Esse post bem que poderia ser uma continuação do Primeiros passos no R Studio, pois trataremos de algumas coisas que você vai fazer assim que abrir o R e iniciar seus trabalhos, como escolher o diretório em que você vai salvar as figuras ou carregar os dados, saber as dimensões do arquivo externo que você carregou, etc., é bem útil. É também um pouco repetitivo, já vimos algumas dessas funções separadamente, mas é bom reforçar para quem não viu outros links.
Etiqueta: analista de dados
Gráficos no R com qqplot() (Histograma, Gráficos de Dispersão e Boxplot)
A função qqplot() do R – pertencente ao pacote ggplot2 – é uma das melhores para se fazer gráficos. Este post, sem muitas enrolações, é basicamente uma continuidade do Gráficos em R. Aqui vamos utilizar os dados da base Wage do pacote ISLR do R.
Para começar, apenas carregue os pacotes e visualize a base:
library(ggplot2); library(ISLR); View(Wage);
Como você pode ver, se trata de dados referentes a salário, escolaridade, saúde, etc.
Abaixo, você terá os códigos para gerar diferentes gráficos e comentários explicativos:
## Tracando grafico simples com qplot ## por default, temos um histograma bem simples qplot(wage, data=Wage);
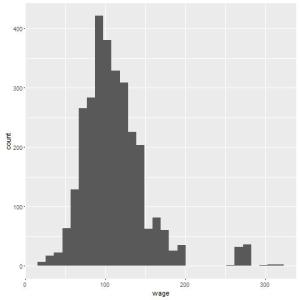
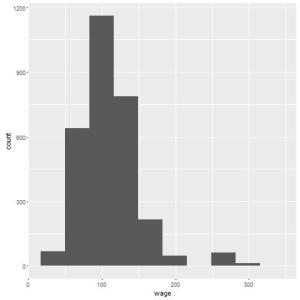
Você deve ter notado a mensagem: “`stat_bin()` using `bins = 30`. Pick better value with `binwidth`“. Isto quer dizer que por default, seu histograma é dividido em 30 barras diferentes, mas você pode escolher o melhor número de barras. Vamos testar com 15:
qplot(wage, data=Wage, bins=15);
## Agora, vamos visualizar cada barra separando pelo estado civil qplot(wage, colour=maritl, data=Wage);
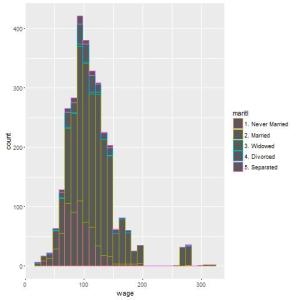
## Separar apenas com a cor do contorno nao ficou legal ## vamos trocar tambem a cor de preenchimento utilizando fill qplot(wage, colour=maritl, fill=maritl, data=Wage);
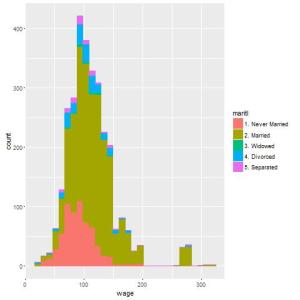
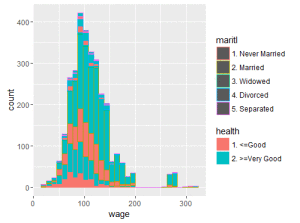
## Podemos inclusive preencher os blocos com cores diferentes ## Por exemplo, para cada estado civil, queremos ver quantos sao ## saudaveis e quantos nao sao qplot(wage, colour=maritl, fill=health, data=Wage);
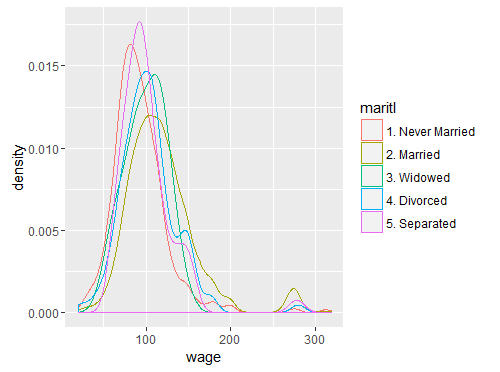
## Podemos visualizar graficos de densidade qplot(wage, colour=maritl, data=Wage, geom="density");
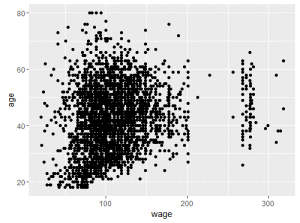
## Podemos tentar entender como duas variaveis interagem ## Exemplo: plotar salario vs idade qplot(wage, age, data=Wage);
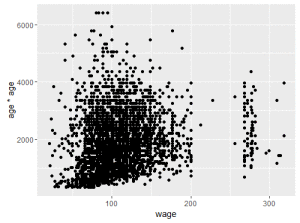
## Ou ate tentar ver alguma relacao nao linear qplot(wage, age*age, data=Wage);
## Um pouco mais complexo, podemos verificar o comportamento de idade por salario ## para cada raca, dividindo ainda por pessoas que possuem ou nao plano de saude ## essa segunda divisao (raca por plano de saúde) eh feita utilizando facets qplot(age, wage, data=Wage, facets=race~health_ins, xlab="Idade", ylab="Salario");
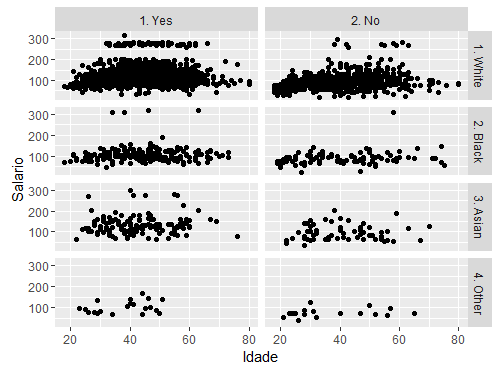
## Por fim, podemos fazer um boxplot, mas divindo uma variavel por
## cada uma das diferentes classes de uma outra (categorica)
## vamos observar o boxplot de salario para cada classe de trabalhador
## main indica o titulo do grafico, ylab o titulo do eixo y
qplot(jobclass, wage, data=Wage, geom=c("boxplot"),
fill=jobclass, main="Salario por classe de trabalho",
xlab="", ylab="Salario")
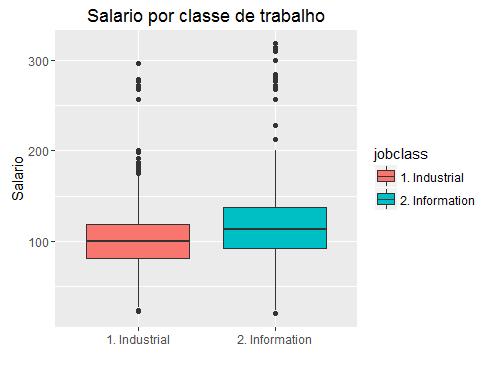
Agora você já está pronto para fazer diversos gráficos diferentes no R!
Demonstrando dados com a função aggregate no R
A função aggregate no R é bem interessante. Como o próprio nome diz, ela agrega as informações de um dataframe, incluindo alguma função que é especificada por um parâmetro chamado FUN. Sendo assim, é algo bem interessante para você analista ou cientista de dados! Continuar a ler “Demonstrando dados com a função aggregate no R”
R: Ordenando colunas
Mais uma dica rápida de R, vamos aprender a ordenar as colunas de um conjunto de dados qualquer. Isso geralmente é útil para visualizações, ou no caso de trabalhos com séries temporais.
Utilizando a base de dados german_credit_2, abaixo três formas de mudar as colunas de ordem:
## Le o dataset
dados = read.csv("../database/german_credit_2.csv");
## Traz a coluna 21 para a primeira posicao pelos indices
dados = dados[, c(21,1,2,3,...,20];
## Traz a coluna 21 para a primeira posicao pelos nomes das colunas
dados = dados[, c("Foreign Worker","Creditability",...,"Telephone")];
## Traz a coluna 21 pelos indices, mas criando uma sequencia
dados = dados[, c(21, 1:20)];
Para quem não se lembra, ‘1 : 20′ tem como resposta a sequência 1, 2, 3, …, 20.
Claro que o que foi criado acima pode ser modificado de diversas formas:
## Traz a coluna 21, 20 e 19 para a primeira posicao dados = dados[, c(21,20,19,1,2,3,...,18]; ## Traz as colunas de 1 a 5, seguidas pelas de 10 a 20, deixando ## as demais fora dados = dados[, c(1:5, 10:20)];
E aí, curtiu o post?
E aí? Gostou do conteúdo? Se inscreva para receber todas as novidades. Deixe seu e-mail em INSCREVA-SE na barra à direita, logo abaixo de pesquisar. E, por favor, não deixe de comentar, dar seu feedback e, principalmente, compartilhar com seus amigos. De verdade, isso faz toda a diferença. Além disso, você também pode acompanhar mais do meu trabalho seguindo a conta de Twitter @UniDosDados, no Instagram @universidadedosdados ou por alguma das redes que você encontra em Sobre o Estatsite / Contato, como meu canal de Youtube Canal Universidade dos Dados.
Aproveite e adquira sua camiseta de data science na LOJA DA UNIVERSIDADE DOS DADOS. Vai ficar estiloso e me ajudar neste projeto!
BONS ESTUDOS!
Excluindo linhas de um dataset no R
Mais uma dica rápida que saiu enquanto eu fazia minha tese…
Estava tratando um conjunto de dados no R, quando vi que precisava excluir as linhas que tivessem o campo referente ao mês com valor igual a 1 ou igual a 5. Sempre fiz isso no SAS com um if bem simples, mas não lembrava no R, talvez já tenha feito aqui, mas quem lê o blog sabe que não é lá tão organizado. Enfim, a lógica no R é tão simples quanto a do SAS, mas não tão intuitiva (ao menos para mim). Veja o antes e depois de uma tabela chamada dados retirando as linhas nas quais o campo mês seja igual a 1 ou 5 e quais os códigos utilizar em algumas linguagens que já mencionamos aqui (é tão simples que vou colocar tudo junto mesmo):
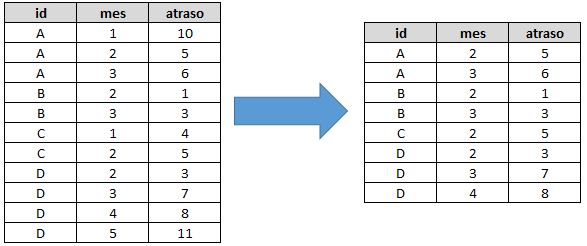
No R, podemos resolver com um indexador lógico (! indicando negação):
dados[(dados$mes!=5 & dados$mes!=1),];
Ou então com um subset:
subset(dados, mes != 1 & mes != 5)
Da forma que escrevemos acima, você vai obter uma nova tabela, mas ela não está sendo salva com nome algum. Se você quiser, pode facilmente criar uma nova, como a tabela_nova que criamos no exemplo a seguir:
tabela_nova = subset(dados, mes!=1 & mes !=5)
Se você quiser ver como é no SAS, aqui vai um exemplo com data step:
data dados_v2;
set dados;
if mes ne 1 and mes ne 5; *ou if mes <> 1;
run;
E agora, um exemplo com proc sql:
PROC SQL;
CREATE TABLE dados_v2 AS
SELECT * FROM dados WHERE mes <> 1 AND mes <> 5;
RUN;
Se quiser fazer no SQL:
SELECT * FROM dados WHERE mes <> 1 and mes <> 5;
E aí, curtiu o post?
E aí? Gostou do conteúdo? Se inscreva para receber todas as novidades. Deixe seu e-mail em INSCREVA-SE na barra à direita, logo abaixo de pesquisar. E, por favor, não deixe de comentar, dar seu feedback e, principalmente, compartilhar com seus amigos. De verdade, isso faz toda a diferença. Além disso, você também pode acompanhar mais do meu trabalho seguindo a conta de Twitter @UniDosDados, no Instagram @universidadedosdados ou por alguma das redes que você encontra em Sobre o Estatsite / Contato, como meu canal de Youtube Canal Universidade dos Dados.
Aproveite e adquira sua camiseta de data science na LOJA DA UNIVERSIDADE DOS DADOS. Vai ficar estiloso e me ajudar neste projeto!
BONS ESTUDOS!
Carregando / Importando seus dados no R
A função read.table() do R serve para importar arquivos de diversos formatos. O print abaixo apresenta a descrição do que a função é capaz de fazer e algumas variações dela, como o read.csv() – muito embora a própria read.table() seja capaz de ler arquivos csv.
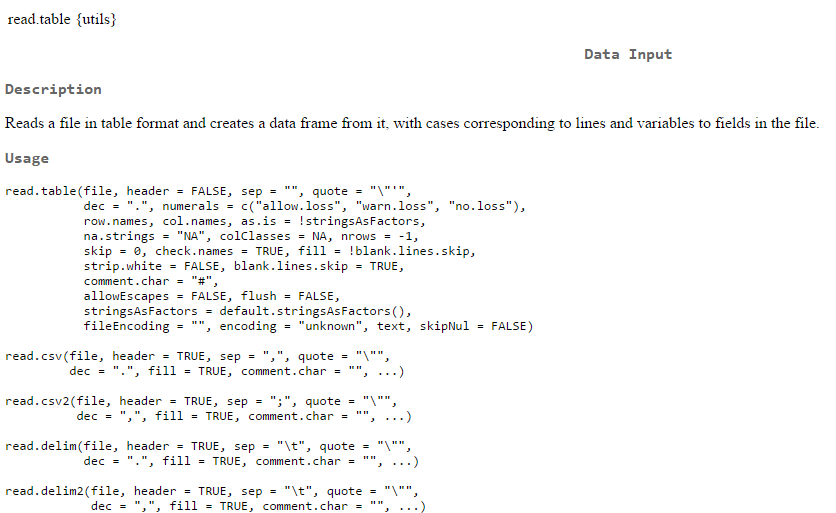
Não tem muito segredo para ler arquivos. Vejamos um exemplo de como ler um arquivo utilizando as principais especificações da função e vamos nomear o arquivo dados_exemplo:
dados_exemplo = read.table("C:/Users/Public/Desktop/tabela_exemplo.txt",header=TRUE,sep="\t",dec=",");
Item a item temos:
- diretório e nome do arquivo;
- header = TRUE indicando que meu arquivo tem cabeçalho. Se não tivesse, utilizaria header=FALSE;
- sep=”\t” para indicar separação por tabulações. Poderia ter utilizado sep=”;” ou sep=”,”;
- dec=”,” foi utilizado para indicar que os dados numéricos são separados por vírgula e não por ponto;
Após os dados serem importados você pode fazer pequenas manutenções (algumas poderiam ser feitas inclusive na hora de importar):
NOMEAR AS COLUNAS
colnames(dados_exemplo) = c("NomeDaColuna 1";"NomeDaColuna 2";"NomeDaColuna 3";"NomeDaColuna 4",...)
VISUALIZAR SEUS DADOS
## Para abrir a tabela de dados View(dados_exemplo) ## Para observar as primeiras linhas head(dados_exemplo) ## Para visualizar da primeira a décima linha, e da primeira a quinta coluna: dados_exemplo[1:10,1:5] ## Para visualizar a primeira linha da coluna 3 dados[1,"NomeDaColuna"]
ORDENAR SEUS DADOS
dados_exemplo=dados_exemplo[order(dados_exemplo[,"NomeDaColuna"],decreasing = TRUE),];
ou
dados_exemplo$NomeDaColuna = sort(dados_exemplo$NomeDaColuna ,decreasing = TRUE)
E aí, curtiu o post?
E aí? Gostou do conteúdo? Se inscreva para receber todas as novidades. Deixe seu e-mail em INSCREVA-SE na barra à direita, logo abaixo de pesquisar. E, por favor, não deixe de comentar, dar seu feedback e, principalmente, compartilhar com seus amigos. De verdade, isso faz toda a diferença. Além disso, você também pode acompanhar mais do meu trabalho seguindo a conta de Twitter @UniDosDados, no Instagram @universidadedosdados ou por alguma das redes que você encontra em Sobre o Estatsite / Contato, como meu canal de Youtube Canal Universidade dos Dados.
Aproveite e adquira sua camiseta de data science na LOJA DA UNIVERSIDADE DOS DADOS. Vai ficar estiloso e me ajudar neste projeto!
BONS ESTUDOS!