Hoje vamos aprender algumas coisas que podem ser feitas quando se trabalha com dataframes no Python. Como filtrar uma base? Como converter textos para números? Como extrair um valor de moeda no formato texto para o formato numérico? Como obter as estatísticas descritivas? Como criar novas colunas? Como traçar um histograma? Como localizar valores nulos e preenchê-los com a média da coluna? Tudo isso e muito mais no post abaixo! Continuar a ler “Tutorial: Limpeza e Análise de Dados com Python”
Etiqueta: média
Variáveis Aleatórias Contínuas
Dando continuidade aos posts sobre variáveis aleatórias (se você ainda não leu os demais, vá em Variáveis: Definição e Classificação e Variáveis Aleatórias Discretas), vamos falar agora das variáveis aleatórias contínuas. Vamos entender a definição destas variáveis, entender suas funções e como calcular o valor médio e a variância. Continuar a ler “Variáveis Aleatórias Contínuas”
Média por Grupo no R
Imagine que você tenha uma base contendo informações de diversos grupos ou categorias diferentes. Pode ser que você tenha a informação de idade para cada indivíduo e queira saber a média por sexo, por região ou até por separação de grupo tratamento e controle. No R, o pacote plyr facilita bastante esta análise. Não tenho certeza se já postei isso antes, mas como utilizei o código agora a pouco durante um curso de Data Science, acho válido compartilhar. Continuar a ler “Média por Grupo no R”
Introdução ao SQL
SQL (Structured Query Language) é a linguagem padrão utilizada para armazenar, manipular e recuperar informações de bancos de dados. Colocando de forma simples, é através do SQL que é possível criar e atualizar nossos dados através de um modelo relacional. Os maiores usuários da linguagem são os DBAs (Database Administrators), responsáveis por toda a gestão dos dados, desde criar tabelas até dar acesso às demais áreas (para os mais curiosos há um podcast brasileiro com foco nos DBAs chamado DatabaseCast).
Média Truncada (Trimmed Mean)
Já falei de estatística descritiva algumas vezes (como em Estatística Descritiva), mas nunca mencionei a média truncada, principalmente porque eu quase não uso.
A média truncada nada mais é do que a média desconsiderando algum percentil, o que a faz útil se você quer desconsiderar os outliers. Se você quiser calcular a média truncada de um conjunto de 10 observações, você vai retirar a primeira e a última observação, para depois calcular a média.
Por exemplo: Qual a média truncada de 10% de {1,2,2,2,2,2,2,2,2,10}?
Será (2+2+…+2)/8 = 2
E se quisermos calcular no R?
dados = c(1,2,2,2,2,2,2,2,2,10); mean(dados, trim=.1); [1] 2
Simples!
Demonstrando dados com a função aggregate no R
A função aggregate no R é bem interessante. Como o próprio nome diz, ela agrega as informações de um dataframe, incluindo alguma função que é especificada por um parâmetro chamado FUN. Sendo assim, é algo bem interessante para você analista ou cientista de dados! Continuar a ler “Demonstrando dados com a função aggregate no R”
Estatística Descritiva
Estatística descritiva, como o próprio nome já diz, é uma disciplina (ramo, técnica, etc.), que utilizamos para descrever dados de forma quantitativa.
Quando você está no excel e vai em análise de dados, você pode selecionar estatística descritiva e marcar a caixinha “resumo estatístico” para obter diversas informações a respeito dos seus dados. Farei aqui um breve resumo do que é cada uma das principais estatísticas fornecida pelo Excel.
Antes, vamos lembrar algumas definições básicas.
A média, mediana e moda, são chamadas de medidas de tendência central. Como o próprio nome diz, elas fazem referência ao centro da nossa distribuição. Ou seja, onde nossos dados estão centrados, qual o “meio” da nossa distribuição.
Em contrapartida, mediana, variância e desvio padrão são medidas de dispersão. Servem para mostrar o quanto nossos dados estão dispersos.
Por exemplo, suponha que a gente tenha duas cidades, A e B, com 10 moradores cada e com os seguintes salários:
Cidade A: $200, $200, $200, $200, $200, $200, $200, $200, $200, $200;
Cidade B: $10, $10, $10, $10, $10, $100, $100, $100, $100, $1550.
A média da cidade A e da cidade B é $200, mas o desvio padrão da cidade A é 0 e da cidade B é 451,99. Ou seja, os dados da cidade B estão bem mais dispersos. Podemos ver que os salários na cidade A são bem distribuídos, enquanto na cidade B há uma diferença significante entre os salários. Por esse motivo, é importante conhecermos tanto as medidas de tendência central, quanto as medidas de dispersão.
Vejamos agora as principais estatísticas fornecidas pelo Excel e o que significa cada uma:
- Média: Média aritmética da sua amostra, provavelmente a estatística mais conhecida e utilizada por todos, imagino que não precise de muita explicação. Nada mais é do que a soma das suas observações dividido pelo número de observações.
- Erro padrão: Estima a variabilidade de suas amostras, sua fórmula é o desvio padrão dividido pelo tamanho da amostra.
- Mediana: Valor que está no centro da sua amostra, metade dos valores está acima deste número e metade abaixo. Na cidade A a mediana é 200 e na cidade B é 55, pois (10+100)/2 = 55.
- Moda: Valor que aparece mais vezes nos seus dados. Na cidade A a moda é 200 e na cidade B é 10.
- Desvio padrão: Mede o quanto seus dados variam com relação a média.
- Variância: Essa medida vai te dar a dispersão dos seus dados com relação a média, mas em uma dimensão que será o quadrado da dimensão dos seus dados.
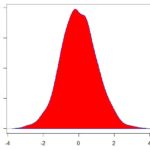
- Curtose: Também é uma medida para indicar a dispersão dos seus dados, mas nesse caso, a estatística nos dará o quão achatado é o gráfico da função de probabilidade dos nossos dados. Falaremos mais dessa medida em um post futuro, por enquanto, ficamos com a definição mais básica de que uma Curtose próxima de zero indica uma distribuição normal.
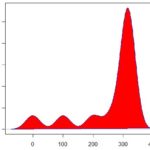
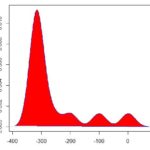
- Assimetria: Nos dá a simetria da distribuição dos nossos dados. Como assim? Bem, se você desenhar a curva de distribuição dos seus dados, você pode ter algo parecido com uma normal, uma curva um pouco mais concentrada a direita e caindo quando vai para a esquerda, ou o contrário. É isso que a essa medida do excel nos ajuda a entender. Uma distribuição simétrica, que tem o formato de um sino, terá assimetria igual a 0. No entanto, se a distribuição possuir uma maior concentração de dados a esquerda, o valor dessa estatística será negativo.