É possível fazer excelentes análises exploratórias no Python. Na última live que fiz no meu canal da Twitch, www.twitch.tv/yukiolive, mostrei algumas funcionalidades do Matplotlib e Seaborn. Como fazer gráficos de dispersão, de barras, como alterar os eixos, alterar o tamanho da figura utilizando plt.figure(), alterar o título (incluindo o tamanho e cor da fonte), dentre outras tantas coisas. Caso você não tenha assistido a live, fica o convite. E se você tiver interesse em olhar o material – que eu acredito estar bem auto-explicativo – você pode acessar meu github no link abaixo e estudar tudo o que foi feito. Além de poder explorar algumas bases interessantes! Continuar a ler “Gráficos em Python Usando Pyplot e Seaborn”
Categoria: Data mining
Trilha para Data Science em R (Springer)
Como vocês já sabem, a Springer disponibilizou diversos livros gratuitos. Dentre eles, há vários que podem ser utilizados para aprender mais sobre Ciência de Dados (separei alguns no post Livros da Springer – Gratuitos). Aqui, separei uma trilha de Data Science em R somente utilizando os livros disponibilizados por eles: Continuar a ler “Trilha para Data Science em R (Springer)”
Quer ver um cientista de dados trabalhando ao vivo?
Claro que não, ninguém quer. Mas cola na live mesmo assim, rola uns códigos legais, você vai aprender Python, R, Machine Learning e coisas do tipo. Tudo isso ao som de uns traps maneiros. É só clicar no link abaixo e se inscrever que você vai saber quando rola as lives. Eu também costumo anunciar no Twitter do Estatsite, o @EstatSite: Continuar a ler “Quer ver um cientista de dados trabalhando ao vivo?”
Python, R ou SAS? Meus 2 centavos sobre esse debate!
Eu não costumo dar muitos pitacos sobre a discussão R ou Python. Na verdade, tem vezes que falo, mas é sempre falando que não importa. Recentemente, solicitaram minha resposta no Quora e resolvi atender ao pedido. Segue minha resposta. Continuar a ler “Python, R ou SAS? Meus 2 centavos sobre esse debate!”
Como Big Data Explica Freud?
Freud é um nome muito conhecido. Mais comum para filósofos e psicólogos, ele aparece constantemente em papos não-acadêmicos. Mesmo conhecido por todos, explicar suas ideias é algo mais complicado. Suas teorias sempre foram muito intrigantes, capazes de gerar muitas dúvidas e ceticismo. Costumeiramente, mexe com algo mais profundo e, por vezes, intangível. Tanto é que subconsciência é uma palavra que aparece quase sempre que se fala de suas principais teorias. Bem, mas se suas ideias são baseadas em coisas que não estão na nossa consciência, cabe a nós aceitá-las e ponto final. Não tem como provar que elas são falsas ou verdadeiras, certo? Ou será que tem? Continuar a ler “Como Big Data Explica Freud?”
Tipos de Data Analytics

Tweet de Ronald van Loon
Charada de SQL
Esse é um tipo de “pegadinha” comum em entrevistas e que mesmo no dia a dia confunde algumas pessoas na hora de tratar os dados. Seja para surpreender o entrevistador ou para resolver rápido os problemas, você precisa ter a resposta na ponta da língua.
Técnicas de Clustering: K-Means
O que é clustering?
Imagine o dono de uma loja com todo o histórico do que seus clientes compraram. Esse histórico permite que o lojista procure o tipo de produto que o cliente pode se interessar. Porém, fazer isto para cada cliente individualmente não é muito eficiente. Seria mais prático ele separar os clientes por grupos de acordo com a semelhança entre as preferências desses clientes. Assim, ele terá que pensar na recomendação para cada grupo, sendo que o número de grupos seria muito menor que o número de indivíduos.
Sendo assim, o que o lojista precisaria fazer era pensar em como separar os indivíduos, pensando no número de grupos que quer formar e qual critério de separação. Isso pode ser feito através de técnicas de clustering. (traduzido e adaptado de: K-means Clustering Tutorial)
Clustering é o método separar seus dados em grupos (clusters) quando estamos minerando dados. Ou seja, nada mais é do que unir indivíduos de sua base de dados com base em suas semelhanças.
Um algoritmo bastante utilizado é o k-means (traduzido por alguns como k-médias). Este algoritmo serve para agrupar os dados em grupos com base nas distâncias à média.
Vejamos um exemplo para facilitar o entendimento:
Queremos aplicar o k-means nos indivíduos 1,2,3,4,5,6,7,8,9 e 10, que possuem determinados valores em duas variáveis quaisquer X e Y:
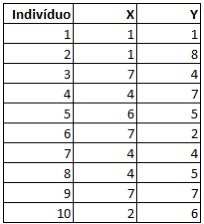
Para a utilizar o algoritmo precisamos escolher o número de grupos que queremos utilizar.
Para facilitar, no nosso exemplo iremos agrupar em dois grupos.
Iniciamos com um grupo contendo o elemento 1 e um outro grupo contendo o elemento 9.

Agora vamos alocar os elementos mais próximos de cada grupo de acordo com a distância entre os pontos. Por exemplo, note que a distância do indivíduo 4 é 6,7 para o Grupo 1, enquanto a distância ao Grupo 2 é 1,4. Logo, ele deve pertencer ao Grupo 2.
Fazemos a mesma comparação para os demais elementos e chegamos a essa divisão:

Note que as médias de cada grupo se alterou. Podemos então reagrupar os elementos, novamente através da distância às médias.
Por exemplo, a distância do indivíduo 4 em relação ao Grupo 1 agora é 3 e em relação ao Grupo 2 é de 3,7. Ou seja, ele agora está mais próximo do Grupo 1.
O mesmo deve ser feito para os demais elementos:

Esse processo é feito sucessivamente até que se encontre o melhor agrupamento, dado o critério de distância à média.
Dúvidas? Críticas? Deixe um comentário!