Hoje vamos aprender algumas coisas que podem ser feitas quando se trabalha com dataframes no Python. Como filtrar uma base? Como converter textos para números? Como extrair um valor de moeda no formato texto para o formato numérico? Como obter as estatísticas descritivas? Como criar novas colunas? Como traçar um histograma? Como localizar valores nulos e preenchê-los com a média da coluna? Tudo isso e muito mais no post abaixo! Continuar a ler “Tutorial: Limpeza e Análise de Dados com Python”
Etiqueta: mediana
Proc Means
No SAS, uma das melhores formas de se obter estatísticas descritivas é através do proc means. Além de ser possível obter média, mediana e moda, você consegue diferentes faixas de percentil, observações missing e até mesmo gerar estatísticas cruzando variáveis.
Veja algumas maneiras de se utilizar o proc means com a nossa conhecida base german_credit_2:
1. Primeiro, vamos obter algumas informações para a variável DurationOfCreditMonth utilizando o proc means da maneira mais simples possível:
proc means data= german_credit_21; var DurationOfCreditMonth; run;
2. Em alguns momentos você pode precisar gerar as informações segregadas por diferentes grupos. Por exemplo, você pode precisar da mediana da dívida dos clientes por cada estado, ou a média das notas dos alunos por matéria. Em nosso exemplo, vamos observar como a variável DurationOfCreditMonth se diferencia entre clientes com Creditability = 1 e Creditability = 0:
proc means data=tmp.german_credit_21; class Creditability; var DurationOfCreditMonth; run;
3. Média, mediana e desvio padrão são medidas interessantes e auxiliam na interpretação dos números. No entanto, você pode estar interessado em entender mais a respeito da distribuição desses números. Uma forma de entender isso, é através de algum percentil:
proc means n mean std p10 p25 p50 p75 data=tmp.german_credit_21; class Creditability; var DurationOfCreditMonth; run;
4. Agora que você já possui alguns números para entender melhor a variável, pode ser uma boa ideia deixar o seu resultado mais limpo limitando a duas casas decimais com o maxdec:
proc means n mean std skew p10 p25 p50 p75 data=tmp.german_credit_21 maxdec=2; class Creditability; var DurationOfCreditMonth; run;
5. Não é tão interessante quanto os primeiros itens, mas salvar seus resultados em uma tabela – que aqui chamamos de tabela_saida – pode ser útil, principalmente em processos mais automáticos:
proc means data=tmp.german_credit_21; class Creditability; var DurationOfCreditMonth; output out=tabela_saida sum=soma mean=media p50=mediana; run;
6. Outra coisa que podemos fazer, semelhante ao que fizemos no item 2, é gerar essas medidas para mais variáveis dividindo todas pelo Creditability ou então, gerar as medidas da variável por outras classes:
proc means data=tmp.german_credit_21; class Creditability; var DurationOfCreditMonth Purpose; output out=tabela_saida sum=soma mean=media p50=mediana; run;
proc means data=tmp.german_credit_21; class Creditability Purpose; var DurationOfCreditMonth; output out=tabela_saida sum=soma mean=media p50=mediana; run;
BÔNUS:
Para incluir os dados missing e ainda contar o número de observações missing, acrescente missing e nmiss no proc means:
proc means data= <nome da base> missing nmiss; class <classe - nao obrigatorio>; var <variavel>; run;
Estatística Descritiva
Estatística descritiva, como o próprio nome já diz, é uma disciplina (ramo, técnica, etc.), que utilizamos para descrever dados de forma quantitativa.
Quando você está no excel e vai em análise de dados, você pode selecionar estatística descritiva e marcar a caixinha “resumo estatístico” para obter diversas informações a respeito dos seus dados. Farei aqui um breve resumo do que é cada uma das principais estatísticas fornecida pelo Excel.
Antes, vamos lembrar algumas definições básicas.
A média, mediana e moda, são chamadas de medidas de tendência central. Como o próprio nome diz, elas fazem referência ao centro da nossa distribuição. Ou seja, onde nossos dados estão centrados, qual o “meio” da nossa distribuição.
Em contrapartida, mediana, variância e desvio padrão são medidas de dispersão. Servem para mostrar o quanto nossos dados estão dispersos.
Por exemplo, suponha que a gente tenha duas cidades, A e B, com 10 moradores cada e com os seguintes salários:
Cidade A: $200, $200, $200, $200, $200, $200, $200, $200, $200, $200;
Cidade B: $10, $10, $10, $10, $10, $100, $100, $100, $100, $1550.
A média da cidade A e da cidade B é $200, mas o desvio padrão da cidade A é 0 e da cidade B é 451,99. Ou seja, os dados da cidade B estão bem mais dispersos. Podemos ver que os salários na cidade A são bem distribuídos, enquanto na cidade B há uma diferença significante entre os salários. Por esse motivo, é importante conhecermos tanto as medidas de tendência central, quanto as medidas de dispersão.
Vejamos agora as principais estatísticas fornecidas pelo Excel e o que significa cada uma:
- Média: Média aritmética da sua amostra, provavelmente a estatística mais conhecida e utilizada por todos, imagino que não precise de muita explicação. Nada mais é do que a soma das suas observações dividido pelo número de observações.
- Erro padrão: Estima a variabilidade de suas amostras, sua fórmula é o desvio padrão dividido pelo tamanho da amostra.
- Mediana: Valor que está no centro da sua amostra, metade dos valores está acima deste número e metade abaixo. Na cidade A a mediana é 200 e na cidade B é 55, pois (10+100)/2 = 55.
- Moda: Valor que aparece mais vezes nos seus dados. Na cidade A a moda é 200 e na cidade B é 10.
- Desvio padrão: Mede o quanto seus dados variam com relação a média.
- Variância: Essa medida vai te dar a dispersão dos seus dados com relação a média, mas em uma dimensão que será o quadrado da dimensão dos seus dados.
- Curtose: Também é uma medida para indicar a dispersão dos seus dados, mas nesse caso, a estatística nos dará o quão achatado é o gráfico da função de probabilidade dos nossos dados. Falaremos mais dessa medida em um post futuro, por enquanto, ficamos com a definição mais básica de que uma Curtose próxima de zero indica uma distribuição normal.
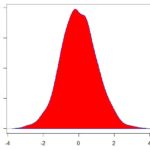
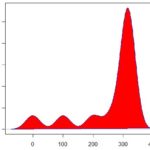
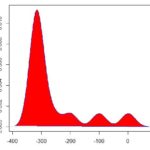
- Assimetria: Nos dá a simetria da distribuição dos nossos dados. Como assim? Bem, se você desenhar a curva de distribuição dos seus dados, você pode ter algo parecido com uma normal, uma curva um pouco mais concentrada a direita e caindo quando vai para a esquerda, ou o contrário. É isso que a essa medida do excel nos ajuda a entender. Uma distribuição simétrica, que tem o formato de um sino, terá assimetria igual a 0. No entanto, se a distribuição possuir uma maior concentração de dados a esquerda, o valor dessa estatística será negativo.