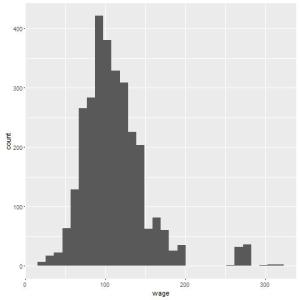
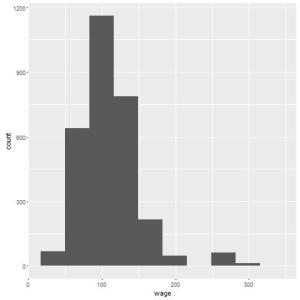
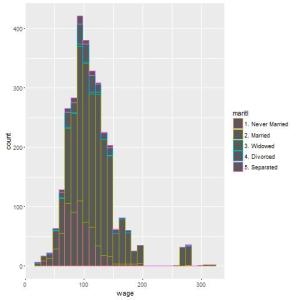
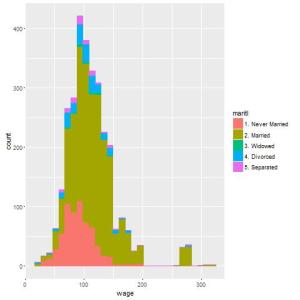
Recentemente tive que demonstrar graficamente algumas informações de dois grupos em um estudo. Isso é comum, principalmente porque normalmente analisamos os grupos de controle e tratamento.
No R, o pacote sm permite que façamos um gráfico com as densidades de dois grupos distintos para uma mesma variável de uma forma bem simples.
Para esta análise, o conjunto de dados sleep que temos no R será muito útil. Para quem não o conhece, basta acessar o R e escrever View(sleep). Este conjunto de dados contém informações de estudantes que receberam dois remédios distintos para dormir. Estes dois grupos são separados pela variável group. A coluna extra contém o número de horas a mais que o estudante dormiu após a ingestão da droga. Ou seja, se quisermos observar a distribuição do número de horas dormidas, pelos dois grupos em um mesmo gráfico, podemos utilizar exatamente o pacote sm e o gráfico de densidade separando estes dois grupos. Vamos construir este gráfico:
## instala e carrega pacote
install.packages("sm");
library("sm");
## carrega os dados de 'sleep'
attach(sleep);
## plota as densidades por cada grupo, com cores padrao 1 e 2
sm.density.compare(extra, group, xlab="Horas adicionadas ao sono",
col=c(1:2));
# adiciona titulo
title(main="Distribuicao da Idade por flag de Banco Cadastra");
## adiciona legenda no canto superior direito (topright)
legend("topright", levels(sleep$group),fill=c(1:2),
legend=c("Grupo 1","Grupo 2"))

Podemos fazer a mesma coisa para grupos maiores (3, 4, 5 ou até mais). Vejamos outro exemplo, dessa vez com os dados de mtcars, outro conjunto de dados que já está no R por default. Dessa vez, os dados são de diferentes automóveis e temos as informações de milhas por galão (mpg) e número de cilindros (cyl). Abaixo, veja como construímos os gráficos de densidade de mpg comparando os carros com 4, 6 e 8 cilindros:
## carrega os dados de 'mtcars'
attach(mtcars);
## plota as densidades por cada grupo
sm.density.compare(mpg, cyl, xlab="Milhas por galao",col=c(1:3));
# adiciona um titulo ao grafico
title(main="Distribuicao do consumo por n de cilindros");
## adiciona legenda para os dois grupos
legend("topright", levels(sleep$group),fill=c(1:3),
legend=c("4 cilindros","6 cilindros", "8 cilindros"));