Uma pergunta que eu já ouvi bastante é: como fazer um loop no SAS? Essa pergunta vale para qualquer linguagem, é uma das coisas mais utilizadas e até agora não tinha escrito nada sobre o tema.
Etiqueta: SAS
Tratando Duplicidades no SAS
É comum encontrar campos duplicados em uma tabela. Seja porque algum join ou agrupamento que poderia ter sido melhor realizado (mesmo não trazendo informações erradas), por causa de algum erro de inserção da informação ou qualquer outra coisa. No SAS, há algumas maneiras práticas de tratar esse erro. Aqui você vai aprender a ordenar sua tabela com PROC SORT, exluir duplicidades com NODUPKEY, gerar uma tabela com os valores que estavam duplicados utilizando DUPOUT e excluir duplicidades por todos os campos com BY _ALL_.
Soma com condição no SAS: Agrupamentos com Proc Sql
O group by é um método bem tranquilo de agrupar os valores de uma coluna de acordo com os valores de outra coluna. Veja os três exemplos abaixo, onde queremos primeiro saber qual o número de vendas de cada marca, o número de vendas por estado e o número de vendas de cada marca em cada estado:
Acompanhando a execução da macro no SAS
Mostrei no post Acompanhando o processo no SAS utilizando o Sysecho como utilizar o comando sysecho para acompanhar um procedimento extenso, algo que leva muito tempo para ser executado ou com muitas etapas. Porém, seria interessante também fazer um acompanhamento parecido quando executamos uma macro.
Convertendo diferentes formatos de data no SAS
Essa é intuitiva, mas não sei se todo mundo conhece. Então, se você leu Como calcular a diferença entre duas datas no SAS? e Formatando Datas no SAS, agora que já conseguiu criar colunas e mudar formato numérico para data, pode ainda querer trocar aquela data 20DEC2016 para 20/12/2016. Isso pode ser feito com o format:
*codigo que pega a tabela_old, com o campo data no formato 20DEC2016; *e cria uma tabela nova chamada tabela_new com a data no formato 20/12/2016; data tabela_new; set tabela_old; format data ddmmyy10.; run;
Proc Sort no R
Muita gente sabe utilizar o proc sort para ordenar os campos no SAS.
Por exemplo, podemos ordenar uma tabela chamada dados_entrada pelas colunas campo1 e campo2, do menor para o maior valor, e ter como saída uma tabela dados_saida (exemplo 1). E podemos também ordenar uma tabela chamada dados_entrada pelas colunas campo1, do menor para o maior, e campo2, do maior para o menor valor, e ter como saída uma tabela dados_saida (exemplo 2). Bastaria utilizar:
* exemplo 1
proc sort data= dados_entrada out= dados_saida;
by campo1 campo2;
run;
* exemplo 2
proc sort data= dados_entrada out= dados_saida;
by campo1 descending campo2;
run;
A mesma coisa, que nem todo mundo sabe, pode ser feita no R, e é até mais simples:
## exemplo 1 dados_saida = dados_entrada[order(dados_entrada$campo1, dados_entrada$campo2),]; ## exemplo 2 dados_saida = dados_entrada[order(dados_entrada$campo1, -dados_entrada$campo2),];
R sendo R!
Gerar amostras aleatórias simples no SAS
Em diversos estudos estatísticos, seja para fazer uma pesquisa de mercado ou um modelo estatístico, é necessário gerar uma amostra aleatória. No SAS, isso é bem simples:
/*Substitua os nomes: tabela_entrada, amostra_gerada *\ /* e tamanho_da_amostra *\ proc surveyselect data= tabela_entrada out= amostra_gerada n = tamanho_da_amostra method=SRS; run;
Ps.: As amostras são sem reposição!
Empilhando bases no SQL
Mais um post rápido, em que o título fala por si só.
Primeiro, uma query que vai unir as duas tabelas, removendo duplicidades:
select * from table1 union select * from table2
Query que vai unir as duas tabelas, sem remover duplicidades. Ou seja, se tivermos todas as colunas idênticas, a tabela final terá linhas idênticas:
select * from table1 union all select * from table2
Lembrando que o SQL pode ser utilizado no SAS, contanto que você inicie com um proc sql!
SAS: Executando diversos códigos em um só com o include
Assim como é possível chamar outros códigos no R e utilizar algumas funções prontas, no SAS algo semelhante pode ser feito declarando INCLUDE.
Quando você utiliza o include seguido de um caminho com um programa SAS, o que vai acontecer é que esse programa será executado. Sendo assim, você pode rodar diversos códigos em um projeto só, pode consolidar as suas libnames em um lugar só, enfim, há várias alternativas, todas com o include.
Uma situação hipotética: sua empresa possui uma base padrão, dentro de um DW qualquer, com um campo de data no formato string “ddmmaaaa”. Vamos supor que você tenha criado um projeto no qual um dos programas seja uma macro, denominada trata_data, que recebe a base padrão e converte o campo string para o formato data padrão do SAS. Você utilizou essa macro nesse projeto, mas ela é pode ser útil em vários outros estudos. O que você pode fazer é salvar essa macro como um programa em um diretório e quando você precisar utilizá-la em outro código, você utilizará algo como a sintaxe:
*chama a macro que tratara a data da base padrao (base_in) *e gera uma base com campo tratado (base_out); %include '/sasdata/minhaempresa/macro_trata_data.sas'; %trata_data(base_in, base_out);
Outra forma de utilizar o include é na automatização de alguns processos. Vamos supor que você tenha criado um modelo estatístico que gera o rating das empresas clientes do seu banco e você deseja automatizar o processo de geração de rating para várias bases diferentes que chegarão mensalmente. Para isso, você pode criar diversos programas que receberão algumas variáveis, como a base de entrada e uma base de cadastro que enriquecerá a base de entrada, e rodá-los todos com o include. O exemplo abaixo pressupõe um programa chamado gera_rating_empresa.sas e dentro desse programa você possui duas variáveis/bases que devem ser passadas pelo usuário chamadas base_in e base_endereco (lembre-se que no programa elas precisam ser chamadas com &base_in e &base_endereco):
*insira o nome da base de entrada com campo CNPJ com 14 dígitos (string); %let base_in = base_entrada_yyyymmdd; *passe a base que enriquecera com as informacoes de endereco; %let base_endereco = base_endereco_yyyymmdd; *execute o programa; %include "/sasdata/.../gera_rating_empresa.sas";
Não se esqueça de ficar craque em macros / let: Macros e a expressão Let no SAS
Excluindo linhas de um dataset no R
Mais uma dica rápida que saiu enquanto eu fazia minha tese…
Estava tratando um conjunto de dados no R, quando vi que precisava excluir as linhas que tivessem o campo referente ao mês com valor igual a 1 ou igual a 5. Sempre fiz isso no SAS com um if bem simples, mas não lembrava no R, talvez já tenha feito aqui, mas quem lê o blog sabe que não é lá tão organizado. Enfim, a lógica no R é tão simples quanto a do SAS, mas não tão intuitiva (ao menos para mim). Veja o antes e depois de uma tabela chamada dados retirando as linhas nas quais o campo mês seja igual a 1 ou 5 e quais os códigos utilizar em algumas linguagens que já mencionamos aqui (é tão simples que vou colocar tudo junto mesmo):
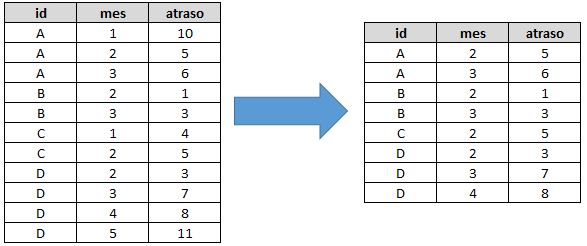
No R, podemos resolver com um indexador lógico (! indicando negação):
dados[(dados$mes!=5 & dados$mes!=1),];
Ou então com um subset:
subset(dados, mes != 1 & mes != 5)
Da forma que escrevemos acima, você vai obter uma nova tabela, mas ela não está sendo salva com nome algum. Se você quiser, pode facilmente criar uma nova, como a tabela_nova que criamos no exemplo a seguir:
tabela_nova = subset(dados, mes!=1 & mes !=5)
Se você quiser ver como é no SAS, aqui vai um exemplo com data step:
data dados_v2;
set dados;
if mes ne 1 and mes ne 5; *ou if mes <> 1;
run;
E agora, um exemplo com proc sql:
PROC SQL;
CREATE TABLE dados_v2 AS
SELECT * FROM dados WHERE mes <> 1 AND mes <> 5;
RUN;
Se quiser fazer no SQL:
SELECT * FROM dados WHERE mes <> 1 and mes <> 5;
E aí, curtiu o post?
E aí? Gostou do conteúdo? Se inscreva para receber todas as novidades. Deixe seu e-mail em INSCREVA-SE na barra à direita, logo abaixo de pesquisar. E, por favor, não deixe de comentar, dar seu feedback e, principalmente, compartilhar com seus amigos. De verdade, isso faz toda a diferença. Além disso, você também pode acompanhar mais do meu trabalho seguindo a conta de Twitter @UniDosDados, no Instagram @universidadedosdados ou por alguma das redes que você encontra em Sobre o Estatsite / Contato, como meu canal de Youtube Canal Universidade dos Dados.
Aproveite e adquira sua camiseta de data science na LOJA DA UNIVERSIDADE DOS DADOS. Vai ficar estiloso e me ajudar neste projeto!
BONS ESTUDOS!