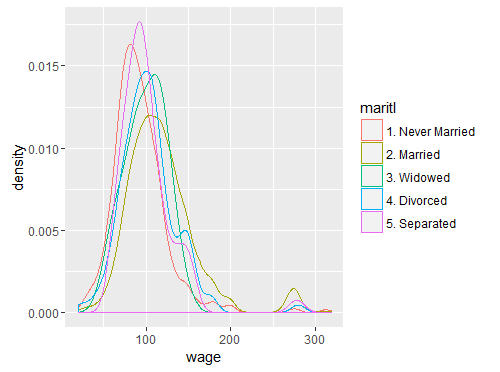
## Podemos visualizar graficos de densidade qplot(wage, colour=maritl, data=Wage, geom="density");
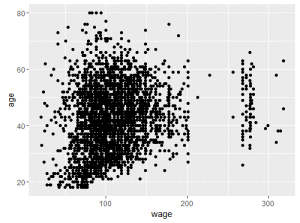
## Podemos tentar entender como duas variaveis interagem ## Exemplo: plotar salario vs idade qplot(wage, age, data=Wage);
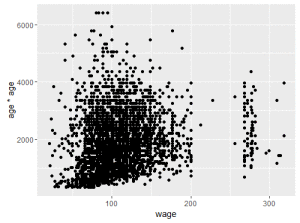
## Ou ate tentar ver alguma relacao nao linear qplot(wage, age*age, data=Wage);
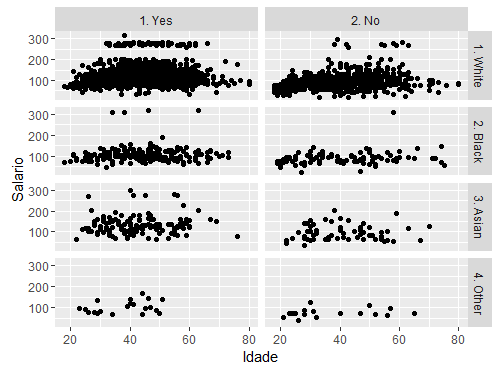
## Um pouco mais complexo, podemos verificar o comportamento de idade por salario ## para cada raca, dividindo ainda por pessoas que possuem ou nao plano de saude ## essa segunda divisao (raca por plano de saúde) eh feita utilizando facets qplot(age, wage, data=Wage, facets=race~health_ins, xlab="Idade", ylab="Salario");
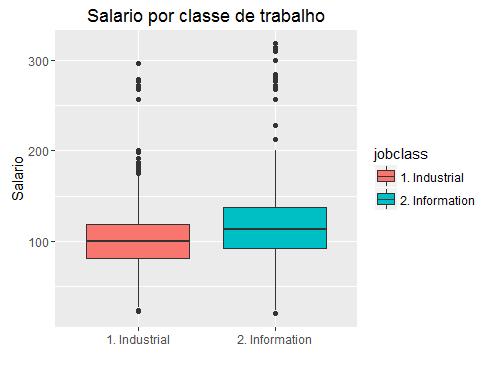
## Por fim, podemos fazer um boxplot, mas divindo uma variavel por
## cada uma das diferentes classes de uma outra (categorica)
## vamos observar o boxplot de salario para cada classe de trabalhador
## main indica o titulo do grafico, ylab o titulo do eixo y
qplot(jobclass, wage, data=Wage, geom=c("boxplot"),
fill=jobclass, main="Salario por classe de trabalho",
xlab="", ylab="Salario")
Agora você já está pronto para fazer diversos gráficos diferentes no R!
Personalizando seu gráfico do ggplot2 – Exports and Imports, William Playfair
O ggplot2 é muito bom para explorar visualmente, de forma dinâmica, sua base de dados. Mas às vezes queremos editar cada detalhe do gráfico para uma publicação, é possível fazer isso?
Leia o post completo em: Personalizando seu gráfico do ggplot2 – Exports and Imports, William Playfair
Gráficos em R
Visualizando seus dados: Gráficos de Dispersão
Outra forma de fazer uma primeira análise dos seus dados é plotar um gráfico de dispersão.
Um gráfico de dispersão é uma representação dos seus dados em eixos onde um valor está em função de outro. Normalmente, esses gráficos possuem dois eixos, um eixo horizontal (eixo x) e um eixo vertical (eixo y) onde cada eixo serve como referência para cada um dos valores do seu par.
Vamos ver na prática como funciona!
Tomando os mesmos dados que tínhamos das notas dos alunos utilizadas no post sobre histogramas, vamos agora verificar a relação entre o número de faltas dos alunos e suas notas:

Agora, queremos ter uma ideia de como essas variáveis se relacionam. Talvez a gente consiga ter uma ideia do comportamento, afinal, é provável que quem falte mais tenha piores notas. Poderemos ver isso com o gráfico de dispersão. Vejamos as diferentes formas de se gerar esse tipo de gráfico utilizando o SAS:
SYMBOL1 V=circle C=black I=none;
TITLE 'Notas x Faltas 1';
PROC GPLOT DATA=auto;
PLOT Notas*Faltas;
RUN;

SYMBOL1 V=circle C=blue I=r;
TITLE 'Notas x Faltas 2';
PROC GPLOT DATA=auto;
PLOT Notas*Faltas;
RUN;
QUIT;

Como vocês podem notar, SYMBOL é responsável por especificar as características do seu gráfico, sendo que V define o formato, no meu caso usei círculos, mas poderia ser Plus (+), Dot (•), dentre muitos outros. C define a cor e I o que chamamos de interpol nos traz a reta da regressão. Experimente modificar essas características no seu gráfico!
Quando se trabalha com gráfico de dispersão, fica mais claro a correlação entre as duas variáveis em questão. Você vai ver que por si só, esse gráfico já será muito útil na vida profissional e acadêmica. E claro, se você quiser ir além, esse gráfico é um começo para suas análises e regressões!
Visualizando seus dados: Histograma
Um histograma nada mais é do que uma forma de representar seus dados utilizando um gráfico de barras onde o eixo y representa a frequência e o eixo x os intervalos (chamados também de classes) dos seus dados. Simples assim. E já para dar uma ideia antes mesmo das definições mais formais, veja esse exemplo de um conjunto de dados e um histograma executado automaticamente pelo excel (veja o passo a passo no Canal da Educação):

Só de bater o olho, acho que a maioria já consegue entender o que o histograma apresenta. Ele nos dá uma ideia de como nossos dados estão distribuídos, mas para isso ele separa nossos dados em classes, ou, como o excel chamou, em blocos. Veja o que o excel fez, ele separou nossos dados em 5 intervalos:
Menor ou igual a 1, maior que 1 e menor ou igual a 25, maior que 25 e menor ou igual a 49, maior que 49 e menor ou igual a 73 e um último intervalo como sendo os números acima de 73. Para cada intervalo, ele contou o número de elementos dos nossos dados que fazem parte do intervalo em questão e a partir daí fez o gráfico de barras.
Quantos números do nosso conjunto de dados são menores ou iguais a 1? Apenas 1. Quantos são maiores que 1 e menor ou igual a 25? Apenas 6.
Eu não sou fã desse histograma do excel por achar pouco intuitivo os pontos 1, 25, 49, 73 e “Mais” estarem localizados no meio da barra mas não serem o ponto médio do intervalo. É bom se atentar a isso. Mas, deixando a crítica de lado e voltando ao assunto…
Nesse gráfico, o excel nos devolveu o resultado em termos da frequência absoluta, que nada mais é que o número de vezes em que determinado dado aparece. O histograma também pode ser construído com base na frequência relativa, que é o número de vezes em que determinado dado aparece dividido pelo número de elementos da nossa amostra ou população. Em outras palavras, é a representação percentual. Veja esse exemplo com os mesmos dados, mas utilizando a frequência relativa:

E NO SAS? COMO FAZEMOS UM HISTOGRAMA
A forma mais rápida que eu conheço é pelo proc univariate, é bem simples. Basta acrescentar histogram logo após você selecionar as variáveis que deseja visualizar o histograma. No exemplo abaixo, vamos inserir através do Datalines a data e o índice Ibovespa (índice na abertura, alta, baixa, etc.) e em seguida utilizamos o proc univariate para gerar o histograma:
data dados;
input notas;
datalines;
3.6
3.6
5
6.4
6.6
6.6
6.8
7.5
8
8.7
9
9.5
;
proc print;
run;
proc univariate data = dados;
var notas;
histogram;
run;

Veja que o SAS criou seus intervalos também.
E se eu quiser alterar a forma como as classes estão divididas?
Bom, nesse caso podemos usar tanto o endpoints como o midpoints e escolher o intervalo inferior de todas as classes, o superior, e qual tamanho de cada classe. Veja esse exemplo com midpoints e tente brincar depois com endpoints:
proc univariate data = dados; var notas; histogram / midpoints=(3 to 10 by 2) ; run;
