Novamente, as formatações atrapalhando nossa vida. Quem nunca recebeu uma base em que o campo estava mal formatado, muitas das vezes o número apareceu no formato texto. No SQL é fácil de resolver isso, use a função CAST(): Continuar a ler “Como converter de string para número no SQL”
Etiqueta: sql
Como Agrupar os Dados por Semana no SQL
Agora que já mostramos como agrupar os dados por um determinado grupo utilizando o group by, vamos ver como fazer um agrupamento para mostrar os dados semana a semana. Continuar a ler “Como Agrupar os Dados por Semana no SQL”
Group By no SQL
Imagine que você tenha a informação de renda dos clientes das suas lojas ao redor do Brasil. Seria interessante saber qual a renda média da sua base de clientes, claro. Mas talvez fosse mais interessante ainda saber a renda média de clientes por estado. Para fazer isso, sumarização da informação por um determinado grupo, você precisa conhecer o famoso GROUP BY. O Group By serve para fazer exatamente o que o nome diz: “agrupar por” algum campo. Imagine que você tenha uma coluna com valores de alguma variável. Você quer agrupar essa variável de alguma forma, seja fazendo uma soma ou calculando a média. Porém, você tem a necessidade de agrupar por alguma outra variável. É aí que entra o group by. Vamos ver um exemplo para facilitar. Primeiro, criamos uma tabela para trabalharmos o exemplo. Vamos criar uma tabela já bastante manjada por quem acompanha o site, as compras que os clientes fizeram em uma determinada loja:
-- exclui tabela caso ela exista
drop table base_compras;
-- cria os campos da tabela
CREATE TABLE base_compras (
Id int,
Nome varchar(50),
Sobrenome varchar(50),
Estado varchar(2),
Gastos decimal,
Data_Compra date
);
-- insere valores na tabela
INSERT INTO base_compras
VALUES
(152, 'Andre', 'Silva', 'MG', 351.50, '2018-01-22'),
(222, 'Barbara', 'Toledo', 'SP', 250.10, '2018-05-15'),
(451, 'Carlos', 'Pinheiro', 'MG', 455.00, '2017-02-05'),
(754, 'Eduardo', 'Silva', 'SP', 390.10, '2018-04-10'),
(897, 'Juliana', 'Oliveira', 'MG', 150.50, '2017-03-01'),
(852, 'Maria', 'Lima', 'MG', 325.90, '2018-05-30'),
(997, 'Ricardo', 'Pereira', 'MG', 332.59, '2018-05-25'),
(535, 'Vanessa', 'Costa', 'SP', 241.57, '2017-04-30');
-- visualiza tabela
select * from base_compras;
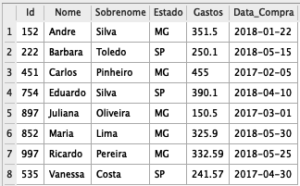 Primeiro, eu coloco um drop table no início do código, pois sempre que ele for rodar, ele exclui a tabela antiga que possui o nome base_compras. No SQL, se você tentar criar uma tabela e já existir outra com mesmo nome, ele retorna um erro. Por esse motivo, eu costumo adicionar um drop table antes de um create table.
Primeiro, eu coloco um drop table no início do código, pois sempre que ele for rodar, ele exclui a tabela antiga que possui o nome base_compras. No SQL, se você tentar criar uma tabela e já existir outra com mesmo nome, ele retorna um erro. Por esse motivo, eu costumo adicionar um drop table antes de um create table. Agora que temos a base, vamos tentar resumir as informações por estado. Vamos obter a média e a soma dos gastos por cada estado:
-- sumariza os gastos por Estado
select estado,
sum(gastos) as gasto_total,
avg(gastos) as media_gastos
from base_compras
group by 1
order by 1;
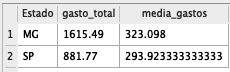
Note que a lógica é bem simples. Primeiro, selecionamos o que queremos: o estado (que será o objeto pelo qual as outras informações serão agrupadas), a soma de gastos (que denominamos “gasto_total”) e a média dos gastos (denominada media_gastos). Por fim, agrupamos e ordenamos pelo primeiro item selecionado: o estado. Poderíamos fazer a mesma coisa, mas utilizando o nome do campo:
-- sumariza os gastos por Estado
select estado,
sum(gastos) as gasto_total,
avg(gastos) as media_gastos
from base_compras
group by estado
order by estado;
Você poderia ordenar por mais campos também. Vamos ver um exemplo um pouquinho mais complexo (mas bem pouco).
Como estou trabalhando no SQLite, não consigo utilizar as funções mais simples para lidar com data, como por exemplo year(), month(), day(). Por isso, apenas para que vocês entendam como funciona, vou demonstrar o que faz a função strftime():
select strftime('%Y', Data_Compra) from base_compras
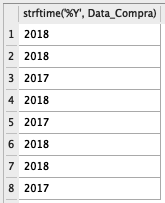
Veja que ela extrai a informação de ano da variável Data_Compra. Eu fiz isso porque agora nós vamos obter a média e a soma dos gastos agrupados por Estado e por Ano. Ou seja, veremos a média dos gastos dos clientes de MG no ano de 2017 e a média no ano de 2018. O mesmo para SP.
select estado,
strftime("%Y", Data_Compra) as Ano,
sum(gastos) as gasto_total,
avg(gastos) as media_gastos
from base_compras
group by 1,2
order by 1,2;
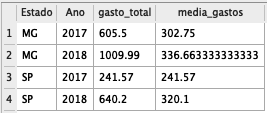
Viu que simples? Agora você pode fazer resumos dos seus dados de uma forma bem mais completa.
Gostou do post? Veja mais de SQL em Programação em SQL. Além disso, se restou alguma dúvida, ou se você tem alguma crítica, comentário ou sugestão, entre em contato deixando um comentário ou escrevendo através do contato deixado em Sobre o Estatsite / Contato.
Caso tenha interesse em obter mais conteúdos de Data Science, você pode acompanhar o @EstatSite.
Introdução ao SQL
SQL (Structured Query Language) é a linguagem padrão utilizada para armazenar, manipular e recuperar informações de bancos de dados. Colocando de forma simples, é através do SQL que é possível criar e atualizar nossos dados através de um modelo relacional. Os maiores usuários da linguagem são os DBAs (Database Administrators), responsáveis por toda a gestão dos dados, desde criar tabelas até dar acesso às demais áreas (para os mais curiosos há um podcast brasileiro com foco nos DBAs chamado DatabaseCast).
Charada de SQL
Esse é um tipo de “pegadinha” comum em entrevistas e que mesmo no dia a dia confunde algumas pessoas na hora de tratar os dados. Seja para surpreender o entrevistador ou para resolver rápido os problemas, você precisa ter a resposta na ponta da língua.
Empilhando bases no SQL
Mais um post rápido, em que o título fala por si só.
Primeiro, uma query que vai unir as duas tabelas, removendo duplicidades:
select * from table1 union select * from table2
Query que vai unir as duas tabelas, sem remover duplicidades. Ou seja, se tivermos todas as colunas idênticas, a tabela final terá linhas idênticas:
select * from table1 union all select * from table2
Lembrando que o SQL pode ser utilizado no SAS, contanto que você inicie com um proc sql!
Excluindo linhas de um dataset no R
Mais uma dica rápida que saiu enquanto eu fazia minha tese…
Estava tratando um conjunto de dados no R, quando vi que precisava excluir as linhas que tivessem o campo referente ao mês com valor igual a 1 ou igual a 5. Sempre fiz isso no SAS com um if bem simples, mas não lembrava no R, talvez já tenha feito aqui, mas quem lê o blog sabe que não é lá tão organizado. Enfim, a lógica no R é tão simples quanto a do SAS, mas não tão intuitiva (ao menos para mim). Veja o antes e depois de uma tabela chamada dados retirando as linhas nas quais o campo mês seja igual a 1 ou 5 e quais os códigos utilizar em algumas linguagens que já mencionamos aqui (é tão simples que vou colocar tudo junto mesmo):
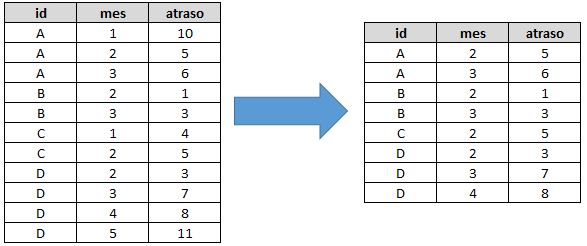
No R, podemos resolver com um indexador lógico (! indicando negação):
dados[(dados$mes!=5 & dados$mes!=1),];
Ou então com um subset:
subset(dados, mes != 1 & mes != 5)
Da forma que escrevemos acima, você vai obter uma nova tabela, mas ela não está sendo salva com nome algum. Se você quiser, pode facilmente criar uma nova, como a tabela_nova que criamos no exemplo a seguir:
tabela_nova = subset(dados, mes!=1 & mes !=5)
Se você quiser ver como é no SAS, aqui vai um exemplo com data step:
data dados_v2;
set dados;
if mes ne 1 and mes ne 5; *ou if mes <> 1;
run;
E agora, um exemplo com proc sql:
PROC SQL;
CREATE TABLE dados_v2 AS
SELECT * FROM dados WHERE mes <> 1 AND mes <> 5;
RUN;
Se quiser fazer no SQL:
SELECT * FROM dados WHERE mes <> 1 and mes <> 5;
E aí, curtiu o post?
E aí? Gostou do conteúdo? Se inscreva para receber todas as novidades. Deixe seu e-mail em INSCREVA-SE na barra à direita, logo abaixo de pesquisar. E, por favor, não deixe de comentar, dar seu feedback e, principalmente, compartilhar com seus amigos. De verdade, isso faz toda a diferença. Além disso, você também pode acompanhar mais do meu trabalho seguindo a conta de Twitter @UniDosDados, no Instagram @universidadedosdados ou por alguma das redes que você encontra em Sobre o Estatsite / Contato, como meu canal de Youtube Canal Universidade dos Dados.
Aproveite e adquira sua camiseta de data science na LOJA DA UNIVERSIDADE DOS DADOS. Vai ficar estiloso e me ajudar neste projeto!
BONS ESTUDOS!
SQL dentro do SAS
O SQL é uma linguagem utilizada comumente na manipulação de dados. É bastante intuitiva e fácil de utilizar. Para selecionar, por exemplo, uma coluna denominada Nome contendo os nomes de clientes da tabela XYZ, o comando a ser utilizado é praticamente a frase “selecionar nome da tabela XYZ”, mas em inglês:
SELECT Nome from tabela XYZ
Ou então, você pode selecionar todas as colunas da base XYZ com o comando ‘*’:
SELECT * from tabela XYZ
Como você pode ver, é bem intuitivo.
O SQL é uma das linguagens embutidas no SAS e você pode acioná-la utilizando o comando proc sql seguido pelo tradicional ponto e vírgula e finalizá-lo com o comando run do SAS. Para você ver como pouco muda, o comando de SQL utilizado acima ficaria da seguinte forma no SAS:
proc sql; select * from tabela XYZ; run;
Caso você já acompanhe o blog, ou tenha lido alguns outros códigos, você deve ver muitas vezes ao invés do asterisco sozinho, algo como a.*. Isso ocorre porque quando temos duas tabelas, nós as denominamos de ‘a ‘e ‘b’ (ou t1, t2, etc.), sendo assim você precisa mencionar de qual tabela você está selecionando a coluna. O código acima, caso quiséssemos chamar a tabela XYZ de ‘a‘, ficaria da seguinte forma:
proc sql; select a.* from tabela XYZ as a; run;
Veja que para uma tabela só não tem muita diferença, mas imagine com duas ou três como já complicaria escrever simplesmente select Nome. Se o SAS pudesse falar, ele diria: seleciono de onde? De XYZ ou das outras tabelas?
Veja que a linguagem de SQL embutida no SAS facilita bastante a manipulação dos dados e fornece aos usuários alternativas quando a lógica com o data step for mais complicada.
Como o código acima vai apenas mostrar para você a seleção feita, para utilizarmos a informação gerada dentro do próprio SAS podemos criar uma tabela. E, novamente, o código é uma mera tradução do inglês: Create Table:
proc sql; create table Tabela_Nomes as select Nome from tabela XYZ; run;
Vamos utilizar a tabela abaixo com algumas pessoas, a renda que elas possuem e a origem dessa renda, para demonstrar outros comandos utilizados no proc sql:

Os principais comandos a serem lembrados no SQL, além do select, são:
- Where: Um tipo de filtro, semelhante ao if. Vamos supor que a base contenha a coluna renda com o salário dos clientes e você queira apenas o nome de quem possui renda superior a mil reais. Agora, você terá que selecionar duas colunas, Nome e Renda, e a tabela com esses clientes seria criada da seguinte forma:
proc sql; create table Tabela_Renda as select id, Nome, Renda from tabela_exemplo where renda > 1000; run;

- Group by: Serve para agrupar os dados por algum campo em comum. Vamos pensar agora nos clientes que possuem várias fontes de renda, aquela pessoa que além do salário da empresa também possui rendas com aluguéis ou trabalhos de freelancer. Sendo assim, a base terá várias linhas com rendas diferentes para esse cliente. Se você quiser a renda total dele, você terá que somar essas rendas diferentes e agrupar pelo nome:
proc sql; create table Tabela_Renda_Cliente as select id, Nome, sum(Renda) as Renda_Total from tabela_exemplo group by id, nome having Renda_Total > 1000; run;

- Having : Bem semelhante ao where, é utilizado para o filtro depois de alguma tratativa. Como queríamos selecionar os clientes com renda acima de mil reais, e com o where só considerávamos a renda de um emprego, agora podemos filtrar os clientes com renda total acima de mil reais utilizando o having:
proc sql; create table Tabela_Renda_Cliente_2 as select id, Nome, sum(Renda) as Renda_Total from tabela_exemplo group by id, nome having Renda_Total > 1000; run;

Order By: Ordena a tabela de acordo com algum campo, na ordem crescente.
Poderíamos ter gerado a renda dos clientes, mas ordenando pela renda:
proc sql; create table Tabela_Renda_Cliente_3 as select id, Nome, sum(Renda) as Renda_Total from tabela_exemplo group by id, nome having Renda_Total > 1000 order by Renda_Total; Run;

Pratique SQL !
Escrevi bastante sobre SQL esses dias, quem quiser praticar e não tiver em casa, ou não quiser instalar nenhuma versão, você pode utilizar no seu browser com o link abaixo:
SQL Fiddle
Veja que na tela da esquerda você já tem uma construção da tabela localizado ao final da tela e do lado direito você pode escrever diversas queries e executá-las com o botão RUN SQL. Vamos praticar!